经典排序算法学习笔记二——快速排序
2016-10-04 12:09
363 查看
快速排序
| 数据结构 | 不定 |
|---|---|
| 最差时间复杂度 | O(n^2) |
| 最优时间复杂度 | O (n*log n) |
| 平均时间复杂度 | O (n*log n) |
| 最差空间复杂度 | 根据实现的方式不同而不同 |
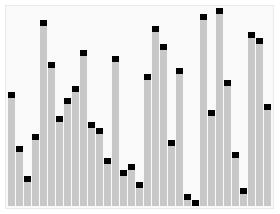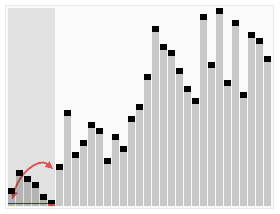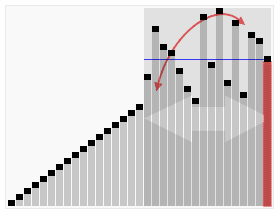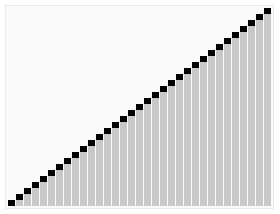
1、算法思想
从数列中挑出一个元素,称为"基准"(pivot),
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
2、伪代码
function quicksort(q)//from 维基百科
var list less, pivotList, greater
if length(q) ≤ 1 {
return q
} else {
select a pivot value pivot from q
for each x in q except the pivot element
if x < pivot then add x to less
if x ≥ pivot then add x to greater
add pivot to pivotList
return concatenate(quicksort(less), pivotList, quicksort(greater))
}QUICK_SORT(A,p,r)//from 算法导论 if(p<r) thenq<——PARTITION(A,p,r) QUICK_SORT(A,p,q-1) QUICK_SORT(A,q+1,r) //核心函数,对数组A[p,r]进行就地重排,将小于A[r]的数移到数组前半部分,将大于A[r]的数移到数组后半部分。 // PARTITION(A,p,r) pivot<——A[r] i<——p-1 forj<——ptor-1 doifA[j]<pivot i<——i+1 exchangeA[i]<——>A[j] exchangeA[i+1]<——>A[r] return i+1
3、C实现
迭代法
typedef struct _Range {
int start, end;
} Range;
Range new_Range(int s, int e) {
Range r;
r.start = s;
r.end = e;
return r;
}
void swap(int *x, int *y) {
int t = *x;
*x = *y;
*y = t;
}
void quick_sort(int arr[], const int len) {
if (len <= 0)
return; //避免len等於負值時宣告堆疊陣列當機
//r[]模擬堆疊,p為數量,r[p++]為push,r[--p]為pop且取得元素
Range r[len];
int p = 0;
r[p++] = new_Range(0, len - 1);
while (p) {
Range range = r[--p];
if (range.start >= range.end)
continue;
int mid = arr[range.end];
int left = range.start, right = range.end - 1;
while (left < right) {
while (arr[left] < mid && left < right)
left++;
while (arr[right] >= mid && left < right)
right--;
swap(&arr[left], &arr[right]);
}
if (arr[left] >= arr[range.end])
swap(&arr[left], &arr[range.end]);
else
left++;
r[p++] = new_Range(range.start, left - 1);
r[p++] = new_Range(left + 1, range.end);
}
}递归法
#include <stdio.h>
#include <stdlib.h>
void swap(int *x, int *y) {
int t = *x;
*x = *y;
*y = t;
}
void quick_sort_recursive(int arr[], int start, int end) {
if (start >= end)
return;//這是為了防止宣告堆疊陣列時當機
int mid = arr[end];
int left = start, right = end - 1;
while (left < right) {
while (arr[left] < mid && left < right)
left++;
while (arr[right] >= mid && left < right)
right--;
swap(&arr[left], &arr[right]);
}
if (arr[left] >= arr[end])
swap(&arr[left], &arr[end]);
else
left++;
quick_sort_recursive(arr, start, left - 1);
quick_sort_recursive(arr, left + 1, end);
}
void quick_sort(int arr[], int len) {
quick_sort_recursive(arr, 0, len - 1);
}
int main() {
int arr[] = { 22, 34, 3, 32, 82, 55, 89, 50, 37, 5, 64, 35, 9, 70 };
int len = (int) sizeof(arr) / sizeof(*arr);
int i;
printf("before quick_sort:\n");
for (i = 0; i < len; i++)
printf("%d ", arr[i]);
quick_sort(arr, len);
printf("\nquick_sorted:\n");
for (i = 0; i < len; i++)
printf("%d ", arr[i]);
system("pause");
return 0;
}4、改进
——摘自维基百科
快速排序是二叉查找树(二叉查找树)的一个空间最优化版本。
对于排序算法的稳定性指标,原地分区版本的快速排序算法是不稳定的。其他变种是可以通过牺牲性能和空间来维护稳定性的。
快速排序的最直接竞争者是堆排序(Heapsort)。
快速排序也与归并排序(Mergesort)竞争,这是另外一种递归排序算法,但有坏情况O(n log n)运行时间的优势。
归并排序是一个稳定排序,且可以轻易地被采用在链表(linked list)和存储在慢速访问媒体上像是磁盘存储或网络连接存储的非常巨大数列。尽管快速排序可以被重新改写使用在炼串列上,但是它通常会因为无法随机存取而导致差的基准选择。
归并排序的主要缺点,是在最佳情况下需要Ω(n)额外的空间。

相关文章推荐
- 经典排序算法学习笔记
- 经典排序算法学习笔记一——冒泡排序
- 经典排序算法学习笔记七——堆排序
- 经典排序算法学习笔记五——直接选择排序
- 深层次两张图解经典6大排序与6大基础数据结构——学完这些,妈妈再也不用担心我的排序算法与数据结构,学习笔记大放送
- 经典排序算法学习笔记六——归并排序
- 经典排序算法学习笔记四——希尔排序
- mini-web学习笔记之经典CRUD显示页面总结
- c#经典入门--学习笔记
- 经典的Boost学习笔记
- 学习笔记1:冒泡排序, 快速排序
- c#经典入门学习笔记-定义集合
- 排序算法学习- 快速排序
- 学习笔记---递归的代码,解决经典的汉诺塔问题
- 2011/5/28操作系统学习笔记之经典同步问题
- Entity Bean(经典学习笔记之一)
- 操作系统学习笔记(10) 互斥和同步的经典问题
- 算法导论学习笔记-第七章-快速排序
- SQL Server 2005 学习笔记系列文章导航 存储过程分页的经典例子
- c#经典入门学习笔记-定义集合