George Hotz 自动驾驶 深度学习
2016-11-26 13:32
246 查看
George Hotz:请收下我的智驾系统代码(附论文)
举报1 新智元原创
【新智元导读】我知道以GeoHot的脾气,最终 comma.ai 全套AI模型的代码肯定会被他开源,但我没想到会这么快,而且我也没想到这么完备,几乎毫无保留,多达80G的驾驶数据,模型以及论文全部开放,黑客精神在这位老兄身上的到了淋漓尽致的体现。本文结合GeoHot此次发表的论文和代码,讲解此前为Bloomberg演示时所采用的深度学习框架。代码采用Python语言编写,涉及tensorflow,anaconda,cv2等多个常用深度学习常用开发框架,是不可多得的学习材料。

桀骜不逊的自动驾驶破局者
智驾深谈的第一期,就是关于这位老兄George Hotz,江湖人称GeoHot,“声名狼藉的”iPhone和PlayStation破解者,做过多家IT帝国的被告。几个月前研究上了自动驾驶技术,紧接着就公然挑战Tesla、Google和Mobileye,自嘲是个“智痴(I'm an Idiot.)”,而其他家的水平,只能算是智障。Musk发邮件邀请他去Tesla,被他拒了,声称自己年底就要出不到一万人民币的产品,而且效果绝对秒杀。四月初拿到了310万美元融资,并在拉斯维加斯正常车流中,GeoHot演示了目前的技术进展,完成度颇高,只用了一个前置摄像头,以及一个草草贴在前保险杠上的毫米波雷达。
深度学习端到端:开源概况
此前我提过,目前的自动驾驶技术可以划分为两类,一种是感知-决策-控制然后不断闭环,每个模块用不同的方法力争最好,很多情况下需要专家提供基于经验的规则。另一种则是GeoHot正在采用的办法,叫做End-to-End,端到端方法,指以摄像头的原始图像作为输入,直接输出车辆的速度和方向,中间用某种数学模型来拟合逼近最优驾驶策略,目前常用的就是深度学习模型。
本次GeoHot开源的东西非常丰富,包括下面几个内容:
七小时十五分的高速公路图像数据
两种使用该数据的机器学习实验方法
一篇利用深度学习RNN网络进行自动驾驶的论文 (在新智元公众平台回复0806下载)
整套试验代码包括tensorflow,anaconda,keras等常用工具的用法
这些材料,足够读者复现GeoHot为Bloomberg演示的效果,比起此前Mobileye或者Nvidia光发布论文前进了一大步。
深度学习端到端:数据准备

驾驶数据是本次开源的重要组成部分,不但包括前视摄像头裁剪的数据,共计7.25小时,分为11个视频,160*320大小,并且还包括了GeoHot那辆讴歌采集的转向、制动、速度以及惯导数据,以及图像输入和控制输出的同步时间戳数据。本次发布的论文主要聚焦在通过图像输入来学习控制转向和速度,GeoHot将图像缩小为80*160并将像素值归一化。
深度学习端到端:模型介绍
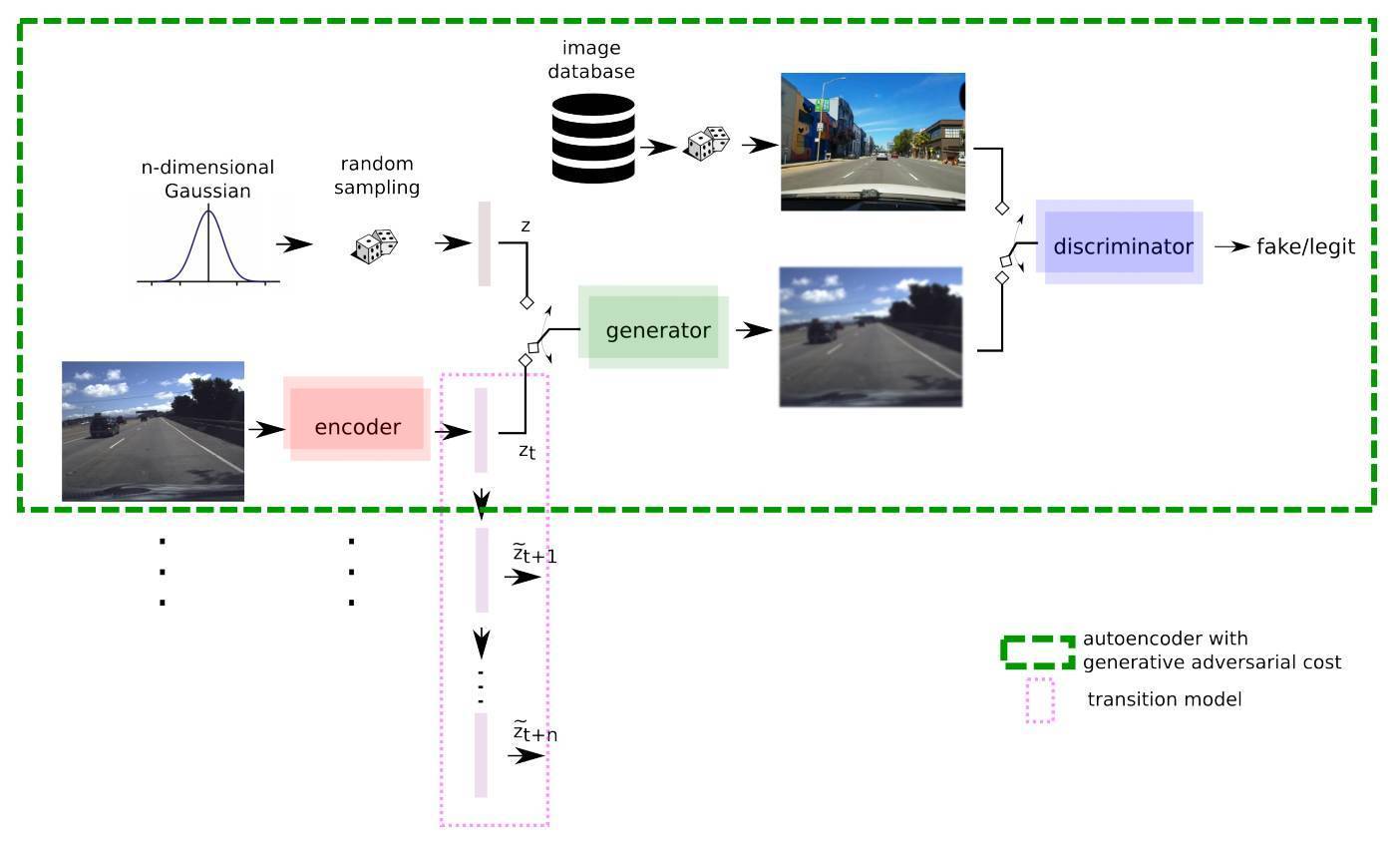
目前深度学习用于自动驾驶可以大概分为两类,一类是收集驾驶数据,离线训练模型,不断逼近人类驾驶员;另一类是在模拟器中,利用Q函数,不断自我决策和试错来提高驾驶技术。由于真正图片的复杂以及输出命令的连续性,使得现实世界中能够得到好结果比较困难,所以我们目前见到的很多都是在模拟器中尝试。
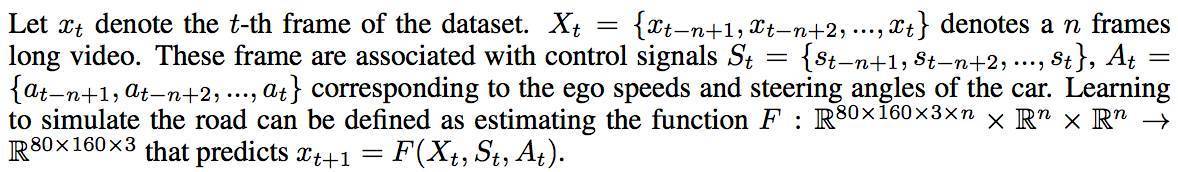
本次GeoHot开源的是第一种方法,且是在真实道路上经过实测的。其基本原理是,将摄像头获得的图像数据,利用Autoencoder编码(如上图锁匙,期间还用到最近很火的GAN),然后用一个RNN深度网络来从人类驾驶数据中学习,最终预测下一步操作。
深度学习端到端:代码概要
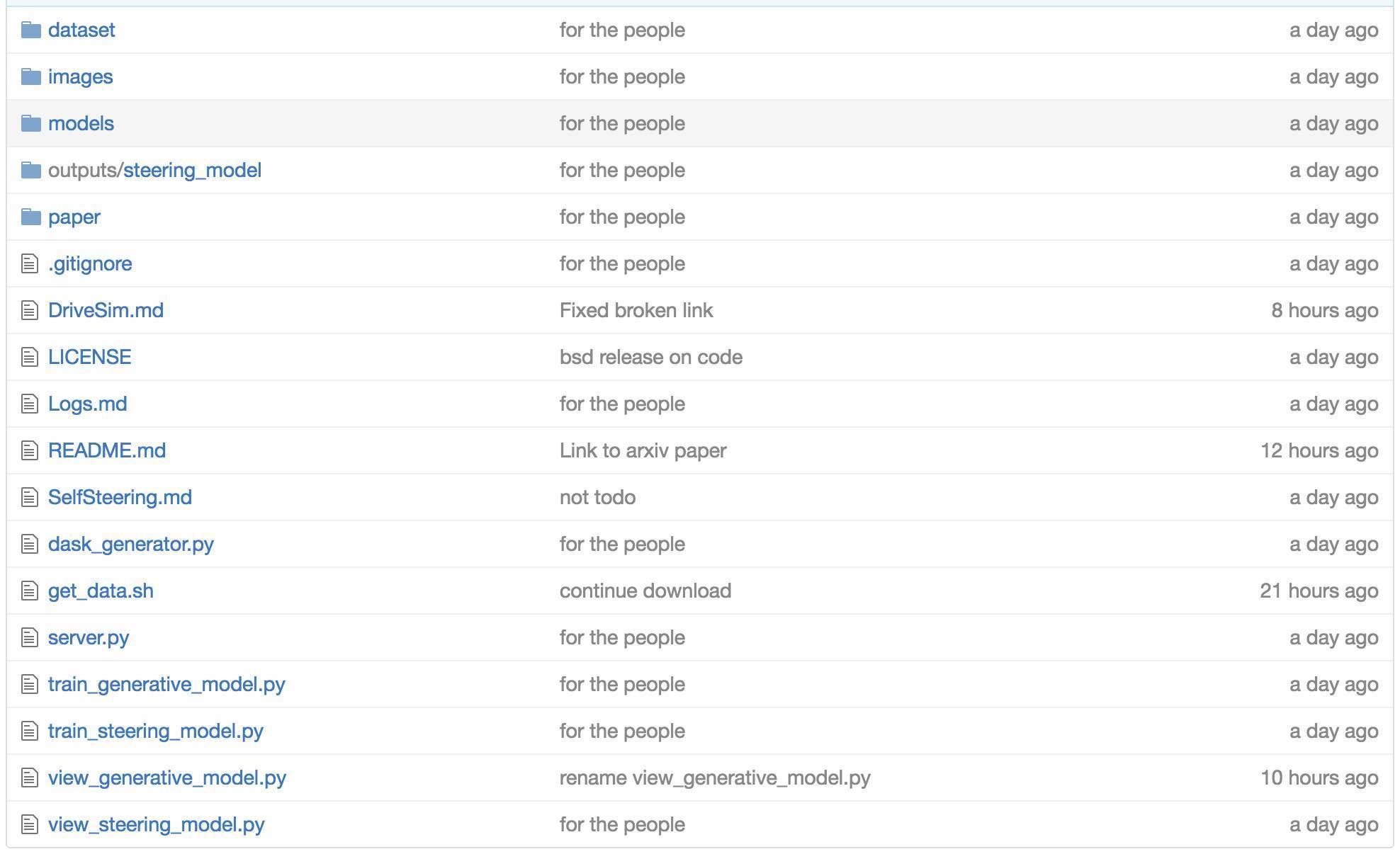
从代码结构上来看,大概可以分为数据、模型和训练框架三部分,其中模型部分包括了autoencoder和RNN,训练框架则以server.py文件作为入口。
结语
我非常惊讶于GeoHot做出这次开源的决定,看过论文和代码之后,相信复现他们演示结果并不是一件很难的事情,算是让大部分想要尝试深度智驾模型而又无从下手的人得到了福利。那么开源是否会对整个智驾产业带来影响呢?如果你觉得GeoHot还不够强的话,Google未来开源了会不会有影响呢?谁也很难说智驾不会像智能手机一样,成为下一个兵家必争之地。
新智元Top10智能汽车创客大赛招募!
新智元于7月11日启动2016年【新智元100】人工智能创业公司评选,在人工智能概念诞生60周年之际,寻找中国最具竞争力的人工智能创业企业。
