CAFFE源码学习笔记之十一-卷积层conv_layer
2017-04-09 13:29
399 查看
一、前言
vison layer主要是处理图像相关,以图像数据为输入,输出为经过卷积或者pooling后的特征图。该大类包含Convolution(conv_layer.hpp)、Pooling(pooling_layer.hpp)、Local Response Normalization(LRN)(lrn_layer.hpp)、im2col等。
在大多数深度学习模型中,数据经过数据层后,一些分割层后,马上进入的就是卷积层。下面就看看卷积层的源码,同时复习一下卷积的知识。
注意:CAFFE中的Blob是按照行优先的方式存储在线性内存中的,而CUDA则是按照列优先存储的,所以后面会涉及大量的转置操作。
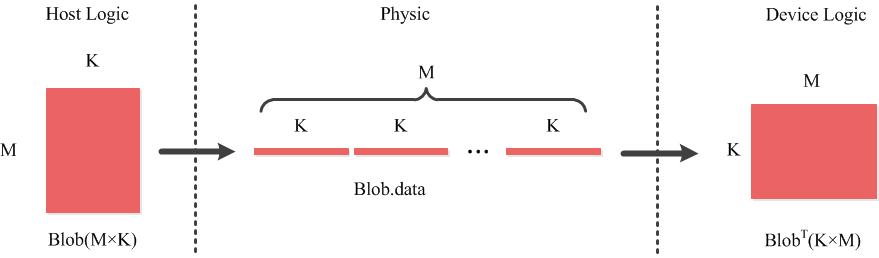
二、conv_layer源码分析
1、base_conv_layer类
由于base_conv_layer类是conv_layer的基类,而且大部分内容都是由该类负责的。
a、成员变量
b、LayerSetUp函数
关于channel轴,在convolutionParameter中有介绍:
此函数的关键是卷积层的权重weight_Blob的形状和初始化:
每个层的layersetup函数需要自己定义:
c、reshape函数
根据输入重塑输出的形状
d、前向计算
卷积层的前向计算大体如下:
其中最重要的是函数conv_im2col_gpu。
转换成矩阵后就调用cblas函caffe_gpu_gemm
所以,卷积的具体实现就是:
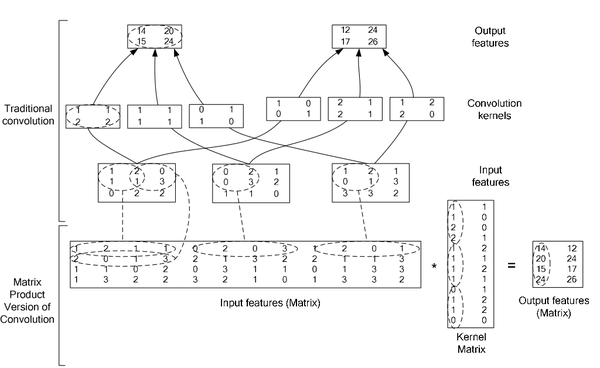
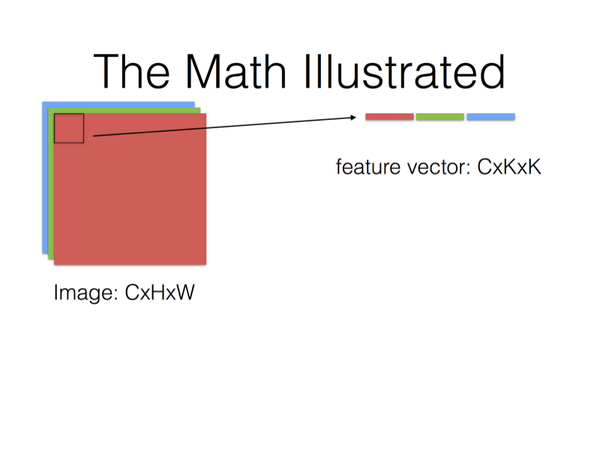
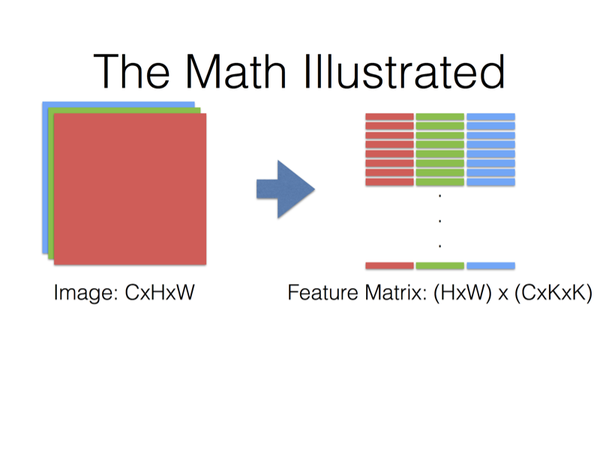
输入图像为(C通道数,H图像高度,W图像宽度)
转换为列表示:
每一单列为:C×K×K
列的行数就是卷积核在图像上的滑动次数(输出图像高×输出图像宽)
卷积核的表示:
Cout×C×K×K转换后变为Cout个C×K×K列
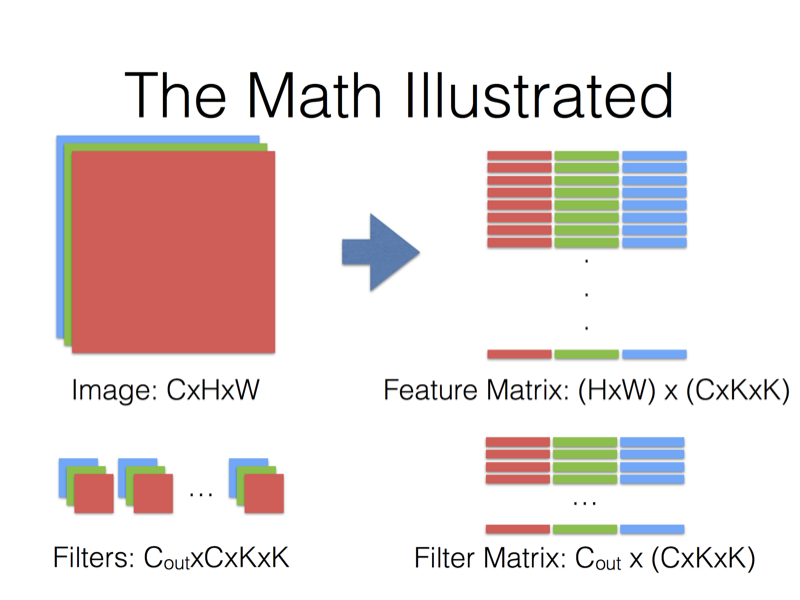
两者做内积,最后得到输出为:
Cout×(输出图像高,输出图像宽)的矩阵
img2col的具体实现:
按照channel*kernel_h*kernel_w一列,将一个channel x kernel_h x kernel_w 大小的图像块变成一个列。
有多少个这样的列呢,这就可以用公式进行计算
列数 = [(图像高度+2*填充高度-kernel高度)/stride高度+1] * [(图像宽度+2*填充宽度-kernel宽度)/stride宽度+1]
这个行数就是一个kernel大小的图像块的维度
这个列数实际上就是kernel在图像上滑动的次数
完成转换之后就直接调用gemm函数进行矩阵的内积
首先是卷积核与输入的计算:
如果需要加上偏置项:
e、后向计算
后向计算同样是矩阵的内积,只是输入和输出倒置
三、conv_layer
conv_layer继承自base_conv_layer,需要自己实现的函数只有三个。一个是base_conv_layer的纯虚函数compute_output_shape(),一个是前向计算函数,最后是后向计算函数。
compute_output_shape()
cpu模式下的前向计算(就是调用基类的forward_cpu_gemm,没啥可说的)
cpu模式下的后向计算
四、总结
借助对卷积层的分析,理解了作者的一个实现技巧,同时也是对输入输出,卷积核的维度信息有了更深刻的理解。
