Hadoop-2.8.0集群搭建、hadoop源码编译和安装、host配置、ssh免密登录、hadoop配置文件中的参数配置参数总结、hadoop集群测试,安装过程中的常见错误
2017-05-29 02:11
1261 查看
25. 集群搭建
25.1 HADOOP集群搭建
25.1.1集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起HDFS集群:
负责海量数据的存储,集群中的角色主要有NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
25.1.2服务器准备
本案例使用虚拟机服务器来搭建HADOOP集群,所用软件及版本:ü Vmware 11.0
ü Centos 6.7 64bit
25.1.3网络环境准备
ü 采用NAT方式联网ü 网关地址:192.168.106.2
ü 3个服务器节点IP地址:192.168.106.80、192.168.106.81、192.168.106.82 (均为虚拟机)
ü 子网掩码:255.255.255.0
ü 注意防火墙关闭hadoop相关的一些端口
ü 需要下载hadoop2.8.0-src.tar.gz进行源码编译
针对自己Linux版本的hadoop-2.8.0.tar.gz的获取方式:http://blog.csdn.net/tototuzuoquan/article/details/72796632(本博文中还是使用官网提供的hadoop-2.8.0.tar.gz进行安装,然后安装过程的错误用自己编译的hadoop-2.8.0.tar.gz中的部分文件进行替换,注意的是下面的安装文件都是从网上下来的hadoop-2.8.0.tar.gz中的内容,唯独用到的紧紧是解压后的hadoop-2.8.0/lib/native,也就是说用编译出来的native替换从网上下载下来的:hadoop-2.8.0/lib/native)
25.1.4服务器系统设置
在整个集群部署过程中需要经过以下几个步骤:| 1、配置hosts文件,并设置ssh免密登录(ssh免密登录时必须的,因为在hadoop中需要用到) 2、建立hadoop运行帐号 3、下载并解压hadoop安装包,并在安装前装好JDK 4、配置namenode,修改site文件 5、配置hadoop-env.sh文件 6、 配置masters和slaves文件(Linux下的Hadoop的集群安装,也相当于是主从的集群) 7、向各节点复制hadoop 8、格式化namenode 9、启动hadoop 10、用jps检验各后台进程是否成功启动 11、通过网站查看集群情况 |
| [root@hadoop1 zookeeper]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.106.80 hadoop 192.168.106.81 hadoop2 192.168.106.82 hadoop3 [root@hadoop1 zookeeper]# |
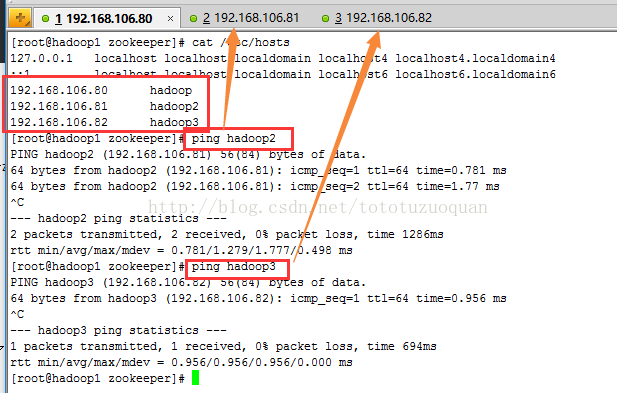
设置后的状态为:
ü 设置主机名
n hadoop
n hadoop2
n hadoop3
ü 配置内网域名映射:
n 192.168.106.80 hadoop
n 192.168.106.81 hadoop2
n 192.168.106.82 hadoop3
配置ssh免密登录(可以參考的网址是:http://blog.csdn.net/ab198604/article/details/8250461),每个节点要分别产生公私密钥,参考命令如下:
| 1) [toto@hadoop hadoop-2.8.0]$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa Generating public/private dsa key pair. Your identification has been saved in /home/toto/.ssh/id_dsa. Your public key has been saved in /home/toto/.ssh/id_dsa.pub. The key fingerprint is: 33:9d:e6:a4:a4:99:5a:af:e2:b6:46:ac:59:a8:41:10 toto@hadoop The key's randomart image is: +--[ DSA 1024]----+ |E. | |. | |. | | . . . | |. o S = | |. . + = B | | o = = . . | |. o +o . | | ++o... | +-----------------+ (注意:如果执行上面的命令出现open /home/toto/.ssh/id_dsa failed: Permission denied.,则用root用户执行:[root@hadoop1 ~]# chmod 777 /home/toto/.ssh) 以上是产生公私密钥,产生目录在用户主目录下的.ssh目录中,如下: [toto@hadoop hadoop-2.8.0]$ cd /home/toto/.ssh [toto@hadoop .ssh]$ ls id_dsa id_dsa.pub known_hosts [toto@hadoop .ssh]$ 其中id_dsa.pub为私钥,id_dsa为私钥,紧接着将公钥文件复制成authorized_keys文件,这个步骤是必须的,过程如下: [toto@hadoop .ssh]$ cat id_dsa.pub >> authorized_keys [toto@hadoop .ssh]$ ls authorized_keys id_dsa id_dsa.pub known_hosts 2):单机回环ssh免密码登陆测试 即在单机节点上用ssh进行登录,看看是否能够登陆成功。登陆成功后注销退出,过程如下: [toto@hadoop .ssh]$ ssh localhost The authenticity of host 'localhost (::1)' can't be established. RSA key fingerprint is 23:da:24:9c:b9:82:fa:f2:52:3c:30:2c:98:1e:4a:d7. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'localhost' (RSA) to the list of known hosts. [toto@hadoop ~]$ ssh Hadoop (如果是hadoop2,hadoop3这里分别写成这两个名字即可) Last login: Sun May 28 19:47:27 2017 from localhost 有以上信息表示操作成功,这将为后续跨子节点ssh远程免密登录做好准备。用上述同样的方法在剩下的两个节点如法炮制即可。 3) 让主结点hadoop(master)能够通过ssh免密登录两个子节点hadoop1,hadoop2(slave) 为了实现这个功能,两个slave节点的公钥文件中必须包含主结点的公钥信息,这样当master就可以顺利安全地当问两个slave结点了,操作过程如下: [toto@hadoop2 ~]$ cd ~/.ssh/ [toto@hadoop2 .ssh]$ ls authorized_keys id_dsa id_dsa.pub known_hosts [toto@hadoop2 .ssh]$ scp toto@hadoop:~/.ssh/id_dsa.pub ./master_dsa.pub The authenticity of host 'hadoop (192.168.106.80)' can't be established. RSA key fingerprint is 23:da:24:9c:b9:82:fa:f2:52:3c:30:2c:98:1e:4a:d7. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'hadoop,192.168.106.80' (RSA) to the list of known hosts. toto@hadoop's password: 这里输入123456 Permission denied, please try again. toto@hadoop's password: 这里输入123456 id_dsa.pub 100% 601 0.6KB/s 00:00 [toto@hadoop2 .ssh]$ ls authorized_keys id_dsa id_dsa.pub known_hosts master_dsa.pub [toto@hadoop2 .ssh]$ cat master_dsa.pub >> authorized_keys [toto@hadoop2 .ssh]$ 说明:如上过程显示了hadoop2结点通过scp命令远程登录master结点,并复制master的公钥到当前的目录下,这一过程需要密码验证。接着,将master结点的公钥文件追加至authorized_keys文件中,通过这步骤,如果不出现问题,master结点就可以通过ssh远程密码连接hadoop2结点了。在master(hadoop)结点中操作如下: [toto@hadoop .ssh] cd ~/.ssh/ (一定要在这个目录下进行才可以) [toto@hadoop .ssh]$ ssh hadoop2 (如果是进入hadoop配置hadoop3,这里写成:ssh hadoop3) The authenticity of host 'hadoop2 (192.168.106.81)' can't be established. RSA key fingerprint is 23:da:24:9c:b9:82:fa:f2:52:3c:30:2c:98:1e:4a:d7. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'hadoop2,192.168.106.81' (RSA) to the list of known hosts. Last login: Sun May 28 19:58:56 2017 from hadoop2 [toto@hadoop2 ~]$ exit logout Connection to hadoop2 closed. [toto@hadoop .ssh]$ ssh hadoop2 Last login: Sun May 28 20:12:06 2017 from hadoop [toto@hadoop2 ~]$ 由上图可以看出,node1结点首次连接时需要”YES”确认连接,这意味着master结点连接hadoop2(slave)结点时需要人工询问,无法自动连接,输入yes后成功接入,紧接着注销退出至master(hadoop)结点。要实现ssh免密码连接至其它结点,还差一步,只需执行ssh hadoop2,如果没有要求你输入”yes”,就算成功了,上述过程已经演示过。 4):进入hadoop3,执行3)这样步骤 [toto@hadoop3 ~]$ cd ~/.ssh/ [toto@hadoop3 .ssh]$ ls authorized_keys id_dsa id_dsa.pub known_hosts [toto@hadoop3 .ssh]$ scp toto@hadoop:~/.ssh/id_dsa.pub ./master_dsa.pub The authenticity of host 'hadoop (192.168.106.80)' can't be established. RSA key fingerprint is 23:da:24:9c:b9:82:fa:f2:52:3c:30:2c:98:1e:4a:d7. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'hadoop,192.168.106.80' (RSA) to the list of known hosts. toto@hadoop's password: id_dsa.pub 100% 601 0.6KB/s 00:00 [toto@hadoop3 .ssh]$ ls authorized_keys id_dsa id_dsa.pub known_hosts master_dsa.pub [toto@hadoop3 .ssh]$ cat master_dsa.pub >> authorized_keys [toto@hadoop3 .ssh]$ 进入hadoop机器,登录hadoop3 [toto@hadoop .ssh]$ ssh hadoop3 The authenticity of host 'hadoop2 (192.168.106.81)' can't be established. RSA key fingerprint is 23:da:24:9c:b9:82:fa:f2:52:3c:30:2c:98:1e:4a:d7. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'hadoop2,192.168.106.81' (RSA) to the list of known hosts. Last login: Sun May 28 19:58:56 2017 from hadoop2 [toto@hadoop3 ~]$ exit logout Connection to hadoop3 closed. [toto@hadoop .ssh]$ ssh hadoop3 Last login: Sun May 28 20:12:06 2017 from hadoop [toto@hadoop3 ~]$ 经过上述过程,可以通过hadoop免密登录hadoop2,hadoop3了。 表面上看,这两个节点的ssh免密登录已经配置成功,但是我们还需要对主结点master也要进行上面的同样工作,具体原因现在也说不太好,据说是真实物理节点时需要做这项工作,因为jobtracker有可能会分布在其它的结点上,jobtracker有不存在master结点上可能性。 [toto@hadoop root]$cd ~/.ssh/ [toto@hadoop .ssh]$ ls authorized_keys id_dsa id_dsa.pub known_hosts [toto@hadoop .ssh]$ scp toto@hadoop:~/.ssh/id_dsa.pub ./master_dsa.pub id_dsa.pub 100% 601 0.6KB/s 00:00 [toto@hadoop .ssh]$ ls authorized_keys id_dsa id_dsa.pub known_hosts master_dsa.pub [toto@hadoop .ssh]$ cat master_dsa.pub >> authorized_keys [toto@hadoop .ssh]$ ssh hadoop Last login: Sun May 28 19:59:13 2017 from hadoop [toto@hadoop ~]$ |
| [root@hadoop1 zookeeper]# groupadd hadoop //设置hadoop用户组 groupadd: group 'hadoop' already exists //添加一个toto用户,此用户属于hadoop组,并且拥有root的权限 [root@hadoop1 zookeeper]# useradd -s /bin/bash -d /home/toto -m toto -g hadoop -G root [root@hadoop1 zookeeper]# passwd toto 更改用户 toto 的密码。 新的密码: (假设这里的密码为123456) 无效的密码:过于简单化/系统化 (假设这里的密码为123456) 无效的密码:过于简单 重新输入新的密码: passwd:所有的身份验证令牌已经成功更新。 [root@hadoop1 zookeeper]# su toto (切换到toto用户) [toto@hadoop1 zookeeper] 进入/home,ls以下,发现已经有了一个叫toto的用户对应的文件夹 [toto@hadoop1 home]$ pwd /home [toto@hadoop1 home]$ ls hadoop lost+found mysql test tom toto tuzq [toto@hadoop1 home]$ 上述3个虚机结点均需要进行以上步骤来完成hadoop运行帐号的建立。 |
