[置顶] 《从Lucene到Elasticsearch:全文检索实战》已出版!
2017-12-05 01:48
253 查看
一、前言
决定在CSDN写博客的原因是想把自己解决过的问题、踩过的坑、总结出来的经验记录下来,作为编程之路的“笔记本”,同时也能给遇到同样问题的人提供参考、节省时间,写书的初衷也一样。二、缘起
说一下写书的前因后果。中国科学院大学雁栖湖校区是很重要的一年,师资团队无可挑剔,每次上课去的稍微晚一点,300人的大教室都没有座位。对于计算机学院而言,大数据、机器学习、信息检索(搜索引擎)、算法、人工智能是最火的几个领域,信息检索课是最受欢迎的几门课之一。最后的工程大作业是实现一个新闻搜索,图1是我最早完成的效果。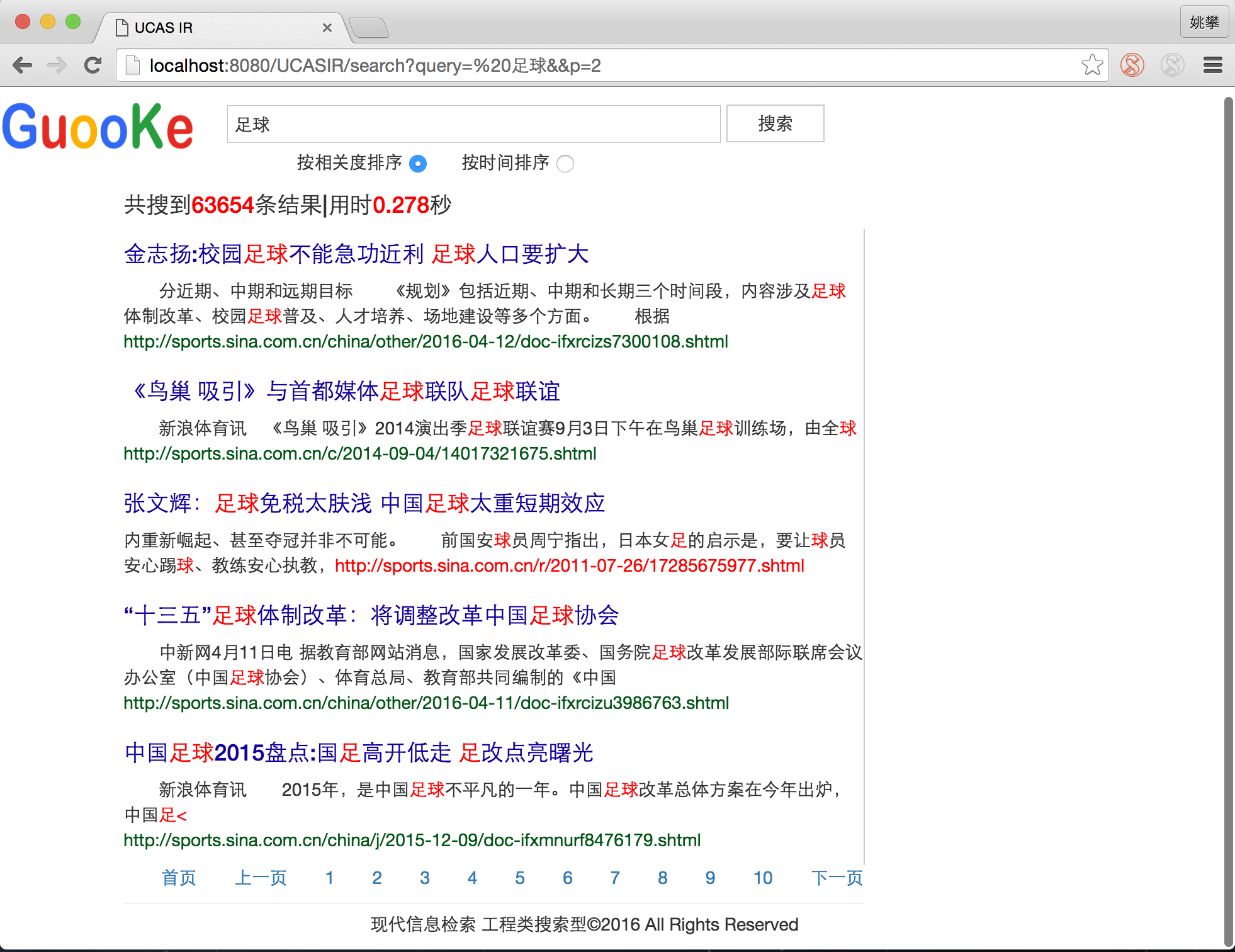
图1 基于Lucene的新闻搜索项目
后来,利用放暑假的时间,去找实习。也许是跟Elasticsearch有缘分,投的java实习生的岗位,做的是搜索的业务,也许我的简历上有Lucene这个小项目,Elasticsearch又是基于Lucene的,老大(中科大毕业的)给了我一份文档去学习Elasticsearch。这份文档是清华的一个学长做的Elasticsearch技术调研,其中很多基础性的东西都写在文档里了,有信息检索的理论、有Lucene基础,又有前辈总结的文档,上手Elasticsearch很快,业务中的大部分问题也都在短时间内得到了解决。当然,这期间也有遇到过很多问题,比如一开始对Elasticsearch中的一些概念不熟悉,理解起来比较困难,还有很多API不知道如何用,国内的相关文档也不太多,这期间我一直在Stack Overflow上和外国的大牛交流,不断的遇到问题、提问、解决问题、总结思考,如此反复,同时也把我解决过的问题贴到博客上面。就这样,博客积累的越来越多,对Elasticsearch、对搜索的体会也不断深入,同时公司里的老大、同事都给了我很多帮助和指导,进步也很快。
再后来,清华大学出版社的编辑通过博客联系到我,问我想不想写一本Elasticsearch的书,把技术分享出来。