vison layer主要是处理图像相关,以图像数据为输入,输出为经过卷积或者pooling后的特征图。该大类包含Convolution(conv_layer.hpp)、Pooling(pooling_layer.hpp)、Local Response Normalization(LRN)(lrn_layer.hpp)、im2col等。
在大多数深度学习模型中,数据经过数据层后,一些分割层后,马上进入的就是卷积层。下面就看看卷积层的源码,同时复习一下卷积的知识。
注意:CAFFE中的Blob是按照行优先的方式存储在线性内存中的,而CUDA则是按照列优先存储的,所以后面会涉及大量的转置操作。
二、conv_layer源码分析
1、base_conv_layer类
由于base_conv_layer类是conv_layer的基类,而且大部分内容都是由该类负责的。
a、成员变量
/// 卷积核的尺寸,一般为3×3,5×5,1×1等:kernel的形状 = [kernel_h, kernel_w] ,仅表示二维 Blob<int> kernel_shape_; ///卷积核移动的步长,分为长宽两个维度:步长形状 = [stride_h, stride_w] 仅表示二维 Blob<int> stride_; ///是否对原图像数据在边缘进行填充:pad的形状 = [pad_h, pad_w] 仅表示二维 Blob<int> pad_; /// 数据扩充,仅表示二维,一般默认为1 Blob<int> dilation_; /// 输入的维度:卷积的输入形状 = [输入图像通道数, 输入图像h,输入图像w] Blob<int> conv_input_shape_; /// 图像变为列之后的形状,col_buffer的形状 = [kernel_dim_, conv_out_spatial_dim_ ] vector<int> col_buffer_shape_; /// 输出的维度 vector<int> output_shape_; const vector<int>* bottom_shape_;//输入维度信息。const表示只读 int num_spatial_axes_;//图像轴的个数,就是图像数据的维度,2d或者3d的图像之类 int bottom_dim_;//输入维度= 输入图像通道数*输入图像的h*输入图像w int top_dim_;//输出维度= 输出通道数*输出h*输出w int channel_axis_;//输入图像的第几个轴是通道,一般为1 int num_;//batchsize int channels_;//输入图像的通道数 int group_;//卷积组的大小 int out_spatial_dim_;//输出图像数据的空间维度 = 卷积之后的图像长*卷积之后图像的宽,通过compute_output_shape计算的 int weight_offset_;//分组时需要的位移偏量 int num_output_;//输出特征图个数 bool bias_term_;//是否需要偏置项 bool is_1x1_;//是否是1×1的卷积核 bool force_nd_im2col_;//是否强制使用n维通用卷积 int num_kernels_im2col_;//conv_in_channels_ * conv_out_spatial_dim_ int num_kernels_col2im_;//num_kernels_col2im_ = reverse_dimensions() ? top_dim_ : bottom_dim_ int conv_out_channels_;//卷积输出通道数 int conv_in_channels_;//卷积输入通道数 int conv_out_spatial_dim_;//卷积后输出的图像维度 int kernel_dim_;//kernel_h*kernel_w int col_offset_;//列下的偏移量 int output_offset_; Blob<Dtype> col_buffer_;//列的缓存 Blob<Dtype> bias_multiplier_;