智能驾驶技术是汽车行业的重点发展方向之一,同时也是人工智能相关产业创新落地的重要赛道之一。为此新智元联合北京中汽四方共同举办“新智元Top10智能汽车创客大赛”,共同招募智能汽车相关优质创业公司,并联合组织人工智能技术专家、传统汽车行业技术专家、关注智能汽车领域的知名风投机构,共同评审并筛选出Top 10进入决赛,在2016年10月16日“国际智能网联汽车发展合作论坛”期间,进行路演、颁奖及展览活动。
GeoHot智驾系统开源这件事情还是很多人关注的,也问了很多问题,其中包括渐进式路线的车企,直接L4的互联网企业,很多创业团队和风投。先回答一个问到最多的问题:这代码离实际路上能用还差很多。
对于大公司来讲,车企做渐进式ADAS其实都是工况分解而来,流行使用状态机,深度模型是个黑盒子他们肯定不喜欢。
互联网企业愿意尝试新方法,但这个系统其实还需要在车辆控制方面做大量的改进才能够跟现有系统对标。
对于创业团队来讲,这个系统是个很好的参考,可以学习一下深度学习,以及comma.ai是如何短时间内聚焦并发力赢得投资人青睐的。
而对于风投来讲,要谨慎看待,AI创业团队有的很靠谱,而不靠谱的会特别不靠谱,比如直接用人家代码跑别的数据做展示,不冷静的投资人很可能会被忽悠投一笔。
下面的内容就都是程序啊论文啊代码啊,不感兴趣的可以撤退了。
具体怎么复现
先扯两句倒腾数据的情况,一般对于国外这种项目,下载很大的压缩包,普通人用浏览器、迅雷或者云盘等常规办法是很难快速拿到的,主要原因有两个,一个是直连速度太慢,另一个是往往国外网盘都需要代理访问。因此我一般习惯是在国外临时开一个VPS做中继,具体来讲就是AWS或者随便有海外机房的云服务提供商那里按小时买一个16M带宽主机,反正用一天就销毁了,最后不到五十块,成功拖回到赵师傅在学校的服务器上。有三个倒腾数据的命令值得一提:wget的continue断点续传模式,resync的-P断点续传模式,screen
–r把进程丢后台。
具体来讲,先来配置环境,赵师傅的服务器是这样的,所以跑的还挺快。
Ubuntu 14.04
Python 2.7
nVidia Geforce Titan X (12GB Memory)
软件的安装顺序建议Anaconda,tensorflow,keras,具体如下:


然后在Python中 import tensorflow看看是不是成功了

然后赵师傅做了几件事:
GeoHot代码:在训练集上train了一个转向控制模型
GeoHot代码:在测试集上validate了一下
赵师傅改进:在训练集上train了一个离散分类转向控制模型
赵师傅改进:在测试集上validate了一下

GeoHot原本的转向控制是个回归模型,整个训练大概用了六小时,而回归问题在深度学习中还尚且没有得到彻底解决,因此赵师傅给改了一下变成一个36桶的离散分类问题,softmax没跟loss层整合,分类用的是one-hot。

上图绿色是驾驶员数据,红色是模型输出数据。从最终的结果来看,两种方式在训练集上都表现不错,但测试集上都不太好。

主要原因可能是80G数据中有很多低速非典型的数据,会影响训练效果,比如上图中停在路边的例子。

赵师傅分析了一下九个视频中车速的情况,觉得后续尝试可以专门找车速大于一定阈值的片段,或者把低速模型跟高速模型分开,同时考虑速度和转向的训练。
论文有啥看点
然后哥几个讨论了一下论文,还扯了之前一些相关的工作吧。
首先,Geohot给出了两种在comma.ai数据集上的尝试,第一种是直接从图像回归驾驶员的操作(方向盘转角),第二种是预测(猜测)下一帧时车辆前置摄像头看到的图像。第一个任务一般被称为steering angle prediction,这个任务最早可以追溯到Dean A.Pomerleau在1989年和1992年发表的两篇文章(见下图)。当时还没有使用卷积网,使用的图像输入分辨率也很低,更没有标准的大规模公开数据集。

2005年Lecun的一项工作试图用卷积网解决这个问题,但是其数据集有以下几点值得改进的地方(以当前的自动驾驶标准看):(1)不公开;(2)不是在公路上拍摄的(off-road)。并且该文章并没有给出严格的定量实验,只是提供了如下的定性结果(蓝色输出,红色真值):

综上,总的来说,comma.ai是第一个公开的大规模的有着详细标注的可以用来研究steeringangle prediction的数据集。Geohot的文章给出了一些初步的探索,但并不是其强调的重点。
然后, Geohot的文章主要专注于解决第二个任务,即预测(猜测)下一帧时车辆前置摄像头看到的图像。该系统结合了RNN和GAN。GAN在计算机视觉领域中一般都以反卷网的形式存在,用以生成稠密的输出。Geohot的文章在这个任务上有很强的原创性,但是并没有给出严谨的定量实验,就目前的情况来看,其理论价值大于实用价值。


