《利用python进行数据分析》读书笔记--第九章 数据聚合与分组运算(二)
2015-12-15 21:44
639 查看
第三节中的四个示例。(ps:新开一篇是为了展现对例子的重视。)
3.1用特定于分组的值填充缺失值
对于缺失值的清理工作,可以用dropna进行删除,有时候需要进行填充(或者平滑化)。这时候用的是fillna。
0 -0.311418
1 -0.054305
2 -0.311418
3 1.157882
4 -0.311418
5 -2.037833
Ohio -0.432424
New York -0.572222
Vermont NaN
Florida -1.938769
Oregon 0.417424
Nevada NaN
California 1.170923
Idaho NaN
East -0.981139
West 0.794173
Ohio -0.432424
New York -0.572222
Vermont -0.981139
Florida -1.938769
Oregon 0.417424
Nevada 0.794173
California 1.170923
Idaho 0.794173
Ohio -0.432424
New York -0.572222
Vermont 0.500000
Florida -1.938769
Oregon 0.417424
Nevada 0.400000
California 1.170923
Idaho 0.400000
East East
West West
[Finished in 1.5s]
3.2随机采样和排列
假如想从一个大数据集中抽样完成蒙特卡洛模拟或其他工作。“抽取”的方式有很多,但是效率是不一样的。一个办法是,选取np.random.permutation(N)的前K个元素。下面是个更有趣的例子:
AH 1
2H 2
3H 3
4H 4
5H 5
6H 6
7H 7
8H 8
9H 9
10H 10
JH 10
KH 10
QH 10
7H 7
10S 10
4H 4
JS 10
6D 6
C AC 1
10C 10
D 7D 7
10D 10
H 6H 6
10H 10
S 2S 2
4S 4
6C 6
QC 10
QD 10
10D 10
6H 6
5H 5
7S 7
2S 2
[Finished in 1.3s]
3.3分组加权平均数和相关系数
根据groupby的“拆分-应用-合并”范式。DataFrame的列与列之间或两个Series之间的运算(比如分组加权平均)成为一种标准化作业(有道理)。看下面一个例子:
category
a 0.697948
b 1.595552
AAPL MSFT XOM SPX
2011-10-11 400.29 27.00 76.27 1195.54
2011-10-12 402.19 26.96 77.16 1207.25
2011-10-13 408.43 27.18 76.37 1203.66
2011-10-14 422.00 27.27 78.11 1224.58
AAPL MSFT XOM SPX
2003 0.541124 0.745174 0.661265 1
2004 0.374283 0.588531 0.557742 1
2005 0.467540 0.562374 0.631010 1
2006 0.428267 0.406126 0.518514 1
2007 0.508118 0.658770 0.786264 1
2008 0.681434 0.804626 0.828303 1
2009 0.707103 0.654902 0.797921 1
2010 0.710105 0.730118 0.839057 1
2011 0.691931 0.800996 0.859975 1
2003 0.480868
2004 0.259024
2005 0.300093
2006 0.161735
2007 0.417738
2008 0.611901
2009 0.432738
2010 0.571946
2011 0.581987
[Finished in 1.7s]
3.4面向分组的线性回归
可以利用groupby进行更复杂的分析,只要返回的是pandas对象或者标量值即可。例如,定义下面的函数对每块进行最小二乘回归。
4、透视表和交叉表
透视表很有用,能够比较轻松的完成groupby和更复杂的工作,DataFrame有pivot_table方法,顶级函数pands.pivot_table。除此之外,margins = True添加分项小计。
size tip tip_pct total_bill
sex smoker
Female False 2.592593 2.773519 0.156921 18.105185
True 2.242424 2.931515 0.182150 17.977879
Male False 2.711340 3.113402 0.160669 19.791237
True 2.500000 3.051167 0.152771 22.284500
tip_pct size
smoker False True False True
sex day
Female Fri 0.165296 0.209129 2.500000 2.000000
Sat 0.147993 0.163817 2.307692 2.200000
Sun 0.165710 0.237075 3.071429 2.500000
Thur 0.155971 0.163073 2.480000 2.428571
Male Fri 0.138005 0.144730 2.000000 2.125000
Sat 0.162132 0.139067 2.656250 2.629630
Sun 0.158291 0.173964 2.883721 2.600000
Thur 0.165706 0.164417 2.500000 2.300000
size tip_pct
smoker False True All False True All
sex day
Female Fri 2.500000 2.000000 2.111111 0.165296 0.209129 0.199388
Sat 2.307692 2.200000 2.250000 0.147993 0.163817 0.156470
Sun 3.071429 2.500000 2.944444 0.165710 0.237075 0.181569
Thur 2.480000 2.428571 2.468750 0.155971 0.163073 0.157525
Male Fri 2.000000 2.125000 2.100000 0.138005 0.144730 0.143385
Sat 2.656250 2.629630 2.644068 0.162132 0.139067 0.151577
Sun 2.883721 2.600000 2.810345 0.158291 0.173964 0.162344
Thur 2.500000 2.300000 2.433333 0.165706 0.164417 0.165276