b、LayerSetUp函数
关于channel轴,在convolutionParameter中有介绍:
With (N, C, H, W) inputs, and axis == 1 (the default), we perform // N independent 2D convolutions, sliding C-channel (or (C/g)-channels, for // groups g>1) filters across the spatial axes (H, W) of the input. // With (N, C, D, H, W) inputs, and axis == 1, we perform // N independent 3D convolutions, sliding (C/g)-channels // filters across the spatial axes (D, H, W) of the input. 翻译:对于一个维度为(N, C, H, W)的输入,axis==1,其意义为N个H×W的2维卷积核,在c/g通道数上滑动 对于一个维度为(N, C, D, H, W) 的输入,axis==1,其表示为N个3d(D, H, W)的卷积核在c/g通道数上滑动。
此函数的关键是卷积层的权重weight_Blob的形状和初始化:
weight的维度为:conv_out_channels_ x conv_in_channels_ / group_x kernel height x kernel width conv_out_channels_ = num_output_;//正常情况,输出通道数为输出的个数 conv_in_channels_ = channels_;//卷积核的通道数和输入是相同的,计算将互相消除。
每个层的layersetup函数需要自己定义:
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
ConvolutionParameter conv_param = this->layer_param_.convolution_param();//卷积核的参数:卷积核大小,步长,填充,扩展
force_nd_im2col_ = conv_param.force_nd_im2col();//是否使用n维im2col方法计算
channel_axis_ = bottom[0]->CanonicalAxisIndex(conv_param.axis());//轴大于0就直接返回,小于0换算成大于0的。一般默认为1
const int first_spatial_axis = channel_axis_ + 1;//1+1=2
const int num_axes = bottom[0]->num_axes();//根据输入判断4或者5,对应2维或者3维
num_spatial_axes_ = num_axes - first_spatial_axis;//图像的维度 确定用2维或者3维卷积核
CHECK_GE(num_spatial_axes_, 0);
vector<int> bottom_dim_blob_shape(1, num_spatial_axes_ + 1);//输入维度
vector<int> spatial_dim_blob_shape(1, std::max(num_spatial_axes_, 1));
// Setup filter kernel dimensions (kernel_shape_).