ü 上传jdk安装包,安装jdk包,这里默认安装是jdk1.8.0_73
ü 规划安装目录 /usr/local/java/jdk1.8.0_73
ü 解压安装包
ü 配置环境变量/etc/profile 然后source /etc/profile
可以看一下配置的/etc/profile的信息:
| export JAVA_HOME=/usr/local/java/jdk1.8.0_73 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export ZOOKEEPER_HOME=/home/tuzq/software/zookeeper export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin |
sync
echo 3 > /proc/sys/vm/drop_caches
25.1.6 HADOOP安装部署
可供参考的网址:http://hadoop.apache.org/docs/r1.0.4/cn/cluster_setup.html(里面介绍了各种参数配置的含义)参考网址2:http://blog.csdn.net/ab198604/article/details/8250461(这里是网上的安装配置方式)
经过以上步骤,准备工作已经完成了,下面开始修改hadoop的配置文件。
ü 下载最新的hadoop-2.8.0.tar.gz,下载地址:http://hadoop.apache.org/releases.html#Download
ü 上传HADOOP安装包,上传位置:
| [toto@hadoop1 software]$ pwd /home/toto/software [toto@hadoop1 software]$ ls hadoop-2.8.0.tar.gz [toto@hadoop1 software]$ |
ü 解压安装包 tar -zxvf hadoop-2.8.0.tar.gz
ü 修改配置文件 $HADOOP_HOME/etc/hadoop/
最简化配置如下:
[toto@hadoop2 hadoop]$ cd /home/toto/software/hadoop-2.8.0/etc/hadoop
vim hadoop-env.sh
| # The java implementation to use. export JAVA_HOME=/usr/local/java/jdk1.8.0_73 |
| <configuration> <!—指定namenode的地址--> <property> <name>fs.defaultFS</name> <!—查看namenode,可以在浏览器上进行查看,下面配置的浏览器的url地址,注意下面的红字表示的是80机器的,hadoop2表示81机器的,hadoop3表示的是机器82的--> <value>hdfs://hadoop:9000</value> </property> <!—用来指定使用hadoop时产生的存放目录--> <property> <name>hadoop.tmp.dir</name> <value>/home/toto/software/hadoop-2.8.0/tmp</value> </property> </configuration> |
A: fs.default.name是NameNode的URI。hdfs://主机名:端口/
B: hadoop.tmp.dir:Hadoop的默认临时路径,这个最好配置,如果在新增节点或者其它情况下莫名其妙的DataNode启动不了,就删除此文件中的tmp目录即可。不过如果删除了NameNode机器的此目录,那么就需要重新执行NameNode格式的命令。
vim hdfs-site.xml
| <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <!-- 指定namenode镜像文件存放的目录,namenode存储数据信息,在内存里面,但 是不能一直存在内存里面。如果不指定则默认为core-site中配置的tmp目录 --> <name>dfs.namenode.name.dir</name> <value>/home/toto/software/hadoop-2.8.0/data/name</value> </property> <!-- namenode配置多个目录和datanode配置多个目录,datenode中的数据主要是 用户上传的文件的block块,如果不写默认为core-site中配置的tmp目录 --> <property> <name>dfs.datanode.data.dir</name> <value>/home/toto/software/hadoop-2.8.0/data/data</value> </property> <!--指定hdfs保存数据的副本数量--> <property> <name>dfs.replication</name> <value>3</value> </property> <!--SNN的web访问地址--> <property> <name>dfs.secondary.http.address</name> <value>hadoop:50090</value> </property> <!--是否需要角色权限验证,上传文件时会用到,如果为true,需要绑定hadoop用户角色--> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration> |
A: dfs.name.dir是NameNode持久存储名字空间及事务日志的本地文件系统路径。当这个值是一个逗号分割的目录列表时,nametable数据将会被复制到所有目录中做冗余备份。
B: dfs.data.dir是DataNode存放块数据的本地文件系统路径,逗号分割的列表。当这个值是逗号分割的目录列表时,数据将被存储在所有目录下,通常分布在不同设备上。
C: dfs.replication是数据需要备份的数量,默认是3,如果此数大于集群的机器数会出错。
注意:上面的目录不需要手动创建,hadoop格式化时会自动创建,如果预先创建反而会有问题。
vi mapred-site.xml告诉是运行在哪个资源调度平台上的,下面的意思是指定yarn为运算资源调度平台,注意在hadoop的包中,它的名字叫做:mapred-site.xml.template,最后要将名字改成mapred-site.xml
[toto@hadoop1 hadoop]$ pwd
/home/toto/software/hadoop-2.8.0/etc/Hadoop
[toto@hadoop1 hadoop]$ mvmapred-site.xml.template mapred-site.xml
| <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> |
| <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop</value> </property> <!—yarn中的nodemanager是否要提供一些辅助的服务 -à <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> |
| hadoop hadoop2 hadoop3 |
| [toto@hadoop software]$ cd /home/toto/software [toto@hadoop software]$ scp -r /home/toto/software/hadoop-2.8.0 toto@hadoop2:/home/toto/software [toto@hadoop software]$ scp -r /home/toto/software/hadoop-2.8.0 toto@hadoop3:/home/toto/software |
25.1.7 启动集群
注意,下面的命令都是在hadoop机器下执行的,hadoop可以免密访问hadoop2,hadoop3初始化HDFS,要先初始化namenode的工作目录(第一次使用的时候要进行的工作,注意这个工作是在hadoop这台机器上进行的)
| [toto@hadoop1 hadoop-2.8.0]$ cd /home/toto/software/hadoop-2.8.0 [toto@hadoop1 hadoop-2.8.0]$ bin/hadoop namenode -format |