All 2.668874 2.408602 2.569672 0.159328 0.163196 0.160803
day Fri Sat Sun Thur All
sex smoker
Female False 2 13 14 25 54
True 7 15 4 7 33
Male False 2 32 43 20 97
True 8 27 15 10 60
All 19 87 76 62 244
day Fri Sat Sun Thur
time sex smoker
Dinner Female False 2 30 43 2
True 8 33 10 0
Male False 4 85 124 0
True 12 71 39 0
Lunch Female False 3 0 0 60
True 6 0 0 17
Male False 0 0 0 50
True 5 0 0 23
[Finished in 0.8s]
pivot_table的参数,已经全部用到过:

交叉表:crosstab
crosstab是一种计算分组频率(显然应该是频数)的特殊透视表,下面的例子很典型。也就是说这是生成列联表的函数。
smoker False True All
time day
Dinner Fri 3 9 12
Sat 45 42 87
Sun 57 19 76
Thur 1 0 1
Lunch Fri 1 6 7
Thur 44 17 61
All 151 93 244
[Finished in 0.7s]
5、2012联邦选举委员会数据库
这是一个例子,美国选举委员会有关政治精选竞选方面的数据。
根据职业和雇主统计赞助信息
cmte_id C00431445
cand_id P80003338
cand_nm Obama, Barack
contbr_nm ELLMAN, IRA
contbr_city TEMPE
contbr_st AZ
contbr_zip 852816719
contbr_employer ARIZONA STATE UNIVERSITY
contbr_occupation PROFESSOR
contb_receipt_amt 50
contb_receipt_dt 01-DEC-11
receipt_desc NaN
memo_cd NaN
memo_text NaN
form_tp SA17A
file_num 772372
Name: 123456
[Bachmann, Michelle Romney, Mitt Obama, Barack
Roemer, Charles E. 'Buddy' III Pawlenty, Timothy Johnson, Gary Earl
Paul, Ron Santorum, Rick Cain, Herman Gingrich, Newt McCotter, Thaddeus G
Huntsman, Jon Perry, Rick]
Democrat 593746
Republican 407985
True 991475
False 10256
RETIRED 233990
INFORMATION REQUESTED 35107
ATTORNEY 34286
HOMEMAKER 29931
PHYSICIAN 23432
INFORMATION REQUESTED PER BEST EFFORTS 21138
ENGINEER 14334
TEACHER 13990
CONSULTANT 13273
PROFESSOR 12555
party Democrat Republican
contbr_occupation
MIXED-MEDIA ARTIST / STORYTELLER 100 NaN
AREA VICE PRESIDENT 250 NaN
RESEARCH ASSOCIATE 100 NaN
TEACHER 500 NaN
THERAPIST 3900 NaN
party Democrat Republican
contbr_occupation
ATTORNEY 11141982.97 7477194.430000
C.E.O. 1690.00 2592983.110000
CEO 2074284.79 1640758.410000
CONSULTANT 2459912.71 2544725.450000
ENGINEER 951525.55 1818373.700000
EXECUTIVE 1355161.05 4138850.090000
HOMEMAKER 4248875.80 13634275.780000
INVESTOR 884133.00 2431768.920000
LAWYER 3160478.87 391224.320000
MANAGER 762883.22 1444532.370000
NOT PROVIDED 4866973.96 20565473.010000
OWNER 1001567.36 2408286.920000
PHYSICIAN 3735124.94 3594320.240000
PRESIDENT 1878509.95 4720923.760000
PROFESSOR 2165071.08 296702.730000
REAL ESTATE 528902.09 1625902.250000
RETIRED 25305116.38 23561244.489999
SELF-EMPLOYED 672393.40 1640252.540000
cand_nm contbr_occupation
Obama, Barack RETIRED 25305116.38
ATTORNEY 11141982.97
INFORMATION REQUESTED 4866973.96
HOMEMAKER 4248875.80
PHYSICIAN 3735124.94
LAWYER 3160478.87
CONSULTANT 2459912.71
Romney, Mitt RETIRED 11508473.59
INFORMATION REQUESTED PER BEST EFFORTS 11396894.84
HOMEMAKER 8147446.22
ATTORNEY 5364718.82
PRESIDENT 2491244.89
EXECUTIVE 2300947.03
C.E.O. 1968386.11
Name: contb_receipt_amt
cand_nm contbr_occupation
Obama, Barack MIXED-MEDIA ARTIST / STORYTELLER 100
AREA VICE PRESIDENT 250
RESEARCH ASSOCIATE 100
TEACHER 500
THERAPIST 3900
- 5000
.NET PROGRAMMER 481
07/13/1972 98
12K ADVOCATE 150
13D 721
1SG RETIRED 210
1ST ASSISTANT DIRECTOR 2ND UNIT 35
1ST GRADE TEACHER 435
1ST VP WEALTH MANAGEMENT 559
22ND CENTURY REALTY 500
...