kernel_shape_.Reshape(spatial_dim_blob_shape);//根据输入图像的空间维度初始化kernel维度信息
int* kernel_shape_data = kernel_shape_.mutable_cpu_data();
if (conv_param.has_kernel_h() || conv_param.has_kernel_w()) {//如果参数设定了核大小
CHECK_EQ(num_spatial_axes_, 2)
<< "kernel_h & kernel_w can only be used for 2D convolution.";
CHECK_EQ(0, conv_param.kernel_size_size())
<< "Either kernel_size or kernel_h/w should be specified; not both.";
//初始化尺寸3×3或者n×n,kernel_h & kernel_w只能表示二维
kernel_shape_data[0] = conv_param.kernel_h();
kernel_shape_data[1] = conv_param.kernel_w();
} else {//2维以上的情况
const int num_kernel_dims = conv_param.kernel_size_size();
CHECK(num_kernel_dims == 1 || num_kernel_dims == num_spatial_axes_)
<< "kernel_size must be specified once, or once per spatial dimension "
<< "(kernel_size specified " << num_kernel_dims << " times; "
<< num_spatial_axes_ << " spatial dims).";
for (int i = 0; i < num_spatial_axes_; ++i) {
kernel_shape_data[i] =
conv_param.kernel_size((num_kernel_dims == 1) ? 0 : i);//三维时的维度信息
}
}
for (int i = 0; i < num_spatial_axes_; ++i) {
CHECK_GT(kernel_shape_data[i], 0) << "Filter dimensions must be nonzero.";
}
//步长(stride_).
stride_.Reshape(spatial_dim_blob_shape);
int* stride_data = stride_.mutable_cpu_data();
if (conv_param.has_stride_h() || conv_param.has_stride_w()) {
CHECK_EQ(num_spatial_axes_, 2)
<< "stride_h & stride_w can only be used for 2D convolution.";
CHECK_EQ(0, conv_param.stride_size())
<< "Either stride or stride_h/w should be specified; not both.";
stride_data[0] = conv_param.stride_h();
stride_data[1] = conv_param.stride_w();
} else {
const int num_stride_dims = conv_param.stride_size();
CHECK(num_stride_dims == 0 || num_stride_dims == 1 ||
num_stride_dims == num_spatial_axes_)
<< "stride must be specified once, or once per spatial dimension "
<< "(stride specified " << num_stride_dims << " times; "
<< num_spatial_axes_ << " spatial dims).";
const int kDefaultStride = 1;
for (int i = 0; i < num_spatial_axes_; ++i) {
stride_data[i] = (num_stride_dims == 0) ? kDefaultStride :
conv_param.stride((num_stride_dims == 1) ? 0 : i);
CHECK_GT(stride_data[i], 0) << "Stride dimensions must be nonzero.";
}
}
// 填充(pad_).
pad_.Reshape(spatial_dim_blob_shape);
int* pad_data = pad_.mutable_cpu_data();
if (conv_param.has_pad_h() || conv_param.has_pad_w()) {
CHECK_EQ(num_spatial_axes_, 2)
<< "pad_h & pad_w can only be used for 2D convolution.";
CHECK_EQ(0, conv_param.pad_size())
<< "Either pad or pad_h/w should be specified; not both.";
pad_data[0] = conv_param.pad_h();
pad_data[1] = conv_param.pad_w();
} else {
const int num_pad_dims = conv_param.pad_size();
CHECK(num_pad_dims == 0 || num_pad_dims == 1 ||
num_pad_dims == num_spatial_axes_)
<< "pad must be specified once, or once per spatial dimension "
<< "(pad specified " << num_pad_dims << " times; "
<< num_spatial_axes_ << " spatial dims).";
const int kDefaultPad = 0;
for (int i = 0; i < num_spatial_axes_; ++i) {
pad_data[i] = (num_pad_dims == 0) ? kDefaultPad :
conv_param.pad((num_pad_dims == 1) ? 0 : i);
}
}
// 扩展(dilation_).
