CAFFE源码学习笔记之内积层-inner_product_layer
2017-04-11 15:12
309 查看
一、前言
内积层实际就是全连接。经过之前的卷积层、池化层和非线性变换层,样本已经被映射到隐藏层的特征空间之中,而全连接层就是将学习到的特征又映射到样本分类空间。虽然已经出现了全局池化可以替代全连接,但是仍然不能说全连接就不能用了。
二、源码分析
1、成员变量
全连接的输入时一个M*K的矩阵,权重是K*N的矩阵,所以输出是一个M*N的矩阵
2、layersetup
权重是K*N的矩阵:(C*H*W)*num_output
3、reshape
输入是一个M*K的矩阵:num_input*(C*H*W)
经过转换:top_shape.resize(axis + 1)
输出是M*N的矩阵:
num_input∗num_output
3、前向计算
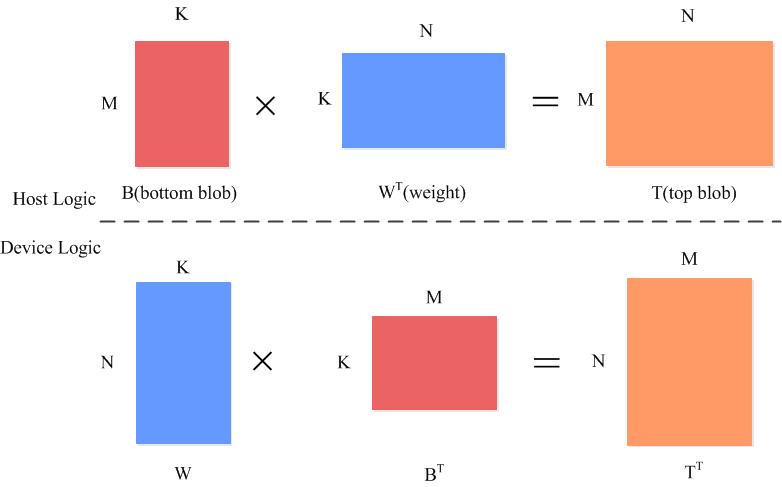
直接调用矩阵内积函数caffe_gpu_gemm
4、反向传播
对参数求偏导
∂loss∂wkj=∂loss∂zk∗∂zk∂wkj=∂loss∂zk∗uj
转换成向量:
∂loss∂Wj==∂loss∂Z∗uj
转换成矩阵:
∂loss∂W==∂loss∂ZT∗U
即layer_blobs_=topdiff∗bottom_data
对输出求偏导:
公式:
∂loss∂uj=∑n=Mk∂loss∂zk∗∂zk∂uj
转化为向量
∂loss∂UT=∂loss∂ZT∗W
M为需要分的类别数
转换成矩阵的形式:
∂loss∂U=∂loss∂Z∗W
即
bottom_diff=top_diff∗layer_blobs_
内积层实际就是全连接。经过之前的卷积层、池化层和非线性变换层,样本已经被映射到隐藏层的特征空间之中,而全连接层就是将学习到的特征又映射到样本分类空间。虽然已经出现了全局池化可以替代全连接,但是仍然不能说全连接就不能用了。
二、源码分析
1、成员变量
全连接的输入时一个M*K的矩阵,权重是K*N的矩阵,所以输出是一个M*N的矩阵
int M_;//num_input int K_;//C*H*W int N_;//N_ = num_output bool bias_term_; Blob<Dtype> bias_multiplier_; bool transpose_; ///< if true, assume transposed weights```
2、layersetup
权重是K*N的矩阵:(C*H*W)*num_output
template <typename Dtype>
void InnerProductLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const int num_output = this->layer_param_.inner_product_param().num_output();//输出
bias_term_ = this->layer_param_.inner_product_param().bias_term();
transpose_ = this->layer_param_.inner_product_param().transpose();
N_ = num_output;
const int axis = bottom[0]->CanonicalAxisIndex(
this->layer_param_.inner_product_param().axis());
// Dimensions starting from "axis" are "flattened" into a single
// length K_ vector. For example, if bottom[0]'s shape is (N, C, H, W),
// and axis == 1, N inner products with dimension CHW are performed.
K_ = bottom[0]->count(axis);
// Check if we need to set up the weights
if (this->blobs_.size() > 0) {
LOG(INFO) << "Skipping parameter initialization";
} else {
if (bias_term_) {
this->blobs_.resize(2);
} else {
this->blobs_.resize(1);
}
// Initialize the weights
vector<int> weight_shape(2);
if (transpose_) {
weight_shape[0] = K_;
weight_shape[1] = N_;
} else {
weight_shape[0] = N_;
weight_shape[1] = K_;
}
this->blobs_[0].reset(new Blob<Dtype>(weight_shape));
// fill the weights
shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>(
this->layer_param_.inner_product_param().weight_filler()));
weight_filler->Fill(this->blobs_[0].get());
// If necessary, intiialize and fill the bias term
if (bias_term_) {
vector<int> bias_shape(1, N_);
this->blobs_[1].reset(new Blob<Dtype>(bias_shape));
shared_ptr<Filler<Dtype> > bias_filler(GetFiller<Dtype>(
this->layer_param_.inner_product_param().bias_filler()));
bias_filler->Fill(this->blobs_[1].get());
}
} // parameter initialization
this->param_propagate_down_.resize(this->blobs_.size(), true);
}3、reshape
输入是一个M*K的矩阵:num_input*(C*H*W)
经过转换:top_shape.resize(axis + 1)
输出是M*N的矩阵:
num_input∗num_output
template <typename Dtype>
void InnerProductLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// Figure out the dimensions
const int axis = bottom[0]->CanonicalAxisIndex(
this->layer_param_.inner_product_param().axis());
const int new_K = bottom[0]->count(axis);
CHECK_EQ(K_, new_K)
<< "Input size incompatible with inner product parameters.";
// The first "axis" dimensions are independent inner products; the total
// number of these is M_, the product over these dimensions.