Romney, Mitt WRITER/ MUSIC PRODUCER 100
WRITER/AUTHOR 2500
WRITER/EDITOR 350
WRITER/INVESTOR 25
WRITER/MEDIA PRODUCER 300
WRITER/PRODUCER 225
WRITER/TRAINER 35
WUNDERMAN 1000
YACHT BUILDER 2500
YACHT CAPTAIN 500
YACHT CONSTRUCTION 2500
YOGA INSTRUCTOR 500
YOGA TEACHER 2500
YOUTH CARE WORKER 25
YOUTH OUTREACH DIRECTOR 1000
Name: contb_receipt_amt, Length: 35991
cand_nm contbr_employer
Obama, Barack RETIRED 22694358.85
SELF-EMPLOYED 17080985.96
NOT EMPLOYED 8586308.70
INFORMATION REQUESTED 5053480.37
HOMEMAKER 2605408.54
SELF 1076531.20
SELF EMPLOYED 469290.00
STUDENT 318831.45
VOLUNTEER 257104.00
MICROSOFT 215585.36
Romney, Mitt INFORMATION REQUESTED PER BEST EFFORTS 12059527.24
RETIRED 11506225.71
HOMEMAKER 8147196.22
SELF-EMPLOYED 7409860.98
STUDENT 496490.94
CREDIT SUISSE 281150.00
MORGAN STANLEY 267266.00
GOLDMAN SACH & CO. 238250.00
BARCLAYS CAPITAL 162750.00
H.I.G. CAPITAL 139500.00
Name: contb_receipt_amt
[Finished in 16.6s]
下面是上面代码中的图:

对出资额分组
还可以对该数据做另一种非常实用的分析:利用cut将数据分散到各个面元中。
cand_nm Obama, Barack Romney, Mitt
contb_receipt_amt
(0, 1] 493 77
(1, 10] 40070 3681
(10, 100] 372280 31853
(100, 1000] 153991 43357
(1000, 10000] 22284 26186
(10000, 100000] 2 1
(100000, 1000000] 3 NaN
(1000000, 10000000] 4 NaN
cand_nm Obama, Barack Romney, Mitt
contb_receipt_amt
(0, 1] 318.24 77.00
(1, 10] 337267.62 29819.66
(10, 100] 20288981.41 1987783.76
(100, 1000] 54798531.46 22363381.69
(1000, 10000] 51753705.67 63942145.42
(10000, 100000] 59100.00 12700.00
(100000, 1000000] 1490683.08 NaN
(1000000, 10000000] 7148839.76 NaN
cand_nm Obama, Barack Romney, Mitt
contb_receipt_amt
(0, 1] 0.805182 0.194818
(1, 10] 0.918767 0.081233
(10, 100] 0.910769 0.089231
(100, 1000] 0.710176 0.289824
(1000, 10000] 0.447326 0.552674
(10000, 100000] 0.823120 0.176880
(100000, 1000000] 1.000000 NaN
(1000000, 10000000] 1.000000 NaN
[Finished in 221.9s]
下面是最后的图形:
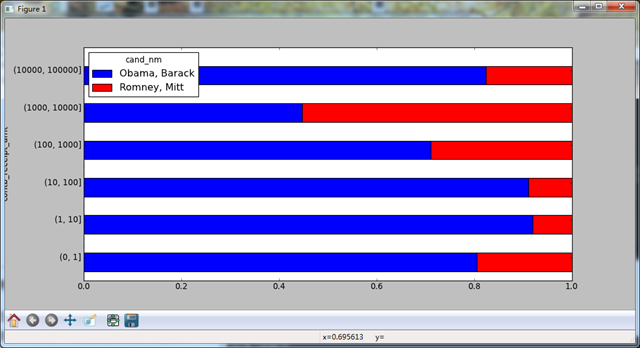
根据州统计赞助信息
这部分由于地图模块装不上就先放一下。
cand_nm Obama, Barack Romney, Mitt
contbr_st
AK 0.765778 0.234222
AL 0.507390 0.492610
AR 0.772902 0.227098
AZ 0.443745 0.556255
CA 0.679498 0.320502
CO 0.585970 0.414030
CT 0.371476 0.628524
DC 0.810113 0.189887
DE 0.802776 0.197224
FL 0.467417 0.532583
[Finished in 18.1s]
3.1用特定于分组的值填充缺失值
对于缺失值的清理工作,可以用dropna进行删除,有时候需要进行填充(或者平滑化)。这时候用的是fillna。
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
s = Series(np.random.randn(6))
s[::2] = np.nan
print s,'\n'
print s.fillna(s.mean()),'\n' #不是就地的,是产生一个副本
#假如需要对不同的分组填充不同的值。只需要groupby然后应用fillna即可。
states = ['Ohio','New York','Vermont','Florida','Oregon','Nevada','California','Idaho']
group_key = ['East'] * 4 + ['West'] * 4
data = Series(np.random.randn(8),index = states)
data[['Vermont','Nevada','Idaho']] = np.nan
print data,'\n'
print data.groupby(group_key).mean(),'\n'
#下面用均值填充NA
fill_mean = lambda g:g.fillna(g.mean())
print data.groupby(group_key).apply(fill_mean),'\n'
#当然,可以自己定义填充值:我刚开始就是这么想的,用字典传入值即可
fill_values = {'East':0.5,'West':0.4}
#注意下面的用法:注意g.name 是分组的名称
fill_func = lambda g:g.fillna(fill_values[g.name])
print data.groupby(group_key).apply(fill_func),'\n'
#看一下名字,第一列是分组名,第二列是函数调用后得到的结果,而这个结果也是分组名
p = lambda x: x.name
print data.groupby(group_key).apply(p)>>>
0 NaN 1 -0.054305 2 NaN 3 1.157882 4 NaN 5 -2.037833
0 -0.311418
1 -0.054305
2 -0.311418
3 1.157882
4 -0.311418
5 -2.037833
Ohio -0.432424
New York -0.572222
Vermont NaN
Florida -1.938769
Oregon 0.417424
Nevada NaN
California 1.170923
Idaho NaN
East -0.981139
West 0.794173
Ohio -0.432424
New York -0.572222
Vermont -0.981139
Florida -1.938769
Oregon 0.417424
Nevada 0.794173
California 1.170923
Idaho 0.794173
Ohio -0.432424
New York -0.572222
Vermont 0.500000
Florida -1.938769
Oregon 0.417424
Nevada 0.400000
California 1.170923
Idaho 0.400000
East East
West West
[Finished in 1.5s]
3.2随机采样和排列
假如想从一个大数据集中抽样完成蒙特卡洛模拟或其他工作。“抽取”的方式有很多,但是效率是不一样的。一个办法是,选取np.random.permutation(N)的前K个元素。下面是个更有趣的例子:
#-*- encoding:utf-8 -*- import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt #红桃(Hearts)、黑桃(Spades)、梅花(Clubs)、方片(Diamonds) suits = ['H','S','C','D'] card_val = (range(1,11) + [10] * 3) * 4 #print card_val base_names = ['A'] + range(2,11) + ['J','K','Q'] cards = [] #注意下面的生成方式,很简洁 #extend将一个列表添加到已有列表中,与append不同 for suit in ['H','S','C','D']: cards.extend(str(num) + suit for num in base_names) print cards,'\n' deck = Series(card_val,index = cards) print deck[:13],'\n' #从排中抽取5张,注意抽取方式,是一种随机选取5个的方式,即先选出一个排列,再从中拿出5个 def draw(deck,n = 5): return deck.take(np.random.permutation(len(deck))[:n]) print draw(deck),'\n' #假如想从每种花色中随机抽取两张。先分组,再对每个组应用draw函数进行抽取 get_suit = lambda card:card[-1] print deck.groupby(get_suit).apply(draw,2) #另一种方法 print deck.groupby(get_suit,group_keys = False).apply(draw,2)
>>>
['AH', '2H', '3H', '4H', '5H', '6H', '7H', '8H', '9H', '10H', 'JH', 'KH', 'QH', 'AS', '2S', '3S', '4S', '5S', '6S', '7S', '8S', '9S', '10S', 'JS', 'KS', 'QS', 'AC', '2C', '3C', '4C', '5C', '6C', '7C', '8C', '9C', '10C', 'JC', 'KC', 'QC', 'AD', '2D', '3D', '4D', '5D', '6D', '7D', '8D', '9D', '10D', 'JD', 'KD', 'QD']
AH 1
2H 2
3H 3
4H 4
5H 5
6H 6
7H 7
8H 8
9H 9
10H 10
JH 10
KH 10
QH 10
7H 7
10S 10
4H 4
JS 10
6D 6
C AC 1
10C 10
D 7D 7
10D 10
H 6H 6
10H 10
S 2S 2
4S 4
6C 6
QC 10
QD 10
10D 10
6H 6
5H 5
7S 7
2S 2
[Finished in 1.3s]
3.3分组加权平均数和相关系数
根据groupby的“拆分-应用-合并”范式。DataFrame的列与列之间或两个Series之间的运算(比如分组加权平均)成为一种标准化作业(有道理)。看下面一个例子:
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
df = DataFrame({'category':list('aaaabbbb'),'data':np.random.randn(8),'weights':np.random.randn(8)})
print df,'\n'
#下面以category分组并计算加权平均
grouped = df.groupby('category')
get_wavg = lambda g:np.average(g['data'],weights = g['weights'])
print grouped.apply(get_wavg),'\n'
#看下面的例子
close_px = pd.read_csv('E:\\stock_px.csv',parse_dates = True,index_col = 0)
print close_px[-4:],'\n'
#下面做一个比较有趣的任务:计算一个由日收益率(通过百分比计算)与SPX之间的年度相关系数
#组成的DataFrame,下面是一个实现办法,下面的pct_change是计算每列下一个数值相对于上一个值的百分比变化,所以,第一个肯定为NaN
rets = close_px.pct_change().dropna()
#print rets[-4:]
spx_corr = lambda x:x.corrwith(x['SPX'])
#注意下面隐式的函数,作者好高明
by_year = rets.groupby(lambda x:x.year)
#对每一小块的所有列和SPX列计算相关系数
print by_year.apply(spx_corr),'\n'
#当然,还可以计算列与列之间的相关系数
print by_year.apply(lambda g:g['AAPL'].corr(g['MSFT']))>>>
category data weights 0 a 0.287761 -1.015669 1 a -0.751835 -1.439559 2 a -0.879771 1.111463 3 a 2.252593 -0.482481 4 b 0.431053 -1.250926 5 b 0.240771 -1.259915 6 b 0.090695 -1.024591 7 b -0.602894 2.140364
category
a 0.697948
b 1.595552
AAPL MSFT XOM SPX
2011-10-11 400.29 27.00 76.27 1195.54
2011-10-12 402.19 26.96 77.16 1207.25
2011-10-13 408.43 27.18 76.37 1203.66
2011-10-14 422.00 27.27 78.11 1224.58
AAPL MSFT XOM SPX
2003 0.541124 0.745174 0.661265 1
2004 0.374283 0.588531 0.557742 1
2005 0.467540 0.562374 0.631010 1
2006 0.428267 0.406126 0.518514 1
2007 0.508118 0.658770 0.786264 1
2008 0.681434 0.804626 0.828303 1
2009 0.707103 0.654902 0.797921 1
2010 0.710105 0.730118 0.839057 1
2011 0.691931 0.800996 0.859975 1
2003 0.480868
2004 0.259024
2005 0.300093
2006 0.161735
2007 0.417738
2008 0.611901
2009 0.432738
2010 0.571946
2011 0.581987
[Finished in 1.7s]
3.4面向分组的线性回归
可以利用groupby进行更复杂的分析,只要返回的是pandas对象或者标量值即可。例如,定义下面的函数对每块进行最小二乘回归。
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
import statsmodels.api as sm
close_px = pd.read_csv('E:\\stock_px.csv',parse_dates = True,index_col = 0)
rets = close_px.pct_change().dropna()
#注意下面隐式的函数,作者好高明
by_year = rets.groupby(lambda x:x.year)
def regress(data,yvar,xvars):
Y = data[yvar]
X = data[xvars]
X['intercept'] = 1
result = sm.OLS(Y,X).fit()
return result.params
print by_year.apply(regress,'AAPL',['SPX'])4、透视表和交叉表
透视表很有用,能够比较轻松的完成groupby和更复杂的工作,DataFrame有pivot_table方法,顶级函数pands.pivot_table。除此之外,margins = True添加分项小计。
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
tips = pd.read_csv('E:\\tips.csv')
tips['tip_pct'] = tips['tip'] / tips['total_bill']
print tips.head(),'\n'
#透视表默认的函数是mean
print tips.pivot_table(rows = ['sex','smoker']),'\n' #这样的工作用groupby也能轻易完成
#print tips.groupby(['sex','smoker']).mean()
#现在用tip_pct和size进行聚合,而且想根据day进行分组,将smoker放在列上,把day放到行上
print tips.pivot_table(['tip_pct','size'],rows = ['sex','day'],cols = 'smoker'),'\n' #这个用groupby就比较费力了
#可以添加选项 margins = True添加分项小计。这将会添加All行和列,这里的all行或者列将不考虑差别,算整体的值
print tips.pivot_table(['tip_pct','size'],rows = ['sex','day'],cols = 'smoker',margins = True),'\n'
#想应用别的函数,只要将函数传入aggfunc即可
print tips.pivot_table('tip_pct',rows = ['sex','smoker'],cols = 'day',aggfunc = len,margins = True),'\n'
#如果出现NA,经常出现,可以设置一个fill_value
print tips.pivot_table('size',rows = ['time','sex','smoker'],cols = 'day',aggfunc = 'sum',fill_value = 0)>>>
total_bill tip sex smoker day time size tip_pct 0 16.99 1.01 Female False Sun Dinner 2 0.059447 1 10.34 1.66 Male False Sun Dinner 3 0.160542 2 21.01 3.50 Male False Sun Dinner 3 0.166587 3 23.68 3.31 Male False Sun Dinner 2 0.139780 4 24.59 3.61 Female False Sun Dinner 4 0.146808
size tip tip_pct total_bill
sex smoker
Female False 2.592593 2.773519 0.156921 18.105185
True 2.242424 2.931515 0.182150 17.977879
Male False 2.711340 3.113402 0.160669 19.791237
True 2.500000 3.051167 0.152771 22.284500
tip_pct size
smoker False True False True
sex day
Female Fri 0.165296 0.209129 2.500000 2.000000
Sat 0.147993 0.163817 2.307692 2.200000
Sun 0.165710 0.237075 3.071429 2.500000
Thur 0.155971 0.163073 2.480000 2.428571
Male Fri 0.138005 0.144730 2.000000 2.125000
Sat 0.162132 0.139067 2.656250 2.629630
Sun 0.158291 0.173964 2.883721 2.600000
Thur 0.165706 0.164417 2.500000 2.300000
size tip_pct
smoker False True All False True All
sex day
Female Fri 2.500000 2.000000 2.111111 0.165296 0.209129 0.199388
Sat 2.307692 2.200000 2.250000 0.147993 0.163817 0.156470
Sun 3.071429 2.500000 2.944444 0.165710 0.237075 0.181569
Thur 2.480000 2.428571 2.468750 0.155971 0.163073 0.157525
Male Fri 2.000000 2.125000 2.100000 0.138005 0.144730 0.143385
Sat 2.656250 2.629630 2.644068 0.162132 0.139067 0.151577
Sun 2.883721 2.600000 2.810345 0.158291 0.173964 0.162344
Thur 2.500000 2.300000 2.433333 0.165706 0.164417 0.165276
All 2.668874 2.408602 2.569672 0.159328 0.163196 0.160803
day Fri Sat Sun Thur All
sex smoker
Female False 2 13 14 25 54
True 7 15 4 7 33
Male False 2 32 43 20 97
True 8 27 15 10 60
All 19 87 76 62 244
day Fri Sat Sun Thur
time sex smoker
Dinner Female False 2 30 43 2
True 8 33 10 0
Male False 4 85 124 0
True 12 71 39 0
Lunch Female False 3 0 0 60
True 6 0 0 17
Male False 0 0 0 50
True 5 0 0 23
[Finished in 0.8s]
pivot_table的参数,已经全部用到过:

交叉表:crosstab
crosstab是一种计算分组频率(显然应该是频数)的特殊透视表,下面的例子很典型。也就是说这是生成列联表的函数。
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
tips = pd.read_csv('E:\\tips.csv')
tips['tip_pct'] = tips['tip'] / tips['total_bill']
data = DataFrame({'Sample':range(1,11,1),'Gender':['F','M','F','M','M','M','F','F','M','F'],'Handedness':['R','L','R','R','L','R','R','L','R','R']})
print pd.crosstab(data.Gender,data.Handedness,margins = True),'\n'
#crosstab的前两个参数可以是数组、Series或数组列表
print pd.crosstab([tips.time,tips.day],tips.smoker,margins = True),'\n'>>>
Handedness L R All Gender F 1 4 5 M 2 3 5 All 3 7 10
smoker False True All
time day
Dinner Fri 3 9 12
Sat 45 42 87
Sun 57 19 76
Thur 1 0 1
Lunch Fri 1 6 7
Thur 44 17 61
All 151 93 244
[Finished in 0.7s]
5、2012联邦选举委员会数据库
这是一个例子,美国选举委员会有关政治精选竞选方面的数据。
根据职业和雇主统计赞助信息
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
#加载数据,150M+,用时8.7s
fec = pd.read_csv('E:\\P00000001-ALL.csv')
print fec,'\n'
print fec.ix[123456],'\n'
#下面介绍几种不同的分析方法
#通过unique,你可以获取全部的候选人名单
unique_cands = fec.cand_nm.unique()
print unique_cands,'\n'
#下面将候选人和党派对应起来,额,写了半天,奥巴马是Democrat(民主党),其他人都是共和党……
parties = {'Bachmann, Michelle':'Republican',
'Cain, Herman':'Republican',
'Gingrich, Newt':'Republican',
'Huntsman, Jon':'Republican',
'Johnson, Gary Earl':'Republican',
'McCotter, Thaddeus G':'Republican',
'Obama, Barack':'Democrat',
'Paul, Ron':'Republican',
'Pawlenty, Timothy':'Republican',
'Perry, Rick':'Republican',
"Roemer, Charles E. 'Buddy' III":'Republican',
'Romney, Mitt':'Republican',
'Santorum, Rick':'Republican'}
#为其添加新列
fec['party'] = fec.cand_nm.map(parties)
print fec['party'].value_counts(),'\n'
#注意,这份数据既包括赞助也包括退款
print (fec.contb_receipt_amt > 0).value_counts(),'\n'
#为了简便,这里将只研究正出资额的部分
fec = fec[fec.contb_receipt_amt > 0]
#专门准备两个子集盛放奥巴马和Mitt Romney
fec_mrbo = fec[fec.cand_nm.isin(['Obama, Barack','Romney, Mitt'])]
#根据职业和雇主统计赞助信息,例如律师倾向于赞助民主党,企业主倾向于自主共和党
#下面看一下职业
print fec.contbr_occupation.value_counts()[:10],'\n'
#下面将这些职业进行一些处理(将一个职业信息映射到另一个)
occ_mapping = {
'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED',
'INFORMATION REQUESTED':'NOT PROVIDED',
'INFORMATION REQUESTED (BEST EFFORTS)':'NOT PROVIDED',
'C.E.O':'CEO'
}
#下面用了一个dict.get,下面的get第一个x是dict的键,映射到返回对应的key,第二个是没有映射到返回的内容,如果没有提供映射的话,返回x
f = lambda x:occ_mapping.get(x,x)
fec.contbr_occupation = fec.contbr_occupation.map(f)
#对雇主的信息也这样处理一下
emp_mapping = {