dilation_.Reshape(spatial_dim_blob_shape);
int* dilation_data = dilation_.mutable_cpu_data();
const int num_dilation_dims = conv_param.dilation_size();
CHECK(num_dilation_dims == 0 || num_dilation_dims == 1 ||
num_dilation_dims == num_spatial_axes_)
<< "dilation must be specified once, or once per spatial dimension "
<< "(dilation specified " << num_dilation_dims << " times; "
<< num_spatial_axes_ << " spatial dims).";
const int kDefaultDilation = 1;
for (int i = 0; i < num_spatial_axes_; ++i) {
dilation_data[i] = (num_dilation_dims == 0) ? kDefaultDilation :
conv_param.dilation((num_dilation_dims == 1) ? 0 : i);
}
//对于1×1的卷积核默认步长为1,没有填充
is_1x1_ = true;
for (int i = 0; i < num_spatial_axes_; ++i) {
is_1x1_ &=
kernel_shape_data[i] == 1 && stride_data[i] == 1 && pad_data[i] == 0;
if (!is_1x1_) { break; }
}
// 配置输出通道和组别信息
channels_ = bottom[0]->shape(channel_axis_);//输入通道数
num_output_ = this->layer_param_.convolution_param().num_output();//输出个数
CHECK_GT(num_output_, 0);
group_ = this->layer_param_.convolution_param().group();//分组情况
CHECK_EQ(channels_ % group_, 0);
CHECK_EQ(num_output_ % group_, 0)
<< "Number of output should be multiples of group.";
if (reverse_dimensions()) {
conv_out_channels_ = channels_;
conv_in_channels_ = num_output_;
} else {
conv_out_channels_ = num_output_;//正常情况,输出通道数为输出的个数
conv_in_channels_ = channels_;//卷积核的通道数和输入是相同的,计算将互相消除。
}
// Handle the parameters: weights and biases.
// - blobs_[0] 卷积核的权值
// - blobs_[1] 偏置(optional)
vector<int> weight_shape(2);
//后面计算的时候weight是个conv_out_channels_*(conv_in_channels_ / group_*kernel_h*kernel_w)的矩阵
weight_shape[0] = conv_out_channels_;// num_output_
weight_shape[1] = conv_in_channels_ / group_;
for (int i = 0; i < num_spatial_axes_; ++i) {
weight_shape.push_back(kernel_shape_data[i]);
}
bias_term_ = this->layer_param_.convolution_param().bias_term();
vector<int> bias_shape(bias_term_, num_output_);
if (this->blobs_.size() > 0) {
CHECK_EQ(1 + bias_term_, this->blobs_.size())
<< "Incorrect number of weight blobs.";
if (weight_shape != this->blobs_[0]->shape()) {
Blob<Dtype> weight_shaped_blob(weight_shape);
LOG(FATAL) << "Incorrect weight shape: expected shape "
<< weight_shaped_blob.shape_string() << "; instead, shape was "
<< this->blobs_[0]->shape_string();
}
if (bias_term_ && bias_shape != this->blobs_[1]->shape()) {
Blob<Dtype> bias_shaped_blob(bias_shape);
LOG(FATAL) << "Incorrect bias shape: expected shape "
<< bias_shaped_blob.shape_string() << "; instead, shape was "
<< this->blobs_[1]->shape_string();
}
LOG(INFO) << "Skipping parameter initialization";
} else {
if (bias_term_) {
this->blobs_.resize(2);
} else {
this->blobs_.resize(1);
}
// 初始化权重矩阵:
// output channels x input channels per-group x kernel height x kernel width
this->blobs_[0].reset(new Blob<Dtype>(weight_shape));
shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>(
this->layer_param_.convolution_param().weight_filler()));
weight_filler->Fill(this->blobs_[0].get());
// 如果设置了偏置项,则初始化
if (bias_term_) {
this->blobs_[1].reset(new Blob<Dtype>(bias_shape));
shared_ptr<Filler<Dtype> > bias_filler(GetFiller<Dtype>(
this->layer_param_.convolution_param().bias_filler()));
bias_filler->Fill(this->blobs_[1].get());
}
}
kernel_dim_ = this->blobs_[0]->count(1<
10b57
/span>);
weight_offset_ = conv_out_channels_ * kernel_dim_ / group_;//分组偏移量
// Propagate gradients to the parameters (as directed by backward pass).