启动HDFS (注意:一定要在hadoop机器下,因为hadoop可以免密访问hadoop2,hadoop3)
| [toto@hadoop hadoop-2.8.0]$ sbin/start-dfs.sh 17/05/28 21:25:07 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [hadoop] hadoop: starting namenode, logging to /home/toto/software/hadoop-2.8.0/logs/hadoop-toto-namenode-hadoop.out hadoop: starting datanode, logging to /home/toto/software/hadoop-2.8.0/logs/hadoop-toto-datanode-hadoop.out hadoop3: starting datanode, logging to /home/toto/software/hadoop-2.8.0/logs/hadoop-toto-datanode-hadoop3.out hadoop2: starting datanode, logging to /home/toto/software/hadoop-2.8.0/logs/hadoop-toto-datanode-hadoop2.out Starting secondary namenodes [hadoop] hadoop: starting secondarynamenode, logging to /home/toto/software/hadoop-2.8.0/logs/hadoop-toto-secondarynamenode-hadoop.out 17/05/28 21:25:43 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [toto@hadoop hadoop-2.8.0]$ 注意:上图出现了下面这个错误(同样因为这个错误,还会导致后续的一些东西错误,解决办法是用源码编译生成的hadoop-2.8.0/lib/native替换直接从网络上下载的hadoop-2.8.0/lib/native): 17/05/28 21:25:07 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [hadoop] |
启动YARN
| [toto@hadoop hadoop-2.8.0]$ sbin/start-yarn.sh starting yarn daemons starting resourcemanager, logging to /home/toto/software/hadoop-2.8.0/logs/yarn-toto-resourcemanager-hadoop.out hadoop: starting nodemanager, logging to /home/toto/software/hadoop-2.8.0/logs/yarn-toto-nodemanager-hadoop.out hadoop3: starting nodemanager, logging to /home/toto/software/hadoop-2.8.0/logs/yarn-toto-nodemanager-hadoop3.out hadoop2: starting nodemanager, logging to /home/toto/software/hadoop-2.8.0/logs/yarn-toto-nodemanager-hadoop2.out [toto@hadoop hadoop-2.8.0]$ |
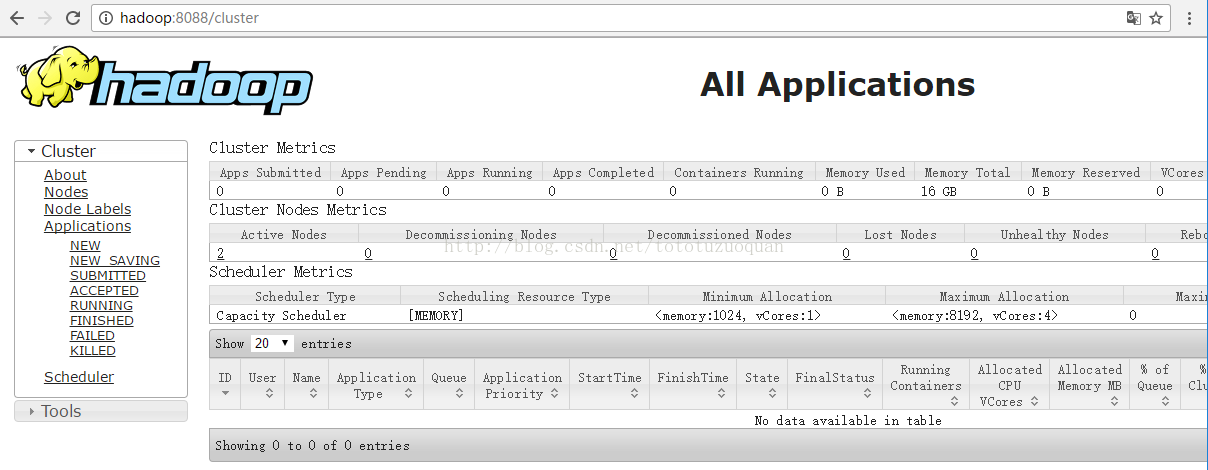
注意,如果想要启动namenode,访问地址是:
| [toto@hadoop sbin]$ cd /home/toto/software/hadoop-2.8.0/sbin [toto@hadoop sbin]$ ./hadoop-daemon.sh start namenode namenode running as process 3874. Stop it first. [toto@hadoop sbin]$ jps (通过这个命令查看启动了哪些进程) 4607 NodeManager 4498 ResourceManager 5774 Jps 4278 SecondaryNameNode 3874 NameNode [toto@hadoop sbin]$ |
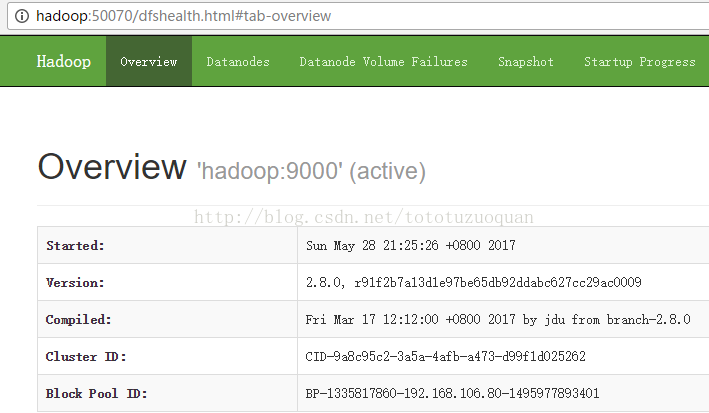
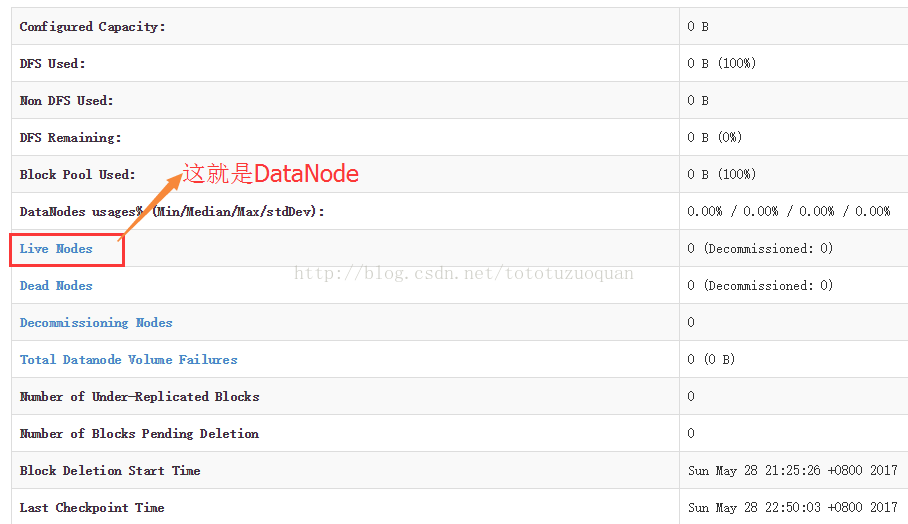
配置HADOOP的环境变量,进入root用户,编辑/etc/profile命令
vim/etc/profile
| export JAVA_HOME=/usr/local/java/jdk1.8.0_73 export HADOOP_HOME=/home/toto/software/hadoop-2.8.0 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export ZOOKEEPER_HOME=/home/tuzq/software/zookeeper export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin |
source/etc/profile
25.1.8 测试
1、上传文件到HDFS
假设在/home/toto/software有:apache-hive-2.0.0-bin.tar.gz,将apache-hive-2.0.0-bin.tar.gz上传到hdfs下的/hive目录下,创建方式是:| [toto@hadoop software]$ hadoop fs -mkdir -p /hive 创建完成后的效果如下: 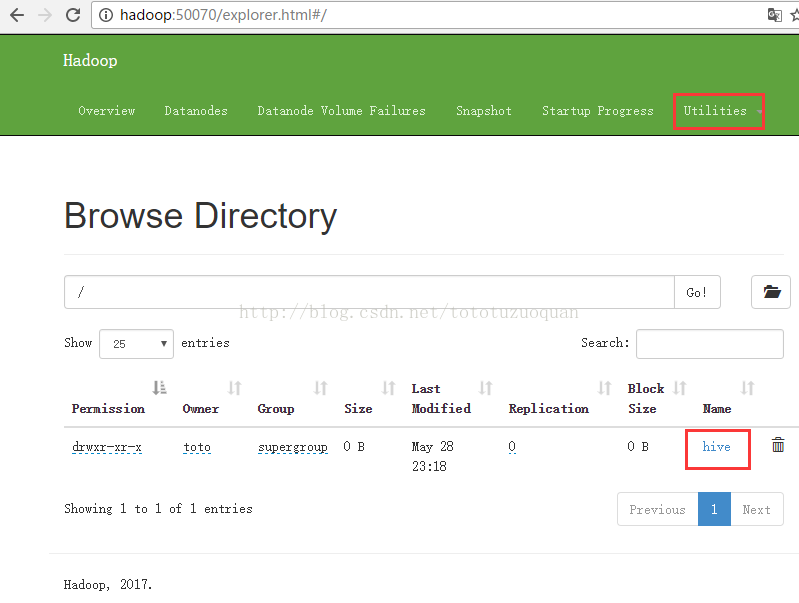 然后上传一个文件到hive里面,操作方式如下: [toto@hadoop software]$ cd /home/tuzq/software [toto@hadoop software]$ ls apache-hive-2.0.0-bin.tar.gz findbugs-1.3.9 hadoop-2.8.0 hadoop-2.8.0-src hadoop-2.8.0.tar.gz repo apache-maven-3.3.9 hadoop-2.6.4 hadoop-2.8.0-latest-by-src hadoop-2.8.0-src.tar.gz protobuf-2.5.0 [toto@hadoop software]$ hadoop fs -put apache-hive-2.0.0-bin.tar.gz /hive 再次刷新http://hadoop:50070/explorer.html#/ 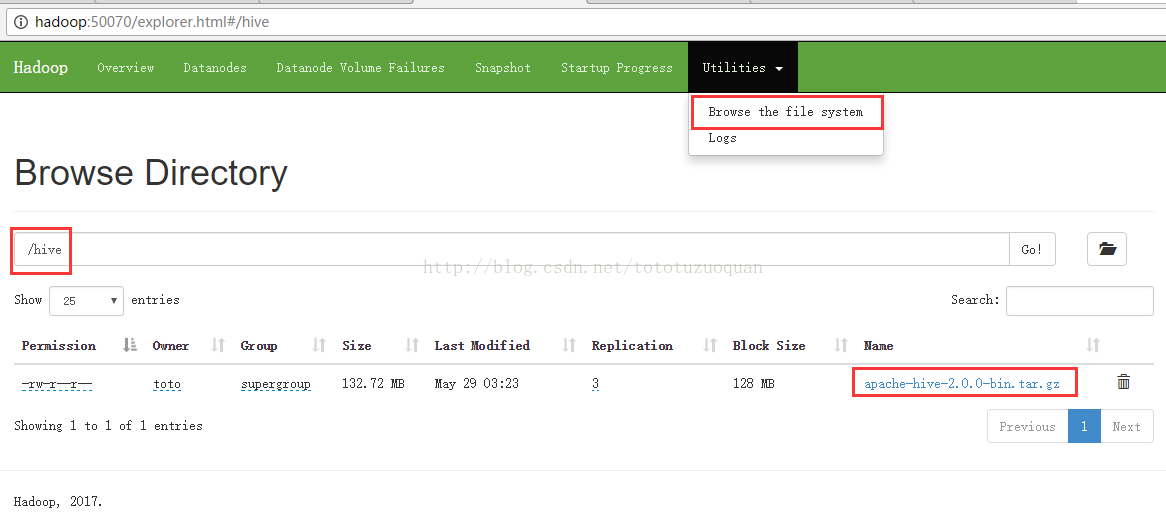 |
| [HADOOP@hdp-node-01 ~]$ HADOOP fs -mkdir -p /wordcount/input [HADOOP@hdp-node-01 ~]$ HADOOP fs -put /home/HADOOP/somewords.txt /wordcount/input |
2、运行一个mapreduce程序
在HADOOP安装目录下,运行一个示例mr程序| cd $HADOOP_HOME/share/hadoop/mapreduce/ hadoop jar mapredcue-example-2.6.1.jar wordcount /wordcount/input /wordcount/output |
3、其它
常见错误:| 异常描述 在对HDFS格式化,执行Hadoop namenode -format命令时,出现未知的主机名的问题,异常信息如下所示: [plain] view plain copy [shirdrn@localhost bin]$ hadoop namenode -format 11/06/22 07:33:31 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = java.net.UnknownHostException: localhost.localdomain: localhost.localdomain STARTUP_MSG: args = [-format] STARTUP_MSG: version = 0.20.0 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/core/branches/branch-0.20 -r 763504; compiled by 'ndaley' on Thu Apr 9 05:18:40 UTC 2009 ************************************************************/ Re-format filesystem in /tmp/hadoop/hadoop-shirdrn/dfs/name ? (Y or N) Y 11/06/22 07:33:36 INFO namenode.FSNamesystem: fsOwner=shirdrn,shirdrn 11/06/22 07:33:36 INFO namenode.FSNamesystem: supergroup=supergroup 11/06/22 07:33:36 INFO namenode.FSNamesystem: isPermissionEnabled=true 11/06/22 07:33:36 INFO metrics.MetricsUtil: Unable to obtain hostName java.net.UnknownHostException: localhost.localdomain: localhost.localdomain at java.net.InetAddress.getLocalHost(InetAddress.java:1353) at org.apache.hadoop.metrics.MetricsUtil.getHostName(MetricsUtil.java:91) at org.apache.hadoop.metrics.MetricsUtil.createRecord(MetricsUtil.java:80) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.initialize(FSDirectory.java:73) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.<init>(FSDirectory.java:68) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.<init>(FSNamesystem.java:370) at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:853) at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:947) at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:964) 11/06/22 07:33:36 INFO common.Storage: Image file of size 97 saved in 0 seconds. 11/06/22 07:33:36 INFO common.Storage: Storage directory /tmp/hadoop/hadoop-shirdrn/dfs/name has been successfully formatted. 11/06/22 07:33:36 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at java.net.UnknownHostException: localhost.localdomain: localhost.localdomain ************************************************************/ 我们通过执行hostname命令可以看到: [plain] view plain copy [shirdrn@localhost bin]# hostname localhost.localdomain 也就是说,Hadoop在格式化HDFS的时候,通过hostname命令获取到的主机名是localhost.localdomain,然后在/etc/hosts文件中进行映射的时候,没有找到,看下我的/etc/hosts内容: [plain] view plain copy [root@localhost bin]# cat /etc/hosts # Do not remove the following line, or various programs # that require network functionality will fail. 127.0.0.1 localhost localhost 192.168.1.103 localhost localhost 也就说,通过localhost.localdomain根本无法映射到一个IP地址,所以报错了。 此时,我们查看一下/etc/sysconfig/network文件: [plain] view plain copy NETWORKING=yes NETWORKING_IPV6=yes HOSTNAME=localhost.localdomain 可见,执行hostname获取到这里配置的HOSTNAME的值。 解决方法 修改/etc/sysconfig/network中HOSTNAME的值为localhost,或者自己指定的主机名,保证localhost在/etc/hosts文件中映射为正确的IP地址,然后重新启动网络服务: [plain] view plain copy [root@localhost bin]# /etc/rc.d/init.d/network restart Shutting down interface eth0: [ OK ] Shutting down loopback interface: [ OK ] Bringing up loopback interface: [ OK ] Bringing up interface eth0: Determining IP information for eth0... done. [ OK ] 这时,再执行格式化HDFS命令,以及启动HDFS集群就正常了。 格式化: [plain] view plain copy [shirdrn@localhost bin]$ hadoop namenode -format 11/06/22 08:02:37 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/127.0.0.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 0.20.0 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/core/branches/branch-0.20 -r 763504; compiled by 'ndaley' on Thu Apr 9 05:18:40 UTC 2009 ************************************************************/ 11/06/22 08:02:37 INFO namenode.FSNamesystem: fsOwner=shirdrn,shirdrn 11/06/22 08:02:37 INFO namenode.FSNamesystem: supergroup=supergroup 11/06/22 08:02:37 INFO namenode.FSNamesystem: isPermissionEnabled=true 11/06/22 08:02:37 INFO common.Storage: Image file of size 97 saved in 0 seconds. 