python 数据聚合与分组
2016-10-04 17:14
351 查看
前面讲完了字符处理,但对数据进行整体性的聚合运算以及分组操作也是数据分析的重要内容。
通过数据的聚合与分组,我们能更容易的发现隐藏在数据中的规律。
首先,我们了解下groupby这个函数
结果为:
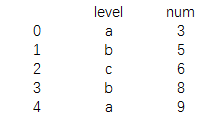
结果为:

这里是以level为关键字对num进行分组,然后求平均值。当然groupby中也可以放入多个分组,用逗号隔开
结果为:

返回每个分组的频率
另外,我们也可以根据数据的所属类型对进行分组
结果为:

这里combine的是Serise数据结构,需要转换线转换为列表,再转成字典的形式才能打印。
结果为:
结果为:
这里map是我们手工创造的字典,然后我们根据字典的对应表对data数据的行进行分组求和。
当然,我们也可以通过自定义函数来扩展方法。
跟上面直接在数据后面加聚合函数方法略有不同,聚合函数这里也可以传入agg或aggregate中
结果为:

也可以多个聚合函数一起使用:
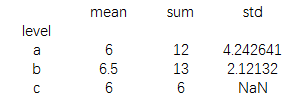
还能用字典的形式进行聚合运算
结果为:

接下来我们了解下transform
结果为

正常求均值之后,会独立形成一个dataframe
结果为:
而在使用transform时,在直接在原来的数据格式下形成新的均值表
这个过程中,经历了数据的拆分,求均值,然后再合并
接下来我们看下更强大的apply
之所以说apply的强大在于,可以我们通过自定义函数,实现我们任何想要的形式对数据进行聚合运算,
但这也是apply相对而言较难的地方,关键点在于如何构造自定义函数。
结果为:

结果为:

最后,在数据分析中,我们经常要用到的一个excel功能是数据透视表,这对我们观察数据规律十分有帮助,
在python中也可以通过pivot_table实现数据透视功能
结果为:

结果为:
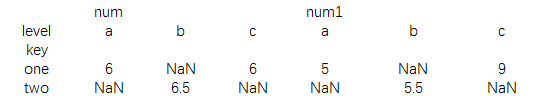
当然只有你调整参数内容就可以像excel中随心所欲的变化行列位置,这里的计数结果默认为均值,用其他聚合函数可以通过aggfunc参数进行设置。
另外还有一个用于计算分组频率的cosstab,使用方法比pivot_table要简单些,形式也类似于execl的数据透视表功能。
结果为
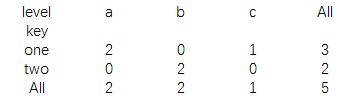
通过数据的聚合与分组,我们能更容易的发现隐藏在数据中的规律。
数据分组
数据的分组核心思想是:拆分-组织-合并首先,我们了解下groupby这个函数
import numpy as np
import pandas as pd
data=pd.DataFrame({'level':['a','b','c','b','a'],
'num':[3,5,6,8,9]})
print(data)结果为:
combine=data['num'].groupby(data['level']) print(combine.mean())
结果为:
这里是以level为关键字对num进行分组,然后求平均值。当然groupby中也可以放入多个分组,用逗号隔开
print(combine.size())
结果为:
返回每个分组的频率
另外,我们也可以根据数据的所属类型对进行分组
combine=data.groupby(data.dtypes,axis=1) print(dict(list(combine)))
结果为:
这里combine的是Serise数据结构,需要转换线转换为列表,再转成字典的形式才能打印。
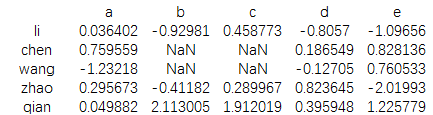
data=pd.DataFrame(np.random.randn(5,5), index=['li','chen','wang','zhao','qian'], columns=['a','b','c','d','e']) print(data)
结果为:
data.ix[1:3,['b','c']]=np.nan
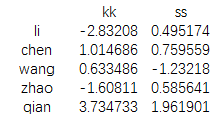
map={'a':'ss','b':'kk','c':'ss','d':'kk','e':'kk'}
print(data.groupby(map,axis=1).sum())结果为:
这里map是我们手工创造的字典,然后我们根据字典的对应表对data数据的行进行分组求和。
数据聚合
在各计算机语言中,聚合函数几乎都差不多,下面我们来看下python中的聚合函数当然,我们也可以通过自定义函数来扩展方法。
跟上面直接在数据后面加聚合函数方法略有不同,聚合函数这里也可以传入agg或aggregate中
data=pd.DataFrame({'level':['a','b','c','b','a'],
'num':[3,5,6,8,9]})
newdata=data.groupby('level')
print(newdata.agg('mean'))结果为:
print(newdata.agg(['mean','sum','std']))
也可以多个聚合函数一起使用:
还能用字典的形式进行聚合运算
data=pd.DataFrame({'level':['a','b','c','b','a'],
'num':[3,5,6,8,9],
'num1':[2,5,9,6,8]})
newdata=data.groupby('level')
print(newdata.agg({'num':'mean','num1':'sum'}))结果为:
接下来我们了解下transform
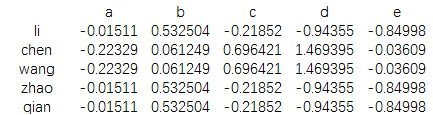
data=pd.DataFrame(np.random.randn(5,5), index=['li','chen','wang','zhao','qian'], columns=['a','b','c','d','e']) key=['ss','kk','kk','ss','ss'] print(data.groupby(key).mean())
结果为
正常求均值之后,会独立形成一个dataframe
print(data.groupby(key).transform(np.mean))
结果为:
而在使用transform时,在直接在原来的数据格式下形成新的均值表
这个过程中,经历了数据的拆分,求均值,然后再合并
接下来我们看下更强大的apply
之所以说apply的强大在于,可以我们通过自定义函数,实现我们任何想要的形式对数据进行聚合运算,
但这也是apply相对而言较难的地方,关键点在于如何构造自定义函数。
data=pd.DataFrame({'level':['a','b','c','b','a'],
'num':[3,5,6,8,9],
'num1':[2,5,9,6,8]})
def fun(data):
return data.groupby('level').agg(['mean','sum'])
print(data)结果为:
print(data.groupby('level').apply(fun))结果为:
最后,在数据分析中,我们经常要用到的一个excel功能是数据透视表,这对我们观察数据规律十分有帮助,
在python中也可以通过pivot_table实现数据透视功能
data=pd.DataFrame({'level':['a','b','c','b','a'],
'key':['one','two','one','two','one'],
'num':[3,5,6,8,9],
'num1':[2,5,9,6,8]})
print(data)结果为:
print(data.pivot_table(index='key',columns='level'))
结果为:
当然只有你调整参数内容就可以像excel中随心所欲的变化行列位置,这里的计数结果默认为均值,用其他聚合函数可以通过aggfunc参数进行设置。
另外还有一个用于计算分组频率的cosstab,使用方法比pivot_table要简单些,形式也类似于execl的数据透视表功能。
print(pd.crosstab(data.key,data.level,margins=True))
结果为

相关文章推荐
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
- python数据分析之:数据聚合与分组运算
- 利用Python进行数据分析--数据聚合与分组运算
- 利用python进行数据分析-数据聚合与分组运算1
- 利用Python进行数据分析--数据聚合与分组运算1
- 利用Python进行数据分析--数据聚合与分组运算
- 利用python进入数据分析之数据聚合与数据分组运算
- Python之数据聚合与分组运算
- python/pandas数据挖掘(十四)-groupby,聚合,分组级运算
- Python数据分析基础(七)——数据聚合与分组
- Python之数据聚合与分组运算
- 利用python进行数据分析-数据聚合与分组运算2
- python中数据聚合与分组运算
- python/pandas数据分析(十五)-聚合与分组运算实例
- 利用python进行数据分析之数据聚合和分组运算
- 利用python进行数据分析-pandas.concat/subplots/gropuby/pivot_table,多文件整合、聚合、分组,子图
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
- python 数据分组
- pandas—数据聚合与分组运算
- 《利用python进行数据分析》读书笔记--第九章 数据聚合与分组运算(二)