M_ = bottom[0]->count(0, axis);//num_input
// The top shape will be the bottom shape with the flattened axes dropped,
// and replaced by a single axis with dimension num_output (N_).
vector<int> top_shape = bottom[0]->shape();
top_shape.resize(axis + 1);
top_shape[axis] = N_;
top[0]->Reshape(top_shape);
// Set up the bias multiplier
if (bias_term_) {
vector<int> bias_shape(1, M_);
bias_multiplier_.Reshape(bias_shape);
caffe_set(M_, Dtype(1), bias_multiplier_.mutable_cpu_data());
}
}3、前向计算
直接调用矩阵内积函数caffe_gpu_gemm
template <typename Dtype>
void InnerProductLayer<Dtype>::Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->gpu_data();
Dtype* top_data = top[0]->mutable_gpu_data();
const Dtype* weight = this->blobs_[0]->gpu_data();
if (M_ == 1) {
caffe_gpu_gemv<Dtype>(CblasNoTrans, N_, K_, (Dtype)1.,weight, bottom_data, (Dtype)0., top_data);//这个是向量内积函数
if (bias_term_)
caffe_gpu_axpy<Dtype>(N_, bias_multiplier_.cpu_data()[0],this->blobs_[1]->gpu_data(), top_data);
} else {
caffe_gpu_gemm<Dtype>(CblasNoTrans,transpose_ ? CblasNoTrans : CblasTrans,M_, N_, K_, (Dtype)1.,bottom_data, weight, (Dtype)0., top_data);
if (bias_term_)
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, N_, 1, (Dtype)1.,bias_multiplier_.gpu_data(),this->blobs_[1]->gpu_data(), (Dtype)1., top_data);
}
}4、反向传播
对参数求偏导
∂loss∂wkj=∂loss∂zk∗∂zk∂wkj=∂loss∂zk∗uj
转换成向量:
∂loss∂Wj==∂loss∂Z∗uj
转换成矩阵:
∂loss∂W==∂loss∂ZT∗U
即layer_blobs_=topdiff∗bottom_data
对输出求偏导:
公式:
∂loss∂uj=∑n=Mk∂loss∂zk∗∂zk∂uj
转化为向量
∂loss∂UT=∂loss∂ZT∗W
M为需要分的类别数
转换成矩阵的形式:
∂loss∂U=∂loss∂Z∗W
即
bottom_diff=top_diff∗layer_blobs_
template <typename Dtype>
void InnerProductLayer<Dtype>::Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
if (this->param_propagate_down_[0]) {
const Dtype* top_diff = top[0]->gpu_diff();
const Dtype* bottom_data = bottom[0]->gpu_data();
// Gradient with respect to weight
if (transpose_) {
caffe_gpu_gemm<Dtype>(CblasTrans, CblasNoTrans,
K_, N_, M_,
(Dtype)1., bottom_data, top_diff,
(Dtype)1., this->blobs_[0]->mutable_gpu_diff());
} else {
caffe_gpu_gemm<Dtype>(CblasTrans, CblasNoTrans,
N_, K_, M_,
(Dtype)1., top_diff, bottom_data,
(Dtype)1., this->blobs_[0]->mutable_gpu_diff());
}
}
if (bias_term_ && this->param_propagate_down_[1]) {
const Dtype* top_diff = top[0]->gpu_diff();
// Gradient with respect to bias
caffe_gpu_gemv<Dtype>(CblasTrans, M_, N_, (Dtype)1., top_diff,
bias_multiplier_.gpu_data(), (Dtype)1.,
this->blobs_[1]->mutable_gpu_diff());
}
if (propagate_down[0]) {
const Dtype* top_diff = top[0]->gpu_diff();
// Gradient with respect to bottom data
if (transpose_) {
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasTrans,
M_, K_, N_,
(Dtype)1., top_diff, this->blobs_[0]->gpu_data(),
(Dtype)0., bottom[0]->mutable_gpu_diff());
} else {
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans,
M_, K_, N_,
(Dtype)1., top_diff, this->blobs_[0]->gpu_data(),
(Dtype)0., bottom[0]->mutable_gpu_diff());
}
}
}

相关文章推荐
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之内积层-inner_product_layer
- 学习笔记: 源码 inner_product_layer.cpp 略识
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之七-layer_factory以及layer基类
- CAFFE源码学习笔记之七-layer_factory以及layer基类
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之七-layer_factory以及layer基类
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer