逻辑回归算法原理及Spark MLlib调用实例(Scala/Java/python)
2016-12-01 11:41
911 查看
逻辑回归
算法原理:
逻辑回归是一个流行的二分类问题预测方法。它是Generalized
Linear models 的一个特殊应用以预测结果概率。它是一个线性模型如下列方程所示,其中损失函数为逻辑损失:
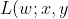:%20=%20%5Clog%20(1%20+%20%5Cexp%20(%20-%20y%7Bw%5ET%7Dx)))
对于二分类问题,算法产出一个二值逻辑回归模型。给定一个新数据,由x表示,则模型通过下列逻辑方程来预测:
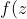%20=%20%5Cfrac%7B1%7D%7B%7B1%20+%20%7Be%5E%7B%20-%20z%7D%7D%7D%7D)
其中
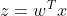
。默认情况下,如果
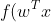%20)
,结果为正,否则为负。和线性SVMs不同,逻辑回归的原始输出有概率解释(x为正的概率)。
二分类逻辑回归可以扩展为多分类逻辑回归来训练和预测多类别分类问题。如一个分类问题有K种可能结果,我们可以选取其中一种结果作为“中心点“,其他K-1个结果分别视为中心点结果的对立点。在spark.mllib中,取第一个类别为中心点类别。
*目前spark.ml逻辑回归工具仅支持二分类问题,多分类回归将在未来完善。
*当使用无拦截的连续非零列训练LogisticRegressionModel时,Spark MLlib为连续非零列输出零系数。这种处理不同于libsvm与R glmnet相似。
参数:
elasticNetParam:
类型:双精度型。
含义:弹性网络混合参数,范围[0,1]。
featuresCol:
类型:字符串型。
含义:特征列名。
fitIntercept:
类型:布尔型。
含义:是否训练拦截对象。
labelCol:
类型:字符串型。
含义:标签列名。
maxIter:
类型:整数型。
含义:最多迭代次数(>=0)。
predictionCol:
类型:字符串型。
含义:预测结果列名。
probabilityCol:
类型:字符串型。
含义:用以预测类别条件概率的列名。
regParam:
类型:双精度型。
含义:正则化参数(>=0)。
standardization:
类型:布尔型。
含义:训练模型前是否需要对训练特征进行标准化处理。
threshold:
类型:双精度型。
含义:二分类预测的阀值,范围[0,1]。
thresholds:
类型:双精度数组型。
含义:多分类预测的阀值,以调整预测结果在各个类别的概率。
tol:
类型:双精度型。
含义:迭代算法的收敛性。
weightCol:
类型:字符串型。
含义:列权重。
示例:
下面的例子展示如何训练使用弹性网络正则化的逻辑回归模型。elasticNetParam对应于
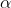
,regParam对应于
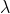
。
Scala:
spark.ml逻辑回归工具同样支持提取模总结。LogisticRegressionTrainingSummary提供LogisticRegressionModel的总结。目前仅支持二分类问题,所以总结必须明确投掷到BinaryLogisticRegressionTrainingSummary。支持多分类问题后可能有所改善。
继续上面的例子:
Scala:
算法原理:
逻辑回归是一个流行的二分类问题预测方法。它是Generalized
Linear models 的一个特殊应用以预测结果概率。它是一个线性模型如下列方程所示,其中损失函数为逻辑损失:
对于二分类问题,算法产出一个二值逻辑回归模型。给定一个新数据,由x表示,则模型通过下列逻辑方程来预测:
其中
。默认情况下,如果
,结果为正,否则为负。和线性SVMs不同,逻辑回归的原始输出有概率解释(x为正的概率)。
二分类逻辑回归可以扩展为多分类逻辑回归来训练和预测多类别分类问题。如一个分类问题有K种可能结果,我们可以选取其中一种结果作为“中心点“,其他K-1个结果分别视为中心点结果的对立点。在spark.mllib中,取第一个类别为中心点类别。
*目前spark.ml逻辑回归工具仅支持二分类问题,多分类回归将在未来完善。
*当使用无拦截的连续非零列训练LogisticRegressionModel时,Spark MLlib为连续非零列输出零系数。这种处理不同于libsvm与R glmnet相似。
参数:
elasticNetParam:
类型:双精度型。
含义:弹性网络混合参数,范围[0,1]。
featuresCol:
类型:字符串型。
含义:特征列名。
fitIntercept:
类型:布尔型。
含义:是否训练拦截对象。
labelCol:
类型:字符串型。
含义:标签列名。
maxIter:
类型:整数型。
含义:最多迭代次数(>=0)。
predictionCol:
类型:字符串型。
含义:预测结果列名。
probabilityCol:
类型:字符串型。
含义:用以预测类别条件概率的列名。
regParam:
类型:双精度型。
含义:正则化参数(>=0)。
standardization:
类型:布尔型。
含义:训练模型前是否需要对训练特征进行标准化处理。
threshold:
类型:双精度型。
含义:二分类预测的阀值,范围[0,1]。
thresholds:
类型:双精度数组型。
含义:多分类预测的阀值,以调整预测结果在各个类别的概率。
tol:
类型:双精度型。
含义:迭代算法的收敛性。
weightCol:
类型:字符串型。
含义:列权重。
示例:
下面的例子展示如何训练使用弹性网络正则化的逻辑回归模型。elasticNetParam对应于
,regParam对应于
。
Scala:
import org.apache.spark.ml.classification.LogisticRegression
// Load training data
val training = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0.8)
// Fit the model
val lrModel = lr.fit(training)
// Print the coefficients and intercept for logistic regression