11/06/22 08:02:37 INFO common.Storage: Storage directory /tmp/hadoop/hadoop-shirdrn/dfs/name has been successfully formatted. 11/06/22 08:02:37 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/127.0.0.1 ************************************************************/ 启动: [plain] view plain copy [shirdrn@localhost bin]$ start-all.sh starting namenode, logging to /home/shirdrn/eclipse/eclipse-3.5.2/hadoop/hadoop-0.20.0/logs/hadoop-shirdrn-namenode-localhost.out localhost: starting datanode, logging to /home/shirdrn/eclipse/eclipse-3.5.2/hadoop/hadoop-0.20.0/logs/hadoop-shirdrn-datanode-localhost.out localhost: starting secondarynamenode, logging to /home/shirdrn/eclipse/eclipse-3.5.2/hadoop/hadoop-0.20.0/logs/hadoop-shirdrn-secondarynamenode-localhost.out starting jobtracker, logging to /home/shirdrn/eclipse/eclipse-3.5.2/hadoop/hadoop-0.20.0/logs/hadoop-shirdrn-jobtracker-localhost.out localhost: starting tasktracker, logging to /home/shirdrn/eclipse/eclipse-3.5.2/hadoop/hadoop-0.20.0/logs/hadoop-shirdrn-tasktracker-localhost.out 查看: [plain] view plain copy [shirdrn@localhost bin]$ jps 8192 TaskTracker 7905 DataNode 7806 NameNode 8065 JobTracker 8002 SecondaryNameNode 8234 Jps |
| 错误二: --- hadoop2 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1242ms rtt min/avg/max/mdev = 0.674/0.695/0.716/0.021 ms [toto@hadoop hadoop-2.8.0]$ sbin/start-dfs.sh 17/05/28 19:11:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [hadoop] toto@hadoop's password: hadoop: namenode running as process 3943. Stop it first. The authenticity of host 'hadoop3 (192.168.106.82)' can't be established. RSA key fingerprint is 23:da:24:9c:b9:82:fa:f2:52:3c:30:2c:98:1e:4a:d7. Are you sure you want to continue connecting (yes/no)? The authenticity of host 'hadoop2 (192.168.106.81)' can't be established. RSA key fingerprint is 23:da:24:9c:b9:82:fa:f2:52:3c:30:2c:98:1e:4a:d7. Are you sure you want to continue connecting (yes/no)? toto@hadoop's password: 解决办法: |
注意:core-site的说明
[align=center]
| name | value | Description |
| fs.default.name | hdfs://hadoopmaster:9000 | 定义HadoopMaster的URI和端口 |
| fs.checkpoint.dir | /opt/data/hadoop1/hdfs/namesecondary1 | 定义hadoop的name备份的路径,官方文档说是读取这个,写入dfs.name.dir |
| fs.checkpoint.period | 1800 | 定义name备份的备份间隔时间,秒为单位,只对snn生效,默认一小时 |
| fs.checkpoint.size | 33554432 | 以日志大小间隔做备份间隔,只对snn生效,默认64M |
| io.compression.codecs | org.apache.hadoop.io.compress.DefaultCodec, com.hadoop.compression.lzo.LzoCodec, com.hadoop.compression.lzo.LzopCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec (排版调整,实际配置不要回车) | Hadoop所使用的编解码器,gzip和bzip2为自带,lzo需安装hadoopgpl或者kevinweil,逗号分隔,snappy也需要单独安装 |
| io.compression.codec.lzo.class | com.hadoop.compression.lzo.LzoCodec | LZO所使用的压缩编码器 |
| topology.script.file.name | /hadoop/bin/RackAware.py | 机架感知脚本位置 |
| topology.script.number.args | 1000 | 机架感知脚本管理的主机数,IP地址 |
| fs.trash.interval | 10800 | HDFS垃圾箱设置,可以恢复误删除,分钟数,0为禁用,添加该项无需重启hadoop |
| hadoop.http.filter.initializers | org.apache.hadoop.security. AuthenticationFilterInitializer (排版调整,实际配置不要回车) | 需要jobtracker,tasktracker namenode,datanode等http访问端口用户验证使用,需配置所有节点 |
| hadoop.http.authentication.type | simple | kerberos | #AUTHENTICATION_HANDLER_CLASSNAME# | 验证方式,默认为简单,也可自己定义class,需配置所有节点 |
| hadoop.http.authentication. token.validity (排版调整,实际配置不要回车) | 36000 | 验证令牌的有效时间,需配置所有节点 |
| hadoop.http.authentication. signature.secret (排版调整,实际配置不要回车) | 默认可不写参数 | 默认不写在hadoop启动时自动生成私密签名,需配置所有节点 |
| hadoop.http.authentication.cookie.domain | domian.tld | http验证所使用的cookie的域名,IP地址访问则该项无效,必须给所有节点都配置域名才可以。 |
| hadoop.http.authentication. simple.anonymous.allowed (排版调整,实际配置不要回车) | true | false | 简单验证专用,默认允许匿名访问,true |
