Spark的RDD简单操作
2016-05-14 13:25
423 查看
0、Spark的wc.note
 1、rdd1_aggregate.noteaggregate用法:
1、rdd1_aggregate.noteaggregate用法:
示例一结果:( val arr=sc.parallelize(Array(1,2,3,4,5,6))) 示例二结果:(val arr=sc.parallelize(Array(1,2,3,4,5,6),2))
示例二结果:(val arr=sc.parallelize(Array(1,2,3,4,5,6),2)) 示例三结果:(val arr=sc.parallelize(Array("hadoop","spark","hive","hbase","kafka")))
示例三结果:(val arr=sc.parallelize(Array("hadoop","spark","hive","hbase","kafka"))) 2、rdd2_cache.notecache()简单用法:
2、rdd2_cache.notecache()简单用法:
 3、rdd3_cartesian.note
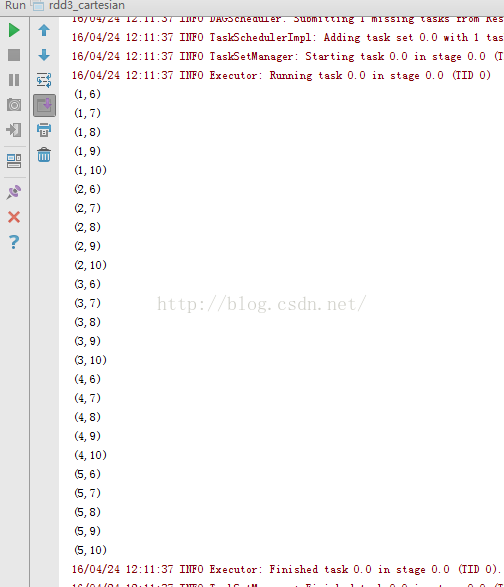
3、rdd3_cartesian.note
 4、rdd4_coalesce.note
4、rdd4_coalesce.note
示例一:
 示例2:
示例2: 5、rdd5_countByValue.note
5、rdd5_countByValue.note
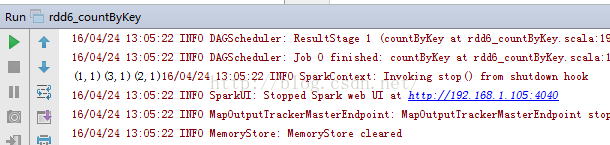
 6、rdd6_countByKey.note
6、rdd6_countByKey.note
 7、rdd7_distinct.notedistinct方法:
7、rdd7_distinct.notedistinct方法:
 8、rdd8_filter.notefilter方法:
8、rdd8_filter.notefilter方法:
 9、rdd9_flatMap.noteflatMap方法:
9、rdd9_flatMap.noteflatMap方法:
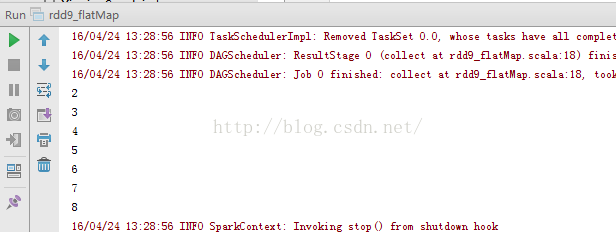 10、rdd10_map .notemap方法:
10、rdd10_map .notemap方法:
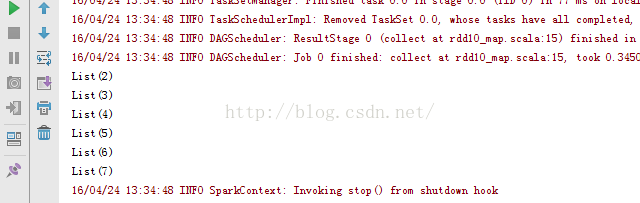 11、rdd11_groupBy .notegroup方法:
11、rdd11_groupBy .notegroup方法:
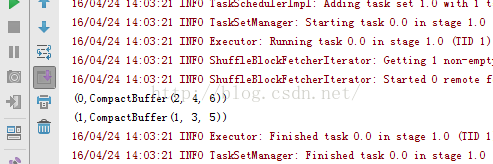 12、rdd12_keyBy .notekeyBy方法:
12、rdd12_keyBy .notekeyBy方法:
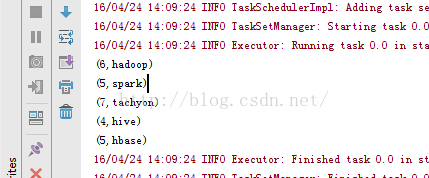 13、rdd13_reduce.notereduce方法:
13、rdd13_reduce.notereduce方法:
示例一: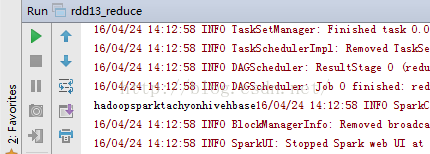 示例二:
示例二: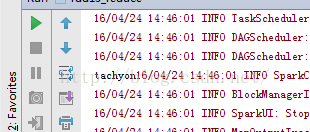 14、rdd14_sortBy.notesortBy方法:
14、rdd14_sortBy.notesortBy方法:
 15、rdd15_zip.notezip方法:
15、rdd15_zip.notezip方法:
package RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** hadoop* spark* tachyon* hadoop* hbase* spark*//*** Created by Administrator on 2016/4/23.*/object rdd0_wc {def main(args: Array[String]) {//创建环境变量val conf=new SparkConf().setMaster("local").setAppName("rdd0_wc")//创建环境变量实例val sc=new SparkContext(conf)//读取文件val data=sc.textFile("E://sparkdata//wc.txt")data.flatMap(_.split("\t")).map((_,1)).reduceByKey(_+_).collect().foreach(println) //wrod计数}} |
1、rdd1_aggregate.noteaggregate用法:package RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/23.*/object rdd1_aggregate {/*** aggregate方法* RDD是工作在Spark上,因此,parallelize方法是将内存数据读入Spark系统中,作为一个整体的数据集。* math.max方法用于比较数据集中数据的大小;* 第二个_+_方法是对传递的第一个比较方法结果进行处理。第一个比较结果是6,与中立空值相加,所以最终结果为6*/def main(args: Array[String]) {val conf=new SparkConf().setMaster("local").setAppName("rdd1_aggregate")val sc=new SparkContext(conf)val arr=sc.parallelize(Array(1,2,3,4,5,6))val result=arr.aggregate(0)(math.max(_, _), _ + _) //aggregate用法println(result)}/*** 参数改变后* 这里parallelize将数据分成两个节点存储* math方法分别查找出两个数据集的最大值,分别是3和6.