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}")Java:import org.apache.spark.ml.classification.LogisticRegression;
import org.apache.spark.ml.classification.LogisticRegressionModel;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
// Load training data
Dataset<Row> training = spark.read().format("libsvm")
.load("data/mllib/sample_libsvm_data.txt");
LogisticRegression lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0.8);
// Fit the model
LogisticRegressionModel lrModel = lr.fit(training);
// Print the coefficients and intercept for logistic regression
System.out.println("Coefficients: "
+ lrModel.coefficients() + " Intercept: " + lrModel.intercept());Python:from pyspark.ml.classification import LogisticRegression
# Load training data
training = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
lr = LogisticRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)
# Fit the model
lrModel = lr.fit(training)
# Print the coefficients and intercept for logistic regression
print("Coefficients: " + str(lrModel.coefficients))
print("Intercept: " + str(lrModel.intercept))spark.ml逻辑回归工具同样支持提取模总结。LogisticRegressionTrainingSummary提供LogisticRegressionModel的总结。目前仅支持二分类问题,所以总结必须明确投掷到BinaryLogisticRegressionTrainingSummary。支持多分类问题后可能有所改善。
继续上面的例子:
Scala:
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.DecisionTreeClassificationModel
import org.apache.spark.ml.classification.DecisionTreeClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{IndexToString, StringIndexer, VectorIndexer}
// Load the data stored in LIBSVM format as a DataFrame.
val data = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
// Index labels, adding metadata to the label column.
// Fit on whole dataset to include all labels in index.
val labelIndexer = new StringIndexer()
.setInputCol("label")
.setOutputCol("indexedLabel")
.fit(data)
// Automatically identify categorical features, and index them.
val featureIndexer = new VectorIndexer()
.setInputCol("features")
.setOutputCol("indexedFeatures")
.setMaxCategories(4) // features with > 4 distinct values are treated as continuous.
.fit(data)
// Split the data into training and test sets (30% held out for testing).
val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3))
// Train a DecisionTree model.
val dt = new DecisionTreeClassifier()
.setLabelCol("indexedLabel")
.setFeaturesCol("indexedFeatures")
// Convert indexed labels back to original labels.
val labelConverter = new IndexToString()
.setInputCol("prediction")
.setOutputCol("predictedLabel")
.setLabels(labelIndexer.labels)
// Chain indexers and tree in a Pipeline.
val pipeline = new Pipeline()
.setStages(Array(labelIndexer, featureIndexer, dt, labelConverter))
// Train model. This also runs the indexers.
val model = pipeline.fit(trainingData)
// Make predictions.
val predictions = model.transform(testData)
// Select example rows to display.
predictions.select("predictedLabel", "label", "features").show(5)
// Select (prediction, true label) and compute test error.