| hadoop.http.authentication. kerberos.principal (排版调整,实际配置不要回车) | HTTP/localhost@$LOCALHOST | Kerberos验证专用,参加认证的实体机必须使用HTTP作为K的Name |
| hadoop.http.authentication. kerberos.keytab (排版调整,实际配置不要回车) | /home/xianglei/hadoop.keytab | Kerberos验证专用,密钥文件存放位置 |
| hadoop.security.authorization | true|false | Hadoop服务层级验证安全验证,需配合hadoop-policy.xml使用,配置好以后用dfsadmin,mradmin -refreshServiceAcl刷新生效 |
| io.file.buffer.size | 131072 | 用作序列化文件处理时读写buffer的大小 |
| hadoop.security.authentication | simple | kerberos | hadoop本身的权限验证,非http访问,simple或者kerberos |
| hadoop.logfile.size | 1000000000 | 设置日志文件大小,超过则滚动新日志 |
| hadoop.logfile.count | 20 | 最大日志数 |
| io.bytes.per.checksum | 1024 | 每校验码所校验的字节数,不要大于io.file.buffer.size |
| io.skip.checksum.errors | true | false | 处理序列化文件时跳过校验码错误,不抛异常。默认false |
| io.serializations | org.apache.hadoop.io. serializer.WritableSerialization (排版需要。实际配置不要回车) | 序列化的编解码器 |
| io.seqfile.compress.blocksize | 1024000 | 块压缩的序列化文件的最小块大小,字节 |
| webinterface.private.actions | true | false | 设为true,则JT和NN的tracker网页会出现杀任务删文件等操作连接,默认是false |
hdfs-site的配置说明:
| name | value | Description |
| dfs.default.chunk.view.size | 32768 | namenode的http访问页面中针对每个文件的内容显示大小,通常无需设置。 |
| dfs.datanode.du.reserved | 1073741824 | 每块磁盘所保留的空间大小,需要设置一些,主要是给非hdfs文件使用,默认是不保留,0字节 |
| dfs.name.dir | /opt/data1/hdfs/name, /opt/data2/hdfs/name, /nfs/data/hdfs/name | NN所使用的元数据保存,一般建议在nfs上保留一份,作为1.0的HA方案使用,也可以在一台服务器的多块硬盘上使用 |
| dfs.web.ugi | nobody,nobody | NN,JT等所使用的web tracker页面服务器所使用的用户和组 |
| dfs.permissions | true | false | dfs权限是否打开,我一般设置false,通过开发工具培训别人界面操作避免误操作,设置为true有时候会遇到数据因为权限访问不了。 |
| dfs.permissions.supergroup | supergroup | 设置hdfs超级权限的组,默认是supergroup,启动hadoop所使用的用户通常是superuser。 |
| dfs.data.dir | /opt/data1/hdfs/data, /opt/data2/hdfs/data, /opt/data3/hdfs/data, ... | 真正的datanode数据保存路径,可以写多块硬盘,逗号分隔 |
| dfs.datanode.data.dir.perm | 755 | datanode所使用的本地文件夹的路径权限,默认755 |
| dfs.replication | 3 | hdfs数据块的复制份数,默认3,理论上份数越多跑数速度越快,但是需要的存储空间也更多。有钱人可以调5或者6 |
| dfs.replication.max | 512 | 有时dn临时故障恢复后会导致数据超过默认备份数。复制份数的最多数,通常没什么用,不用写配置文件里。 |
| dfs.replication.min | 1 | 最小份数,作用同上。 |
| dfs.block.size | 134217728 | 每个文件块的大小,我们用128M,默认是64M。这个计算需要128*1024^2,我碰上过有人直接写128000000,十分浪漫。 |
| dfs.df.interval | 60000 | 磁盘用量统计自动刷新时间,单位是毫秒。 |
| dfs.client.block.write.retries | 3 | 数据块写入的最多重试次数,在此次数之前不会捕获失败。 |
| dfs.heartbeat.interval | 3 | DN的心跳检测时间间隔。秒 |
| dfs.namenode.handler.count | 10 | NN启动后展开的线程数。 |
| dfs.balance.bandwidthPerSec | 1048576 | 做balance时所使用的每秒最大带宽,使用字节作为单位,而不是bit |
| dfs.hosts | /opt/hadoop/conf/hosts.allow | 一个主机名列表文件,这里的主机是允许连接NN的,必须写绝对路径,文件内容为空则认为全都可以。 |
| dfs.hosts.exclude | /opt/hadoop/conf/hosts.deny | 基本原理同上,只不过这里放的是禁止访问NN的主机名称列表。这在从集群中摘除DN会比较有用。 |
| dfs.max.objects | 0 | dfs最大并发对象数,HDFS中的文件,目录块都会被认为是一个对象。0表示不限制 |
| dfs.replication.interval | 3 | NN计算复制块的内部间隔时间,通常不需写入配置文件。默认就好 |
| dfs.support.append | true | false | 新的hadoop支持了文件的APPEND操作,这个就是控制是否允许文件APPEND的,但是默认是false,理由是追加还有bug。 |
| dfs.datanode.failed.volumes.tolerated | 0 | 能够导致DN挂掉的坏硬盘最大数,默认0就是只要有1个硬盘坏了,DN就会shutdown。 |
| dfs.secondary.http.address | 0.0.0.0:50090 | SNN的tracker页面监听地址和端口 |
| dfs.datanode.address | 0.0.0.0:50010 | DN的服务监听端口,端口为0的话会随机监听端口,通过心跳通知NN |
| dfs.datanode.http.address | 0.0.0.0:50075 | DN的tracker页面监听地址和端口 |
| dfs.datanode.ipc.address | 0.0.0.0:50020 | DN的IPC监听端口,写0的话监听在随机端口通过心跳传输给NN |
| dfs.datanode.handler.count | 3 | DN启动的服务线程数 |
| dfs.http.address | 0.0.0.0:50070 | NN的tracker页面监听地址和端口 |
| dfs.https.enable | true | false | NN的tracker是否监听在HTTPS协议,默认false |
| dfs.datanode.https.address | 0.0.0.0:50475 | DN的HTTPS的tracker页面监听地址和端口 |
| dfs.https.address | 0.0.0.0:50470 | NN的HTTPS的tracker页面监听地址和端口 |
| dfs.datanode.max.xcievers | 2048 | 相当于linux下的打开文件最大数量,文档中无此参数,当出现DataXceiver报错的时候,需要调大。默认256 |