this->param_propagate_down_.resize(this->blobs_.size(), true);
}c、reshape函数
根据输入重塑输出的形状
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const int first_spatial_axis = channel_axis_ + 1;//数据的维度:2d或者3d
CHECK_EQ(bottom[0]->num_axes(), first_spatial_axis + num_spatial_axes_)
<< "bottom num_axes may not change.";
//num = batch_size
num_ = bottom[0]->count(0, channel_axis_);
CHECK_EQ(bottom[0]->shape(channel_axis_), channels_)
<< "Input size incompatible with convolution kernel.";
// TODO: generalize to handle inputs of different shapes.
for (int bottom_id = 1; bottom_id < bottom.size(); ++bottom_id) {
CHECK(bottom[0]->shape() == bottom[bottom_id]->shape())//所有的输入都必须有一样的维度
<< "All inputs must have the same shape.";
}
// Shape the tops.
//top_shape=(batch_size,num_output_,kernel_h,kernel_w)
bottom_shape_ = &bottom[0]->shape();//获得输入的shape_容器
compute_output_shape();
vector<int> top_shape(bottom[0]->shape().begin(),
bottom[0]->shape().begin() + channel_axis_);//top_shape=(batch_size)
top_shape.push_back(num_output_);//top_shape=(batch_size,num_output)
for (int i = 0; i < num_spatial_axes_; ++i) {
top_shape.push_back(output_shape_[i]);
//top_shape=(batch_size,num_output,top_spatil[0],top_spatil[1]...top_spatil[i])
}
for (int top_id = 0; top_id < top.size(); ++top_id) {
top[top_id]->Reshape(top_shape);
}//多个输出的情况
if (reverse_dimensions()) {
conv_out_spatial_dim_ = bottom[0]->count(first_spatial_axis);//输入图像H×输入图像W
} else {
conv_out_spatial_dim_ = top[0]->count(first_spatial_axis);//输出图像H×输出图像W
}
//img2col是针对单独的一个图像数据的操作
col_offset_ = kernel_dim_ * conv_out_spatial_dim_;
output_offset_ = conv_out_channels_ * conv_out_spatial_dim_ / group_;
// Setup input dimensions (conv_input_shape_).
vector<int> bottom_dim_blob_shape(1, num_spatial_axes_ + 1);
conv_input_shape_.Reshape(bottom_dim_blob_shape);
int* conv_input_shape_data = conv_input_shape_.mutable_cpu_data();
for (int i = 0; i < num_spatial_axes_ + 1; ++i) {
if (reverse_dimensions()) {
conv_input_shape_data[i] = top[0]->shape(channel_axis_ + i);
} else {
conv_input_shape_data[i] = bottom[0]->shape(channel_axis_ + i);
}
}
col_buffer_shape_.clear();
col_buffer_shape_.push_back(kernel_dim_ * group_);
for (int i = 0; i < num_spatial_axes_; ++i) {
if (reverse_dimensions()) {
col_buffer_shape_.push_back(input_shape(i + 1));
} else {
col_buffer_shape_.push_back(output_shape_[i]);
}
}
col_buffer_.Reshape(col_buffer_shape_);
bottom_dim_ = bottom[0]->count(channel_axis_);
top_dim_ = top[0]->count(channel_axis_);
num_kernels_im2col_ = conv_in_channels_ * conv_out_spatial_dim_;
num_kernels_col2im_ = reverse_dimensions() ? top_dim_ : bottom_dim_;
out_spatial_dim_ = top[0]->count(first_spatial_axis);
if (bias_term_) {
vector<int> bias_multiplier_shape(1, out_spatial_dim_);
bias_multiplier_.Reshape(bias_multiplier_shape);
caffe_set(bias_multiplier_.count(), Dtype(1),
bias_multiplier_.mutable_cpu_data());
}
}d、前向计算
卷积层的前向计算大体如下:
其中最重要的是函数conv_im2col_gpu。
转换成矩阵后就调用cblas函caffe_gpu_gemm
所以,卷积的具体实现就是:
1、使用im2col分别将featrue maps 以及卷积核转换成矩阵 2、调用GEMM(GEneralized Matrix Multiplication)对两矩阵内积。
输入图像为(C通道数,H图像高度,W图像宽度)
转换为列表示:
每一单列为:C×K×K
列的行数就是卷积核在图像上的滑动次数(输出图像高×输出图像宽)
卷积核的表示:
Cout×C×K×K转换后变为Cout个C×K×K列
两者做内积,最后得到输出为:
Cout×(输出图像高,输出图像宽)的矩阵
img2col的具体实现:
按照channel*kernel_h*kernel_w一列,将一个channel x kernel_h x kernel_w 大小的图像块变成一个列。
有多少个这样的列呢,这就可以用公式进行计算
列数 = [(图像高度+2*填充高度-kernel高度)/stride高度+1] * [(图像宽度+2*填充宽度-kernel宽度)/stride宽度+1]
这个行数就是一个kernel大小的图像块的维度
这个列数实际上就是kernel在图像上滑动的次数
template <typename Dtype>
__global__ void im2col_gpu_kernel(const int n, const Dtype* data_im,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
const int dilation_h, const int dilation_w,
const int height_col, const int width_col,
Dtype* data_col) {
CUDA_KERNEL_LOOP(index, n) {//CUDA循环,主要是保证每次循环每个线程都参与计算
const int h_index = index / width_col;
const int h_col = h_index % height_col;//原图像的高变为列后的对应的坐标
const int w_col = index % width_col;//原图像的宽变为列后的对应的坐标,谨记是行优先
const int c_im = h_index / height_col;//原图像对应通道
const int c_col = c_im * kernel_h * kernel_w;//变换后的列的长度
const int h_offset = h_col * stride_h - pad_h;//对应原图像中的高
const int w_offset = w_col * stride_w - pad_w;//对应原图像的宽
Dtype* data_col_ptr = data_col;//数据缓存
data_col_ptr += (c_col * height_col + h_col) * width_col + w_col;//列的内存地址计算
const Dtype* data_im_ptr = data_im;
data_im_ptr += (c_im * height + h_offset) * width + w_offset;//原图像的内存地址计算
// 卷积之后的图像与卷积之前的图像像素所对应的位置
// 卷积之后的像素为h和w那么所对应的原图像的位置为 [h * stride_h - pad_h, h * stride_h - pad_h+kernel_h]以及
// [w * stride_w - pad_w, w * stride_w - pad_w+kernel_w]
for (int i = 0; i < kernel_h; ++i) {
for (int j = 0; j < kernel_w; ++j) {
int h_im = h_offset + i * dilation_h;
int w_im = w_offset + j * dilation_w;
*data_col_ptr =
(h_im >= 0 && w_im >= 0 && h_im < height && w_im < width) ?
data_im_ptr[i * dilation_h * width + j * dilation_w] : 0;//图像和列之间的数据转换,超出图像的区域直接记为0
data_col_ptr += height_col * width_col;//一列完毕就跳到下一列
}
}
}
}完成转换之后就直接调用gemm函数进行矩阵的内积
首先是卷积核与输入的计算:
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::forward_gpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
const Dtype* col_buff = input;//输入缓存
if (!is_1x1_) {//1*1卷积不需要转换
if (!skip_im2col) {
conv_im2col_gpu(input, col_buffer_.mutable_gpu_data());//将二维或者三维图像转换为列
}
col_buff = col_buffer_.gpu_data();
}
for (int g = 0; g < group_; ++g) {
//conv_out_channels_ / group_是每个卷积组的输出的channel
//kernel_dim_ = input channels per-group x kernel height x kernel width
//计算的是output[output_offset_ * g] =
// weights[weight_offset_ * g] X col_buff[col_offset_ * g]
// weights的形状是 [conv_out_channel x kernel_dim_]
// col_buff的形状是[kernel_dim_ x (卷积后图像高度乘以卷积后图像宽度)]
// 所以output的形状自然就是conv_out_channel X (卷积后图像高度乘以卷积后图像宽度)
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
group_, conv_out_spatial_dim_, kernel_dim_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
}
}如果需要加上偏置项:
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::forward_gpu_bias(Dtype* output,
const Dtype* bias) {
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num_output_,
out_spatial_dim_, 1, (Dtype)1., bias, bias_multiplier_.gpu_data(),
(Dtype)1., output);
}e、后向计算
后向计算同样是矩阵的内积,只是输入和输出倒置
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::backward_gpu_gemm(const Dtype* output,
const Dtype* weights, Dtype* input) {
Dtype* col_buff = col_buffer_.mutable_gpu_data();
if (is_1x1_) {
col_buff = input;
}
for (int g = 0; g < group_; ++g) {
caffe_gpu_gemm<Dtype>(CblasTrans, CblasNoTrans, kernel_dim_,