三、创作
写书的过程跟我想的完全不一样,一开始以为博客上有那么多内容,整理整理很快书就完成了,事实上写书和写代码完全是两回事。写代码,明白需求,编写代码,解决问题,任务就完成了,而写书是写怎么写代码,要让读者看明白,同时整个书是一个体系,要有组织有路线,写作的过程要兼顾整体与部分。经过反复的思考,反复的修改,从理论到基础,从基础到项目实战,前前后后将近一年的时间完成了初稿。就在准备付梓之时,Elasticsearch 5.X发布了,而且变化比较大,又花了2个月的时间基于Elasticsearch 5.4把所有的内容更新了一遍。直到17年10月份,终于完稿!四、特色
信息检索的基本术语、核心算法。Lucene基础。
文件搜索项目。
Elasticsearch基础。
新闻搜索项目。
Elasticsearch和Hadoop的结合。
五、阅读指南
关于本书的阅读指南说明如下:第1章
第一章主要介绍信息检索的基本定义、术语、分词算法、倒排索引、布尔检索模型、向量空间模型、BM25概率检索模型。这一章的目的是为了让读者对信息检索有一个基本的认识,明白搜索是这么回事。关于检索模型,不论Lucene还是ELasticsearch,相关性评分是搜索要解决的问题,理解检索模型非常重要,我的建议是自己动手推导数学公式,从数学上理解算法,到后面再用Lucene或Elasticsearch就能游刃有余。第2章
第二章主要介绍怎么用Lucene,学习内容主要包括分词的实现、索引的构建、查询的用法以及关键字高亮。第3章
用Lucene仿照百度文库实现一个文件检索项目。如图2所示。第4章
Lucene和Elasticsearch的关系,Elasticsearch的诞生过程、流行度分析、架构、核心概念、和其它数据库的对比、安装与启动、中文分词器配置、常用插件配置。第5章
第5章主要有三块内容:索引管理、文档管理和映射详解。索引管理包括索引的增、删、改、查、开、关、复制、收缩、别名,文档管理包括文档的增、删、更新、获取、批量操作、版本机制和路由机制,映射详解主要包括映射的分类、动态映射和静态映射、字段类型、元字段、映射参数和映射模板。其中映射配置和使用是重点,遇到过多次因为日期类型的mapping设置有误,上亿的数据导到Elasticsearch之后需要翻工修改。每一个需要使用Elasticsearch的开发者,在动手之前,把mapping中的所有字段、原字段、参数等配置信息过一遍是最基本的要求。第6章