'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED',
'INFORMATION REQUESTED':'NOT PROVIDED',
'SELF':'SELF-EMPLOYED',
'SELF EMPLOYED':'SELF-EMPLOYED'
}
f = lambda x:emp_mapping.get(x,x)
fec.contbr_employer = fec.contbr_employer.map(f)
#下面可以通过pivot_table根据党派和职业对数据进行聚合,然后过滤掉出资总额不足200万美元的数据
by_occupation = fec.pivot_table('contb_receipt_amt',rows = 'contbr_occupation',cols = 'party',aggfunc = sum)
print by_occupation.head(),'\n' #这个数据一定要看一下
over_2mm = by_occupation[by_occupation.sum(1) > 2000000]
print over_2mm
over_2mm.plot(kind = 'barh')
plt.show()
#你可能还想了解一下对OBAMA和ROMNEY总出资额最高的职业和企业,想法是先分组,然后再选取
def get_top_amounts(group,key,n = 5):
totals = group.groupby(key)['contb_receipt_amt'].sum()
return totals.order(ascending = False)[:n] #作者书上写错了
grouped = fec_mrbo.groupby('cand_nm')
#下面的语句是说,grouped对象可以被进一步groupby
print grouped.apply(get_top_amounts,'contbr_occupation',n = 7),'\n'
print fec_mrbo.groupby(['cand_nm','contbr_occupation'])['contb_receipt_amt'].sum(),'\n' #不知道这里为啥不对……,为什么跟前面的语句结果不一样?……
#print fec_mrbo.pivot_table('contb_receipt_amt',rows = ['cand_nm','contbr_occupation'],aggfunc = 'sum')
print grouped.apply(get_top_amounts,'contbr_employer',n = 10)>>>
<class 'pandas.core.frame.DataFrame'> Int64Index: 1001731 entries, 0 to 1001730 Data columns: cmte_id 1001731 non-null values cand_id 1001731 non-null values cand_nm 1001731 non-null values contbr_nm 1001731 non-null values contbr_city 1001716 non-null values contbr_st 1001727 non-null values contbr_zip 1001620 non-null values contbr_employer 994314 non-null values contbr_occupation 994433 non-null values contb_receipt_amt 1001731 non-null values contb_receipt_dt 1001731 non-null values receipt_desc 14166 non-null values memo_cd 92482 non-null values memo_text 97770 non-null values form_tp 1001731 non-null values file_num 1001731 non-null values dtypes: float64(1), int64(1), object(14)
cmte_id C00431445
cand_id P80003338
cand_nm Obama, Barack
contbr_nm ELLMAN, IRA
contbr_city TEMPE
contbr_st AZ
contbr_zip 852816719
contbr_employer ARIZONA STATE UNIVERSITY
contbr_occupation PROFESSOR
contb_receipt_amt 50
contb_receipt_dt 01-DEC-11
receipt_desc NaN
memo_cd NaN
memo_text NaN
form_tp SA17A
file_num 772372
Name: 123456
[Bachmann, Michelle Romney, Mitt Obama, Barack
Roemer, Charles E. 'Buddy' III Pawlenty, Timothy Johnson, Gary Earl
Paul, Ron Santorum, Rick Cain, Herman Gingrich, Newt McCotter, Thaddeus G
Huntsman, Jon Perry, Rick]
Democrat 593746
Republican 407985
True 991475
False 10256
RETIRED 233990
INFORMATION REQUESTED 35107
ATTORNEY 34286
HOMEMAKER 29931
PHYSICIAN 23432
INFORMATION REQUESTED PER BEST EFFORTS 21138
ENGINEER 14334
TEACHER 13990
CONSULTANT 13273
PROFESSOR 12555
party Democrat Republican
contbr_occupation
MIXED-MEDIA ARTIST / STORYTELLER 100 NaN
AREA VICE PRESIDENT 250 NaN
RESEARCH ASSOCIATE 100 NaN
TEACHER 500 NaN
THERAPIST 3900 NaN
party Democrat Republican
contbr_occupation
ATTORNEY 11141982.97 7477194.430000
C.E.O. 1690.00 2592983.110000
CEO 2074284.79 1640758.410000
CONSULTANT 2459912.71 2544725.450000
ENGINEER 951525.55 1818373.700000
EXECUTIVE 1355161.05 4138850.090000
HOMEMAKER 4248875.80 13634275.780000
INVESTOR 884133.00 2431768.920000
LAWYER 3160478.87 391224.320000
MANAGER 762883.22 1444532.370000
NOT PROVIDED 4866973.96 20565473.010000
OWNER 1001567.36 2408286.920000
PHYSICIAN 3735124.94 3594320.240000
PRESIDENT 1878509.95 4720923.760000
PROFESSOR 2165071.08 296702.730000
REAL ESTATE 528902.09 1625902.250000
RETIRED 25305116.38 23561244.489999
SELF-EMPLOYED 672393.40 1640252.540000
cand_nm contbr_occupation
Obama, Barack RETIRED 25305116.38
ATTORNEY 11141982.97
INFORMATION REQUESTED 4866973.96
HOMEMAKER 4248875.80
PHYSICIAN 3735124.94
LAWYER 3160478.87
CONSULTANT 2459912.71
Romney, Mitt RETIRED 11508473.59
INFORMATION REQUESTED PER BEST EFFORTS 11396894.84
HOMEMAKER 8147446.22
ATTORNEY 5364718.82
PRESIDENT 2491244.89
EXECUTIVE 2300947.03
C.E.O. 1968386.11
Name: contb_receipt_amt
cand_nm contbr_occupation
Obama, Barack MIXED-MEDIA ARTIST / STORYTELLER 100
AREA VICE PRESIDENT 250
RESEARCH ASSOCIATE 100
TEACHER 500
THERAPIST 3900
- 5000
.NET PROGRAMMER 481
07/13/1972 98
12K ADVOCATE 150
13D 721
1SG RETIRED 210
1ST ASSISTANT DIRECTOR 2ND UNIT 35
1ST GRADE TEACHER 435
1ST VP WEALTH MANAGEMENT 559
22ND CENTURY REALTY 500
...
Romney, Mitt WRITER/ MUSIC PRODUCER 100
WRITER/AUTHOR 2500
WRITER/EDITOR 350
WRITER/INVESTOR 25
WRITER/MEDIA PRODUCER 300
WRITER/PRODUCER 225
WRITER/TRAINER 35
WUNDERMAN 1000
YACHT BUILDER 2500
YACHT CAPTAIN 500
YACHT CONSTRUCTION 2500
YOGA INSTRUCTOR 500
YOGA TEACHER 2500
YOUTH CARE WORKER 25
YOUTH OUTREACH DIRECTOR 1000
Name: contb_receipt_amt, Length: 35991
cand_nm contbr_employer
Obama, Barack RETIRED 22694358.85
SELF-EMPLOYED 17080985.96
NOT EMPLOYED 8586308.70
INFORMATION REQUESTED 5053480.37
HOMEMAKER 2605408.54
SELF 1076531.20
SELF EMPLOYED 469290.00
STUDENT 318831.45
VOLUNTEER 257104.00
MICROSOFT 215585.36
Romney, Mitt INFORMATION REQUESTED PER BEST EFFORTS 12059527.24
RETIRED 11506225.71
HOMEMAKER 8147196.22
SELF-EMPLOYED 7409860.98
STUDENT 496490.94
CREDIT SUISSE 281150.00
MORGAN STANLEY 267266.00
GOLDMAN SACH & CO. 238250.00
BARCLAYS CAPITAL 162750.00
H.I.G. CAPITAL 139500.00
Name: contb_receipt_amt
[Finished in 16.6s]
下面是上面代码中的图:
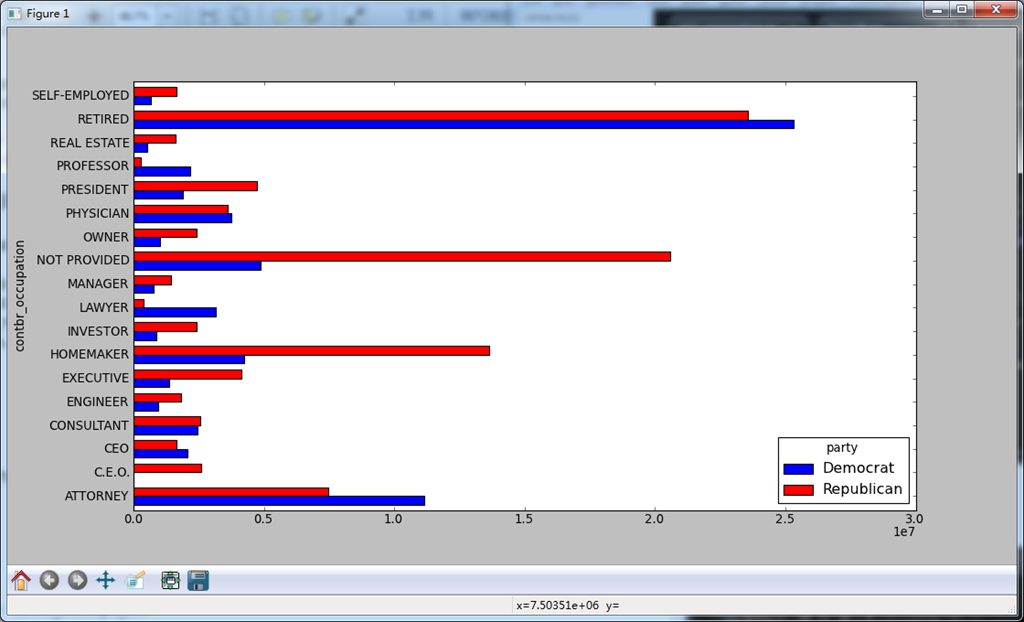
对出资额分组
还可以对该数据做另一种非常实用的分析:利用cut将数据分散到各个面元中。
#部分代码 bins = np.array([0,1,10,100,1000,10000,100000,1000000,10000000]) labels = pd.cut(fec_mrbo.contb_receipt_amt,bins) print labels,'\n' #然后根据候选人姓名以及面元标签对数据进行分组 grouped = fec_mrbo.groupby(['cand_nm',labels]) print grouped.size().unstack(0),'\n' #可以看出两个候选人不同面元捐款的数量 #还可以对出资额求和并在面元内规格化,以便图形化显示两位候选人各种赞助的比例 bucket_sums = grouped.contb_receipt_amt.sum().unstack(0) print bucket_sums,'\n' normed_sums = bucket_sums.div(bucket_sums.sum(axis = 1),axis = 0) print normed_sums,'\n' #排除最大的两个面元并作图: normed_sums[:-2].plot(kind = 'barh',stacked = True) plt.show()
>>>
Categorical: contb_receipt_amt array([(10, 100], (100, 1000], (100, 1000], ..., (1, 10], (10, 100], (100, 1000]], dtype=object) Levels (8): Index([(0, 1], (1, 10], (10, 100], (100, 1000], (1000, 10000], (10000, 100000], (100000, 1000000], (1000000, 10000000]], dtype=object)
cand_nm Obama, Barack Romney, Mitt
contb_receipt_amt
(0, 1] 493 77
(1, 10] 40070 3681
(10, 100] 372280 31853
(100, 1000] 153991 43357
(1000, 10000] 22284 26186
(10000, 100000] 2 1