* 这样在调用aggregate方法的第二个计算方法时,将查找的数据值进行相加,获得最大值9*/// def main(args: Array[String]) {// val conf=new SparkConf().setMaster("local").setAppName("rdd1_aggregate")// val sc=new SparkContext(conf)// val arr=sc.parallelize(Array(1,2,3,4,5,6),2)// val result=arr.aggregate(0)(math.max(_, _), _ + _) //aggregate用法// println(result)// }/*** aggregate方法用于字符串*/// def main(args: Array[String]) {// val conf=new SparkConf().setMaster("local").setAppName("rdd1_aggregate")// val sc=new SparkContext(conf)// val arr=sc.parallelize(Array("hadoop","spark","hive","hbase","kafka"))// val result=arr.aggregate("")((value,word)=>value+"、"+word,_+_) //aggregate用法// println(result)// }} |
示例二结果:(val arr=sc.parallelize(Array(1,2,3,4,5,6),2))示例三结果:(val arr=sc.parallelize(Array("hadoop","spark","hive","hbase","kafka")))2、rdd2_cache.notecache()简单用法:package RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.* cache方法的作用是将数据内容计算并保存在计算节点的内存中,这个方法的使用是针对Spark的Lazy数据处理模式。* 在Lazy模式中,数据在编译和使用时是不进行计算的,而仅仅保存其存储地址,只有Action方法到来时才正式计算。* 这样做的好处是可以极大的减少存储空间,从而提高利用率,而有时必须要求数据进行计算,此时就需要使用cache方法。*/object rdd2_cache {def main(args: Array[String]) {val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd2_cache") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val arr=sc.parallelize(Array("hadoop","spark","hive")) //设定数据集println(arr) //打印结果val arr1=arr.cache()println("-----------------------------") //分隔符arr1.foreach(println) //专门用来打印未进行Action操作的数据的专用方法,可以对数据进行提早计算。}} |
3、rdd3_cartesian.notepackage RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.* 笛卡尔积操作cartsian方法*/object rdd3_cartesian {/*** 此方法用于对不同的数组进行笛卡尔积操作,要求是数据集的长度必须相同,结果作为一个新的数据集返回*/def main(args: Array[String]) {val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd3_cartesian") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val arr=sc.parallelize(Array(1,2,3,4,5)) //创建第一个数组val arr1=sc.parallelize(Array(6,7,8,9,10)) //创建第二个数组val result=arr.cartesian(arr1) //进行笛卡尔积计算result.foreach(println) //打印结果}} |
4、rdd4_coalesce.notepackage RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.*/object rdd4_coalesce {/*** coalesce方法是将已经存储的数据重新分片后再进行存储* 第一个参数是将数据重新分成的片数,布尔型数指的是将数据分成更小的片时使用。*/// def main(args: Array[String]) {// val conf=new SparkConf() //创建环境变量// .setMaster("local") //设置本地化处理// .setAppName("rdd4_coalesce") //设置名称// val sc=new SparkContext(conf) //创建环境变量实例// val arr=sc.parallelize(Array(1,2,3,4,5,6))// val arr2=arr.coalesce(2,true) //将数据重新分区// val result=arr.aggregate(0)(math.max(_,_),_+_) //计算数据值// println(result)// val result2=arr2.aggregate(0)(math.max(_,_),_+_) //计算重新分区数据值// println(result2)// }/*** RDD中还有一个repartition方法与这个coalesce方法类似,均是将数据重新分区组合*/def main(args: Array[String]) {val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd4_coalesce") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val arr=sc.parallelize(Array(1,2,3,4,5,6))val arr2=arr.repartition(3) //将数据分区println(arr2.partitions.length) //打印分区结果}}package RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.*/object rdd4_coalesce {/*** coalesce方法是将已经存储的数据重新分片后再进行存储* 第一个参数是将数据重新分成的片数,布尔型数指的是将数据分成更小的片时使用。*/// def main(args: Array[String]) {// val conf=new SparkConf() //创建环境变量// .setMaster("local") //设置本地化处理// .setAppName("rdd4_coalesce") //设置名称// val sc=new SparkContext(conf) //创建环境变量实例// val arr=sc.parallelize(Array(1,2,3,4,5,6))// val arr2=arr.coalesce(2,true) //将数据重新分区// val result=arr.aggregate(0)(math.max(_,_),_+_) //计算数据值// println(result)// val result2=arr2.aggregate(0)(math.max(_,_),_+_) //计算重新分区数据值// println(result2)// }/*** RDD中还有一个repartition方法与这个coalesce方法类似,均是将数据重新分区组合*/def main(args: Array[String]) {val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd4_coalesce") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val arr=sc.parallelize(Array(1,2,3,4,5,6))val arr2=arr.repartition(3) //将数据分区println(arr2.partitions.length) //打印分区结果}} |
示例2:5、rdd5_countByValue.notecountByValue用法:
package RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.*/object rdd5_countByValue {/*** countByValue方法是计算数据集中某个数据出现的个数,并将其以map的形式返回* @param args*/def main(args: Array[String]) {val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd5_countByValue") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val arr=sc.parallelize(Array(1,1,2,2,3,3,4,5,6))val result=arr.countByValue() //计算个数result.foreach(print)}}package RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.*/object rdd5_countByValue {/*** countByValue方法是计算数据集中某个数据出现的个数,并将其以map的形式返回* @param args*/def main(args: Array[String]) {val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd5_countByValue") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val arr=sc.parallelize(Array(1,1,2,2,3,3,4,5,6))val result=arr.countByValue() //计算个数result.foreach(print)}} |
6、rdd6_countByKey.notepackage RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.*/object rdd6_countByKey {/*** countByKey方法与countByValue方法有本质的区别。* countByKey是计算数组中元数据键值对Key出现的个数*/def main(args: Array[String]) {val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd6_countByKey") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val arr=sc.parallelize(Array((1,"hadoop"),(2,"spark"),(3,"tachyon")))val result=arr.countByKey() //进行计数result.foreach(print)}} |