第6章主要介绍搜索机制、全文级别的查询、词项级别的查询、复合查询、嵌套查询、位置查询、特殊查询、搜索高亮的实现以及性能分析、搜索排序和评分的相关分析。第7章
第7章主要介绍指标聚合和桶聚合。指标聚合可以实现关系型数据库中的统计功能,比如常用的求和、最大/小值、平均数等,桶聚合可以实现关系型数据库中的分组功能,每个的功能都通过具体例子进行讲解。第8章
第8章介绍如何在Java项目中通过Java客户端做二次开发。Elasticsearch提供了多种客户端,包括Java、Javascript、Python、.NET、PHP、Ruby等常用语言,考虑到Lucene是纯java编写、基于java的项目比较多,这一章重点介绍如何使用java客户端基于Elasticsearch做二次开发。第9章
第9章介绍集群的规划、分片的规划、分布式集群的配置、集群健康的监控与查看以及常用的API。第10章
第10章讲解基于Elasticsearch整合Mysql实现新闻搜索项目,包括数据导入、 前端搜索框和搜索结果页、关键字高亮、搜索分页等关键步骤的实现。如图3和图4所示。第11章
第11章介绍ES-Hadoop,ES-Hadoop是连通分布式搜索引擎Elasticsearch和Hadoop大数据生态系统的桥梁。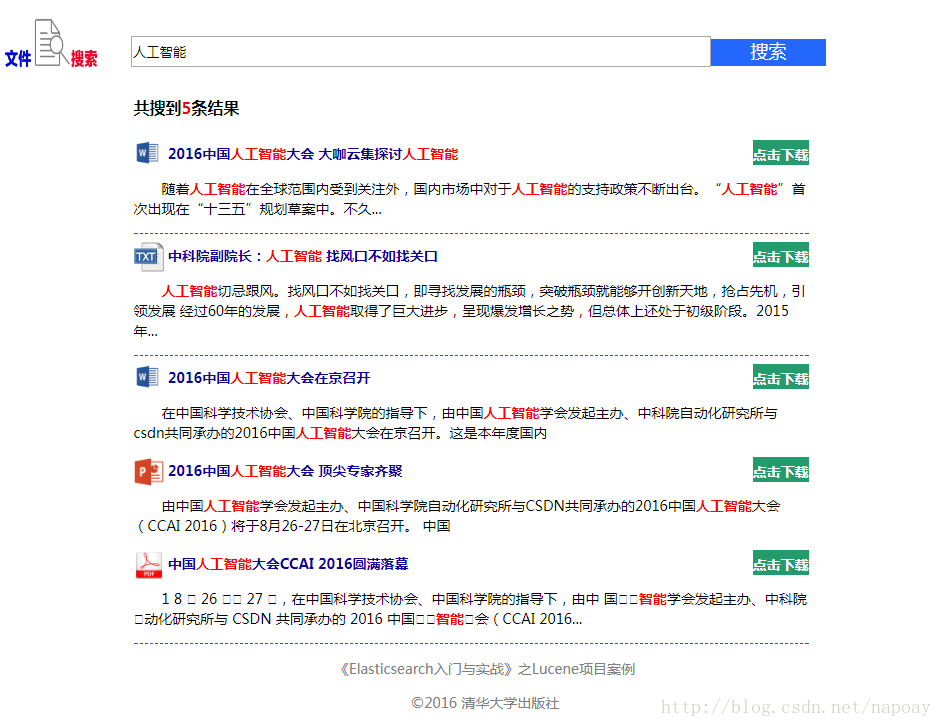
图2 基于Lucene的文件检索项目

图3 基于Elasticsearch的新闻搜索项目(搜索框)
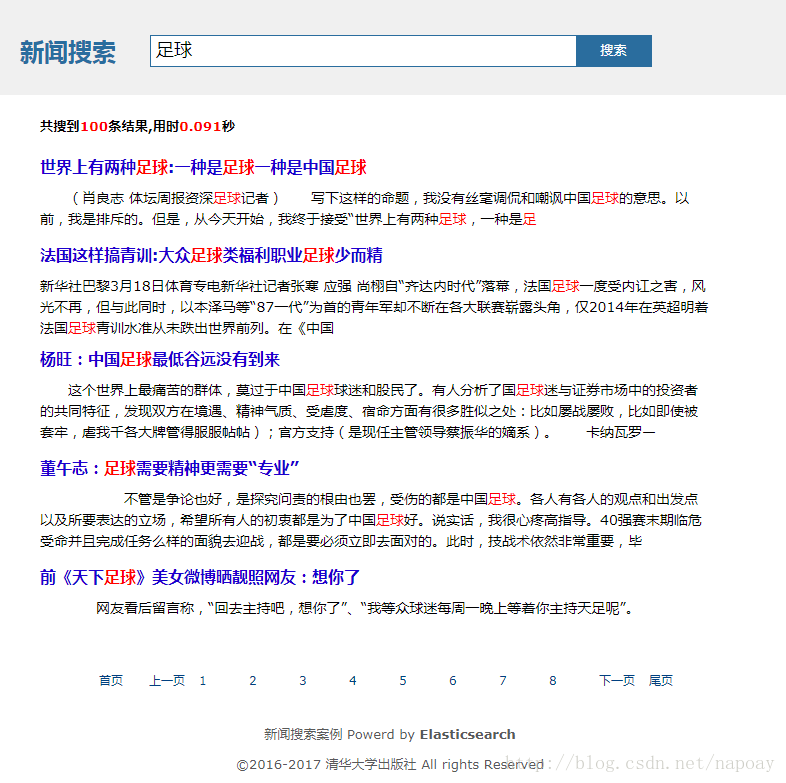
图4 基于Elasticsearch的新闻搜索项目(搜索结果页)
六、购书

天猫 当当 京东 亚马逊
七、勘误
囿于个人知识、能力、经验有限,欢迎读者对本书中的任何不足和疏漏之处进行批评指正,任何意见、建议都可以在本帖下回复。八、总结
