HDFS的工作机制,HDFS写数据流程,HDFS读数据流程(来自学习资料)
2017-05-30 17:31
525 查看
4.hdfs的工作机制
(工作机制的学习主要是为加深对分布式系统的理解,以及增强遇到各种问题时的分析解决能力,形成一定的集群运维能力)注:很多不是真正理解hadoop技术体系的人会常常觉得HDFS可用于网盘类应用,但实际并非如此。要想将技术准确用在恰当的地方,必须对技术有深刻的理解
4.1 概述
1. HDFS集群分为两大角色:NameNode、DataNode (Secondary Namenode)2. NameNode负责管理整个文件系统的元数据
3. DataNode 负责管理用户的文件数据块
4. 文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上
5. 每一个文件块可以有多个副本,并存放在不同的datanode上
6. Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
7. HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
4.2 HDFS写数据流程
4.2.1 概述
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本4.2.2 详细步骤图
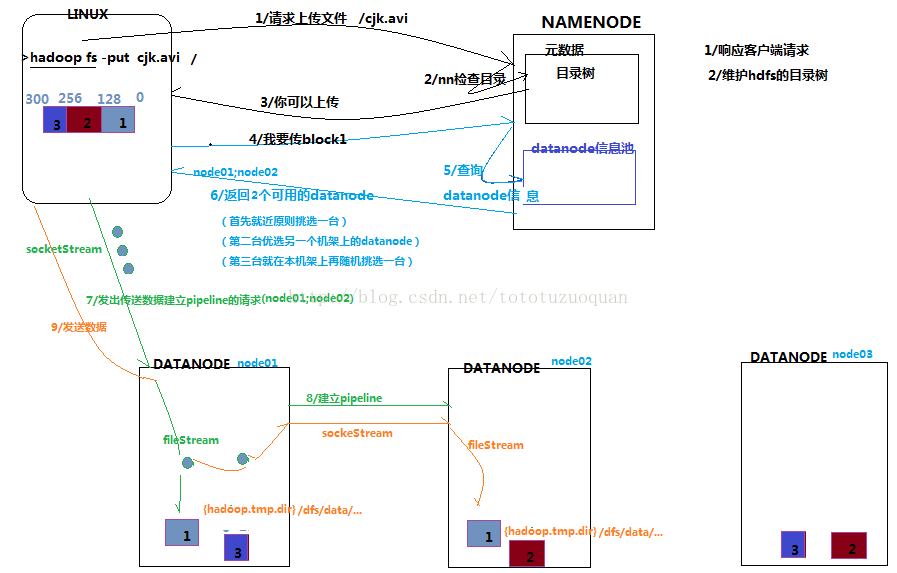
4.2.3 详细步骤解析
1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
4.3. HDFS读数据流程
4.3.1 概述
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件4.3.2 详细步骤图
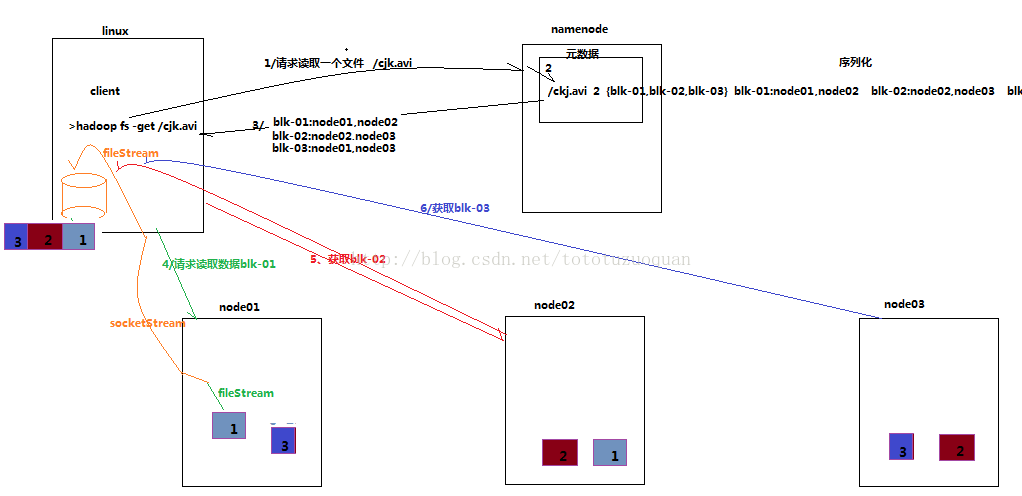
4.3.3 详细步骤解析
1、跟namenode通信查询元数据,找到文件块所在的datanode服务器2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4、客户端以packet为单位接收,现在本地缓存,然后写入目标文件

相关文章推荐
- NAMENODE工作机制,元数据管理(元数据存储机制、元数据手动查看)、元数据的checkpoint、元数据目录说明(来自学习资料)
- Storm通信机制,Worker进程间通信,Worker进程间通信分析,Worker进程间技术(Netty、ZeroMQ),Worker 内部通信技术(Disruptor)(来自学习资料)
- Sqoop数据迁移,工作机制,sqoop安装(配置),Sqoop的数据导入,导入表数据到HDFS,导入关系表到HIVE,导入到HDFS指定目录,导入表数据子集,按需导入,增量导入,sqoop数据导出
- 3.Kafka整体结构图、Consumer与topic关系、Kafka消息分发、Consumer的负载均衡、Kafka文件存储机制、Kafka partition segment等(来自学习资料)
- Hive简介、什么是Hive、为什么使用Hive、Hive的特点、Hive架构图、Hive基本组成、Hive与Hadoop的关系、Hive与传统数据库对比、Hive数据存储(来自学习资料)
- hdfs工作机制及读写数据简要流程图
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
- HBase学习总结(3):HBase的数据模型及工作机制
- 大数据之路-Hadoop-5-HDFS原理解析及NameNode、DataNode工作机制
- 大数据学习9:HDFS读写流程理解
- Python基础,基本类型(整型,浮点数等)数据结构(List,dic(Map),Set,Tuple),控制语句(if,for,while,continue or break):来自学习资料
- 王家林 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
- Kafka整体结构图、Consumer与topic关系、Kafka消息分发、Consumer的负载均衡、Kafka文件存储机制、Kafka partition segment等(来自学习资料)
- Hadoop深入学习:解析HDFS的写资料流程
- hdfs haadmin使用,DataNode动态上下线,NameNode状态切换管理,数据块的balance,HA下hdfs-api变化(来自学习资料)
- 机器学习工作流程从数据清洗到模型调优
- Flex学习-事件机制的工作流程
- hdfs读写数据的工作机制
- 大数据学习笔记3--HDFS扩展和mapreduce工作过程
- Hadoop学习(三)— hdfs : NameNode与DataNode的实现机制