7、rdd7_distinct.notedistinct方法:package RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.*/object rdd7_distinct {/*** distinct方法作用是去除数据集中重复项*/def main(args: Array[String]) {val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd7_distinct") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val arr=sc.parallelize(Array(("hadoop"),("spark"),("hive"),("hadoop"),("hive")))val result=arr.distinct()result.foreach(println)}} |
8、rdd8_filter.notefilter方法:package RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.*/object rdd8_filter {/*** filter方法用来对数据集进行过滤*/def main(args: Array[String]) {val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd8_filter") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val arr=sc.parallelize(Array(1,2,3,4,5))val result=arr.filter(_>=3)result.foreach(println)}} |
9、rdd9_flatMap.noteflatMap方法:package RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.*/object rdd9_flatMap {def main(args: Array[String]) {/*** flatMap方法是对RDD中的数据集进行整体操作的一个特殊方法。*/val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd9_flatMap") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val arr=sc.parallelize(Array(1,2,3,4,5,6,7))val result=arr.flatMap(x=>List(x+1)).collect() //进行数据集计算result.foreach(println)}} |
10、rdd10_map .notemap方法:package RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.*/object rdd10_map {/*** map方法是对RDD中的数据集中的数据进行逐个处理。* map与flatMap不同之处在于,flatMap是将数据集中的数据作为一个整体去处理,之后再对其中的数据做计算。* 而map方法直接对数据集中的数据做单独的处理。*/def main(args: Array[String]) {val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd10_map") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val arr=sc.parallelize(Array(1,2,3,4,5,6))val result=arr.map(x=>List(x+1)).collect()result.foreach(println)}} |
11、rdd11_groupBy .notegroup方法:package RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.*/object rdd11_groupBy {/*** groupBy方法是将传入的数据进行分组* 传入的第一个参数是方法名,第二个参数是分组的标签*/def main(args: Array[String]) {val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd11_groupBy") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val arr=sc.parallelize(Array(1,2,3,4,5,6))arr.groupBy(myFilter1).foreach(println) //设置第一个分组}def myFilter1(num:Int):Int={ //自定义第一个分组num %2}} |
12、rdd12_keyBy .notekeyBy方法:package RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.*/object rdd12_keyBy {/*** keyBy方法是为数据集中的每个个体数据增加一个Key,从而可以和原来的数据集形成键值对。*/def main(args: Array[String]) {val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd12_keyBy") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val arr=sc.parallelize(Array("hadoop","spark","tachyon","hive","hbase"))val str=arr.keyBy(word=>word.size) //设置配置方法str.foreach(println)}} |