conv_out_spatial_dim_, conv_out_channels_ / group_,
(Dtype)1., weights + weight_offset_ * g, output + output_offset_ * g,
(Dtype)0., col_buff + col_offset_ * g);
}
if (!is_1x1_) {
conv_col2im_gpu(col_buff, input);
}
}三、conv_layer
conv_layer继承自base_conv_layer,需要自己实现的函数只有三个。一个是base_conv_layer的纯虚函数compute_output_shape(),一个是前向计算函数,最后是后向计算函数。
compute_output_shape()
template <typename Dtype>
void ConvolutionLayer<Dtype>::compute_output_shape() {
const int* kernel_shape_data = this->kernel_shape_.cpu_data();
const int* stride_data = this->stride_.cpu_data();
const int* pad_data = this->pad_.cpu_data();
const int* dilation_data = this->dilation_.cpu_data();
this->output_shape_.clear();
for (int i = 0; i < this->num_spatial_axes_; ++i) {
// i + 1 to skip channel axis
//卷积后的图像数据的维度=(input_dim + 2 * pad_data[i] - (dilation_data[i] * (kernel_shape_data[i] - 1) + 1))
const int input_dim = this->input_shape(i + 1);
const int kernel_extent = dilation_data[i] * (kernel_shape_data[i] - 1) + 1;
const int output_dim = (input_dim + 2 * pad_data[i] - kernel_extent)
/ stride_data[i] + 1;//
this->output_shape_.push_back(output_dim);
}
}cpu模式下的前向计算(就是调用基类的forward_cpu_gemm,没啥可说的)
template <typename Dtype>
void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* weight = this->blobs_[0]->cpu_data();
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* top_data = top[i]->mutable_cpu_data();
for (int n = 0; n < this->num_; ++n) {
this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight,
top_data + n * this->top_dim_);
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + n * this->top_dim_, bias);
}
}
}
}cpu模式下的后向计算
template <typename Dtype>
void ConvolutionLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
const Dtype* weight = this->blobs_[0]->cpu_data();
Dtype* weight_diff = this->blobs_[0]->mutable_cpu_diff();
for (int i = 0; i < top.size(); ++i) {
const Dtype* top_diff = top[i]->cpu_diff();
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* bottom_diff = bottom[i]->mutable_cpu_diff();
// Bias gradient, if necessary.
if (this->bias_term_ && this->param_propagate_down_[1]) {
Dtype* bias_diff = this->blobs_[1]->mutable_cpu_diff();
for (int n = 0; n < this->num_; ++n) {
this->backward_cpu_bias(bias_diff, top_diff + n * this->top_dim_);
}
}
if (this->param_propagate_down_[0] || propagate_down[i]) {
for (int n = 0; n < this->num_; ++n) {
// gradient w.r.t. weight. Note that we will accumulate diffs.
if (this->param_propagate_down_[0]) {
this->weight_cpu_gemm(bottom_data + n * this->bottom_dim_,
top_diff + n * this->top_dim_, weight_diff);
}
// gradient w.r.t. bottom data, if necessary.
if (propagate_down[i]) {
this->backward_cpu_gemm(top_diff + n * this->top_dim_, weight,
bottom_diff + n * this->bottom_dim_);
}
}
}
}
}四、总结
借助对卷积层的分析,理解了作者的一个实现技巧,同时也是对输入输出,卷积核的维度信息有了更深刻的理解。

相关文章推荐
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之七-layer_factory以及layer基类
- CAFFE源码学习笔记之七-layer_factory以及layer基类
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之七-layer_factory以及layer基类
- CAFFE源码学习笔记之七-layer_factory以及layer基类
- CAFFE源码学习笔记之七-layer_factory以及layer基类
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之内积层-inner_product_layer