我希望阅读本书的读者:对于数学理论,最好是能静下心,拿出纸笔,从数学公式上去推导;
对于Lucene基础,所有的代码都应该写一遍,例子都是环环相扣逐步深入的;
对于文件搜索项目,能够找一些格式不一样的文档,从0开始实现一个小的百度文库;
对于Elasticsearch,基本的安装、插件正确配置,所有的基础API都应亲自测一把;
对于新闻搜索项目,从0开始一步一步去实现一个小的百度新闻搜索;
对于ES-Hadoop,把Hadoop的安装配置好,例子运行起来。
这也是这本书所能给你的。
最后,图书的出版是技术路上的一个总结,希望本书能够帮助有需要的朋友。“三人行,必有我师”,我还会一如既往的努力,一如既往的和大家交流学习。


相关文章推荐
- 【Lucene】Apache Lucene全文检索引擎架构之入门实战
- 工作招聘网--Lucene(全文检索)实战
- Elasticsearch全文检索实战小结
- Elasticsearch全文检索实战小结——复盘我带的第二个项目
- 全文检索学习历程目录结构(Lucene、ElasticSearch)
- Elasticsearch实战——全文检索架构设计
- 【Lucene】Apache Lucene全文检索引擎架构之入门实战
- 【Lucene】Apache Lucene全文检索引擎架构之入门实战1
- 【Lucene】Apache Lucene全文检索引擎架构之构建索引
- Lucene全文检索基础
- Lucene:基于Java的全文检索引擎简介 笔记 by 车东
- lucene实现全文检索的示例代码
- 全文检索技术学习(二)——配置Lucene的开发环境
- lucene3.6全文检索word2007
- Lucene学习总结之一:全文检索的基本原理
- 全文检索(elasticsearch) 索引mapping的配置指南
- Lucene全文检索样例(解决大文本建索引)
- Lucene:基于Java的全文检索引擎简介
- 全文检索引擎 Lucene.net
- 【Lucene】Apache Lucene全文检索引擎架构之构建索引2