最后,关于别人家的工作,除了steering angle prediction(对应下图的behavior reflex)以外,还有两种可能的方式用以学习自动驾驶,一种是把自动驾驶转化为其他的子任务,例如行人和汽车检测、车道线检测、场景语义分割等,在下图中被称为mediated perception。另一种由princeton vision组提出,在下图中被称为direct perception,可以理解为把自动驾驶拆分为一些语义层级较高的子任务(下下图所示)。此项工作在虚拟的赛车游戏中进行训练,在真实数据集kitti上汇报了有关前车距离的定量实验。
代码核心在哪
最后就是折腾着半夜看了看代码,主要都是李师傅带看。代码中使用了基于tensorflow后台的Keras进行CNN网络的构造。steering回归模型是一个单帧处理的网络,比较简单:

使用一个三层卷积网络加两层全链接,输入一幅图像,最后全链接输出要回归的steering角度。如前文所讲到的,这种简单的单帧回归难以对同一场景不同的steering情况进行学习。
文章中的generator模型则相对复杂,其中`models/autoencoder.py`定义了GAN网络下的生成网络和判别网络等模块。

Encoder网络使用了VAE模型,类似于一个卷积回归网络对图像进行基层卷积操作之后,使用全链接构造回归输出,输出结果为VAE编码的mean结果和扰动sigma方差。
生成网络部分比较简单,用全链接将输入的code转换为2Dmap,然后使用Deconv反卷积逐层上采样放大,最终得到生成图像。
Discriminator网络也比较简单,卷积层操作后使用全链接回归输出,输出结果为判别结果,中间的隐层结果也一并输出。
损失函数都比较直观,可以和原文中的内容进行对应,提一下`kl_loss`的计算:
对于一个N(mean, sigma^2)的分布和N(0, 1)计算KL散度即可得到该式。该式的计算网上有很多资料,比如可参考:https://home.zhaw.ch/~dueo/bbs/files/vae.pdf
另外值得一提的是文中`Dis(Gen(Enc(x))`的计算,`Gen(Enc(x))`对应了代码中的

其中`Z2`是一个N(0, 1)分布的采样。因为要强制encoder的输出是N(0, 1),且分布中的所有编码都可产生逼真的图像,因此每次训练中生成一个分布中的样本,也即`E_mean + Z2 * E_logsigma`,约束其解码判别结果`D_dec_fake`与`F_dec_fake`逼真。在上面提到的VAE参考资料中,也可以找到这一采样优化方法的相关介绍。
结语

人家车也在路上跑了,数据也采集了,输入输出也同步了,代码也开源了,论文也公开了,GitHub回答问题还那么及时,我们也都给放到百度云了,没什么槽点了吧……
对于深度学习工作者而言,大量的开源项目避免了很多重造轮子的工作,降低了算法实现门槛。本文盘点了在Github上获得Stars最多的深度学习项目,供从业者参考。并感谢这些开源爱好者的贡献。




链接: https://github.com/aymericdamien/TopDeepLearning
原文链接: http://geek.csdn.net/news/detail/94963

相关文章推荐
- 麻省理工学院-2017年-深度学习与自动驾驶视频课程分享
- 笔记:北航 余贵珍 深度学习在自动驾驶环境感知中的应用
- 【自动驾驶】深度学习用于自动驾驶技术 DeepDriving(ICCV 2015)
- 知名黑客 George Hotz 开源了自动驾驶软件
- 博世投资张翠波:自动驾驶需要突破芯片、传感器、深度学习算法等关键技术
- 重磅译制 | 更新:MIT 6.S094自动驾驶课程第1讲(3)深度学习模型应用
- 深度强化学习及其在自动驾驶中的应用: DRL&ADS系列之(1): 强化学习概述
- 端到端深度学习与自动驾驶(含参考文献)
- 重磅译制 | 更新:MIT 6.S094自动驾驶课程第1讲(2)深度学习模型应用
- 笔记:深度学习驱动的自动驾驶新主流框架盘点
- Udacity自动驾驶课程笔记(二)--计算机视觉和深度学习
- 麻省理工学院-2017年-深度学习与自动驾驶视频课程分享
- 机器学习&深度学习&自动驾驶的一些学习资源(留用随更)
- MIT 深度学习与自动驾驶公开课 Deep Learning for Self-Driving Cars 讲义梗概
- 自动驾驶汽车之深度学习 2018 MIT 6.S094 Deep Learning for Self-Driving Cars
- 端到端深度学习在自动驾驶汽车上的应用
- 记录:简介 深度学习在自动驾驶中的应用
- 端到端深度学习在自动驾驶汽车上的应用
- 【自动驾驶】如何利用深度学习搭建一个最简单的无人驾驶系统
- 深度学习、机器学习图像/人脸/字幕/自动驾驶数据集(Dataset)汇总