| name | value | Description |
| hadoop.job.history.location | job历史文件保存路径,无可配置参数,也不用写在配置文件里,默认在logs的history文件夹下。 | |
| hadoop.job.history.user.location | 用户历史文件存放位置 | |
| io.sort.factor | 30 | 这里处理流合并时的文件排序数,我理解为排序时打开的文件数 |
| io.sort.mb | 600 | 排序所使用的内存数量,单位兆,默认1,我记得是不能超过mapred.child.java.opt设置,否则会OOM |
| mapred.job.tracker | hadoopmaster:9001 | 连接jobtrack服务器的配置项,默认不写是local,map数1,reduce数1 |
| mapred.job.tracker.http.address | 0.0.0.0:50030 | jobtracker的tracker页面服务监听地址 |
| mapred.job.tracker.handler.count | 15 | jobtracker服务的线程数 |
| mapred.task.tracker.report.address | 127.0.0.1:0 | tasktracker监听的服务器,无需配置,且官方不建议自行修改 |
| mapred.local.dir | /data1/hdfs/mapred/local, /data2/hdfs/mapred/local, ... | mapred做本地计算所使用的文件夹,可以配置多块硬盘,逗号分隔 |
| mapred.system.dir | /data1/hdfs/mapred/system, /data2/hdfs/mapred/system, ... | mapred存放控制文件所使用的文件夹,可配置多块硬盘,逗号分隔。 |
| mapred.temp.dir | /data1/hdfs/mapred/temp, /data2/hdfs/mapred/temp, ... | mapred共享的临时文件夹路径,解释同上。 |
| mapred.local.dir.minspacestart | 1073741824 | 本地运算文件夹剩余空间低于该值则不在本地做计算。字节配置,默认0 |
| mapred.local.dir.minspacekill | 1073741824 | 本地计算文件夹剩余空间低于该值则不再申请新的任务,字节数,默认0 |
| mapred.tasktracker.expiry.interval | 60000 | TT在这个时间内没有发送心跳,则认为TT已经挂了。单位毫秒 |
| mapred.map.tasks | 2 | 默认每个job所使用的map数,意思是假设设置dfs块大小为64M,需要排序一个60M的文件,也会开启2个map线程,当jobtracker设置为本地是不起作用。 |
| mapred.reduce.tasks | 1 | 解释同上 |
| mapred.jobtracker.restart.recover | true | false | 重启时开启任务恢复,默认false |
| mapred.jobtracker.taskScheduler | org.apache.hadoop.mapred. CapacityTaskScheduler org.apache.hadoop.mapred. JobQueueTaskScheduler org.apache.hadoop.mapred. FairScheduler | 重要的东西,开启任务管理器,不设置的话,hadoop默认是FIFO调度器,其他可以使用公平和计算能力调度器 |
| mapred.reduce.parallel.copies | 10 | reduce在shuffle阶段使用的并行复制数,默认5 |
| mapred.child.java.opts | -Xmx2048m -Djava.library.path= /opt/hadoopgpl/native/ Linux-amd64-64 | 每个TT子进程所使用的虚拟机内存大小 |
| tasktracker.http.threads | 50 | TT用来跟踪task任务的http server的线程数 |
| mapred.task.tracker.http.address | 0.0.0.0:50060 | TT默认监听的httpIP和端口,默认可以不写。端口写0则随机使用。 |
| mapred.output.compress | true | false | 任务结果采用压缩输出,默认false,建议false |
| mapred.output.compression.codec | org.apache.hadoop.io. compress.DefaultCodec | 输出结果所使用的编解码器,也可以用gz或者bzip2或者lzo或者snappy等 |
| mapred.compress.map.output | true | false | map输出结果在进行网络交换前是否以压缩格式输出,默认false,建议true,可以减小带宽占用,代价是会慢一些。 |
| mapred.map.output.compression.codec | com.hadoop.compression. lzo.LzoCodec | map阶段压缩输出所使用的编解码器 |
| map.sort.class | org.apache.hadoop.util. QuickSort | map输出排序所使用的算法,默认快排。 |
| mapred.hosts | conf/mhost.allow | 允许连接JT的TT服务器列表,空值全部允许 |
| mapred.hosts.exclude | conf/mhost.deny | 禁止连接JT的TT列表,节点摘除是很有作用。 |
| mapred.queue.names | ETL,rush,default | 配合调度器使用的队列名列表,逗号分隔 |
| mapred.tasktracker.map. tasks.maximum | 12 | 每服务器允许启动的最大map槽位数。 |
| mapred.tasktracker.reduce. tasks.maximum | 6 | 每服务器允许启动的最大reduce槽位数 |

相关文章推荐
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程~(心血之作啊~~)
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程~(心血之作啊~~)
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程~(心血之作啊~~)
- hadoop源码编译、配置安装、测试
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程
- hadoop集群搭建过程中几个配置参数
- Hadoop、Zookeeper、Hbase集群安装配置过程及常见问题(一)准备工作
- Hadoop集群搭建之SSH无密码登录配置错误解析
- hadoop-HA集群搭建,启动DataNode,检测启动状态,执行HDFS命令,启动YARN,HDFS权限配置,C++客户端编程,常见错误
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程~
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程~(心血之作啊~~)
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程~(心血之作啊~~)
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程~(心血之作啊~~) .
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程
- CentOS 源码编译安装Pure-FTPd(配置系统用户登录)
- hadoop 1.x集群搭建及搭建过程遇到的问题总结
- hadoop分布式集群搭建=两次的总结--包括挂载文件系统