(100000, 1000000] 3 NaN
(1000000, 10000000] 4 NaN
cand_nm Obama, Barack Romney, Mitt
contb_receipt_amt
(0, 1] 318.24 77.00
(1, 10] 337267.62 29819.66
(10, 100] 20288981.41 1987783.76
(100, 1000] 54798531.46 22363381.69
(1000, 10000] 51753705.67 63942145.42
(10000, 100000] 59100.00 12700.00
(100000, 1000000] 1490683.08 NaN
(1000000, 10000000] 7148839.76 NaN
cand_nm Obama, Barack Romney, Mitt
contb_receipt_amt
(0, 1] 0.805182 0.194818
(1, 10] 0.918767 0.081233
(10, 100] 0.910769 0.089231
(100, 1000] 0.710176 0.289824
(1000, 10000] 0.447326 0.552674
(10000, 100000] 0.823120 0.176880
(100000, 1000000] 1.000000 NaN
(1000000, 10000000] 1.000000 NaN
[Finished in 221.9s]
下面是最后的图形:
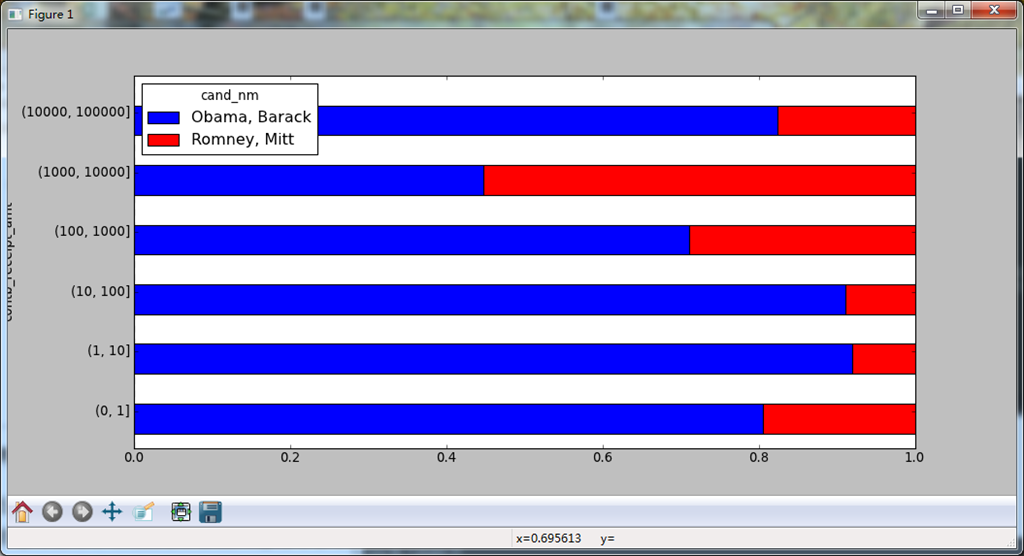
根据州统计赞助信息
这部分由于地图模块装不上就先放一下。
#部分代码 grouped = fec_mrbo.groupby(['cand_nm','contbr_st']) totals = grouped.contb_receipt_amt.sum().unstack(0).fillna(0) totals = totals[totals.sum(1) > 100000] print totals[:10],'\n' percent = totals.div(totals.sum(1),axis = 0) print percent[:10]
>>>
cand_nm Obama, Barack Romney, Mitt contbr_st AK 281840.15 86204.24 AL 543123.48 527303.51 AR 359247.28 105556.00 AZ 1506476.98 1888436.23 CA 23824984.24 11237636.60 CO 2132429.49 1506714.12 CT 2068291.26 3499475.45 DC 4373538.80 1025137.50 DE 336669.14 82712.00 FL 7318178.58 8338458.81
cand_nm Obama, Barack Romney, Mitt
contbr_st
AK 0.765778 0.234222
AL 0.507390 0.492610
AR 0.772902 0.227098
AZ 0.443745 0.556255
CA 0.679498 0.320502
CO 0.585970 0.414030
CT 0.371476 0.628524
DC 0.810113 0.189887
DE 0.802776 0.197224
FL 0.467417 0.532583
[Finished in 18.1s]

相关文章推荐
- Python-MySQL summary
- 关于python的编解码(decode, encode)
- 二分K-均值算法 bisecting K-means in Python
- Python socket 模块的使用
- python安装mysql库
- win10 python nltk安装
- 机器学习实战-边学边读python代码(5)
- python之内存概念
- python 中的一些小命令
- redhat 更新 python 为 2.7.6
- python基础教程共60课-第43课查天气1
- python :逻辑行被分成两个物理行的解决方法
- python基础教程共60课-第42课函数的默认参数
- python: 通过脚本实现重要文件的备份
- python基础教程共60课-第41课用文件保存游戏3
- 在工作过程中,对RabbitMQ的一些体会
- Python基础教程 第2章: 列表和元组 学习笔记
- 关于Python升级版本出现的问题
- Python学习_2015年12月15日
- python R 热度图聚类demo