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator.evaluate(predictions)
println("Test Error = " + (1.0 - accuracy))
val treeModel = model.stages(2).asInstanceOf[DecisionTreeClassificationModel]
println("Learned classification tree model:\n" + treeModel.toDebugString)Java:import org.apache.spark.ml.Pipeline;
import org.apache.spark.ml.PipelineModel;
import org.apache.spark.ml.PipelineStage;
import org.apache.spark.ml.classification.DecisionTreeClassifier;
import org.apache.spark.ml.classification.DecisionTreeClassificationModel;
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator;
import org.apache.spark.ml.feature.*;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
// Load the data stored in LIBSVM format as a DataFrame.
Dataset<Row> data = spark
.read()
.format("libsvm")
.load("data/mllib/sample_libsvm_data.txt");
// Index labels, adding metadata to the label column.
// Fit on whole dataset to include all labels in index.
StringIndexerModel labelIndexer = new StringIndexer()
.setInputCol("label")
.setOutputCol("indexedLabel")
.fit(data);
// Automatically identify categorical features, and index them.
VectorIndexerModel featureIndexer = new VectorIndexer()
.setInputCol("features")
.setOutputCol("indexedFeatures")
.setMaxCategories(4) // features with > 4 distinct values are treated as continuous.
.fit(data);
// Split the data into training and test sets (30% held out for testing).
Dataset<Row>[] splits = data.randomSplit(new double[]{0.7, 0.3});
Dataset<Row> trainingData = splits[0];
Dataset<Row> testData = splits[1];
// Train a DecisionTree model.
DecisionTreeClassifier dt = new DecisionTreeClassifier()
.setLabelCol("indexedLabel")
.setFeaturesCol("indexedFeatures");
// Convert indexed labels back to original labels.
IndexToString labelConverter = new IndexToString()
.setInputCol("prediction")
.setOutputCol("predictedLabel")
.setLabels(labelIndexer.labels());
// Chain indexers and tree in a Pipeline.
Pipeline pipeline = new Pipeline()
.setStages(new PipelineStage[]{labelIndexer, featureIndexer, dt, labelConverter});
// Train model. This also runs the indexers.
PipelineModel model = pipeline.fit(trainingData);
// Make predictions.
Dataset<Row> predictions = model.transform(testData);
// Select example rows to display.
predictions.select("predictedLabel", "label", "features").show(5);
// Select (prediction, true label) and compute test error.
MulticlassClassificationEvaluator evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel")
.setPredictionCol("prediction")
.setMetricName("accuracy");
double accuracy = evaluator.evaluate(predictions);
System.out.println("Test Error = " + (1.0 - accuracy));
DecisionTreeClassificationModel treeModel =
(DecisionTreeClassificationModel) (model.stages()[2]);
System.out.println("Learned classification tree model:\n" + treeModel.toDebugString());

相关文章推荐
- 逻辑回归算法原理及Spark MLlib调用实例(Scala/Java/python)
- 决策树回归算法原理及Spark MLlib调用实例(Scala/Java/python)
- 梯度迭代树回归(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python)
- 生存回归(加速失效时间模型)算法原理及Spark MLlib调用实例(Scala/Java/python)
- 随机森林回归(Random Forest)算法原理及Spark MLlib调用实例(Scala/Java/python)
- 随机森林(Random Forest)算法原理及Spark MLlib调用实例(Scala/Java/python)
- 梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python)
- 梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python)
- scala---文档主题生成模型(LDA)算法原理及Spark MLlib调用实例(Scala/Java/python)
- K均值(K-means)算法原理及Spark MLlib调用实例(Scala/Java/python)
- 梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python)
- 广义线性模型(GLMs)算法原理及Spark MLlib调用实例(Scala/Java/Python)
- 协同过滤(ALS)算法原理及Spark MLlib调用实例(Scala/Java/Python)
- 二分K均值算法原理及Spark MLlib调用实例(Scala/Java/Python)
- 文档主题生成模型(LDA)算法原理及Spark MLlib调用实例(Scala/Java/python)
- 朴素贝叶斯算法原理及Spark MLlib调用实例(Scala/Java/Python)
- 多层感知机(MLP)算法原理及Spark MLlib调用实例(Scala/Java/Python)
- MLlib--多层感知机(MLP)算法原理及Spark MLlib调用实例(Scala/Java/Python)
- 保序回归算法原理及Spark MLlib调用实例(Scala/Java/python)
- 决策树算法原理及Spark MLlib调用实例(Scala/Java/python)