13、rdd13_reduce.notereduce方法:package RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.*/object rdd13_reduce {/*** reduce方法主要是对传入的数据进行合并处理。* 第一个下划线代表数据集中的第一个参数。* 第二个下划线在第一次合并处理时代表空集*/def main(args: Array[String]) {// val conf=new SparkConf() //创建环境变量// .setMaster("local") //设置本地化处理// .setAppName("rdd13_reduce") //设置名称// val sc=new SparkContext(conf) //创建环境变量实例// val arr=sc.parallelize(Array("hadoop","spark","tachyon","hive","hbase"))// val result=arr.reduce(_+_)// result.foreach(print)/*** 寻找最长字符串*/val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd13_reduce") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val str=sc.parallelize(Array("hadoop","spark","tachyon","hive"))val result=str.reduce(myFun) //进行数据拟合result.foreach(print)}def myFun(str1:String,str2:String):String={var str=str1if(str2.size>=str.size){str=str2}return str}} |
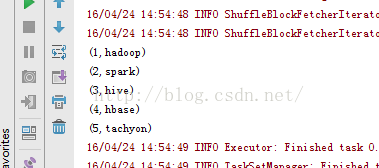
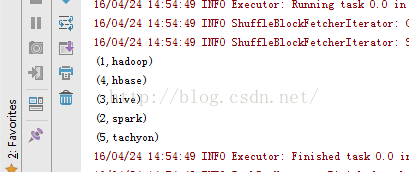
示例二:14、rdd14_sortBy.notesortBy方法:package RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.*/object rdd14_sortBy {/*** sortBy方法是一个常用的排序方法,其功能是对已有的RDD重新排序,并将重新排序后的数据生成一个新的RDD。* sortBy有3个参数:* 第一个参数:传入方法,用以计算排序的方法* 第二个参数:指定排序的值按升序还是降序显示* 第三个参数:分片的数量*/def main(args: Array[String]) {val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd14_sortBy") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val str=sc.parallelize(Array((1,"hadoop"),(2,"spark"),(3,"hive"),(4,"hbase"),(5,"tachyon")))val str1=str.sortBy(word=>word._1,true) //按照第一个数据排序val str2=str.sortBy(word=>word._2,true) //按照第二个数据排序str1.foreach(println)str2.foreach(println)}} |
按照第一个数据排序:
按照第二个数据排序:
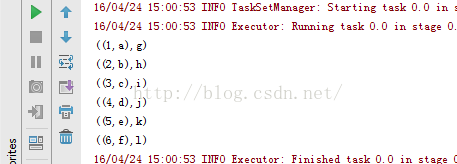
15、rdd15_zip.notezip方法:package RddApiimport org.apache.spark.{SparkConf, SparkContext}/*** Created by Administrator on 2016/4/24.* zip方法是常用的合并压缩算法,它将若干个RDD压缩成一个新的DD,进而形成一系列的键值对存储形式的新RDD。*/object rdd15_zip {def main(args: Array[String]) {val conf=new SparkConf() //创建环境变量.setMaster("local") //设置本地化处理.setAppName("rdd15_zip") //设置名称val sc=new SparkContext(conf) //创建环境变量实例val arr1=sc.parallelize(Array(1,2,3,4,5,6))val arr2=sc.parallelize(Array("a","b","c","d","e","f"))val arr3=sc.parallelize(Array("g","h","i","j","k","l"))val arr4=arr1.zip(arr2).zip(arr3) //进行压缩算法arr4.foreach(println)}} |

相关文章推荐
- Hive – Distinct 的实现
- iOS引用计数
- virsh console和shutdown的两个补充
- Volley源码解析——从实现角度深入剖析volley
- [3.1]Spark Streaming初体验之NetworkWordCount案例完美解读
- 学习SpringMVC(三)之RequestParam
- Android开发利器
- tomcat 基于apr配置https
- Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock'
- Javascript复习第五天几种对象的创建方式
- 【ZJOI2008】树的统计
- 线程的基本概念状态和之间的关系
- SerializeField和HideInInspector
- 代码能力并不是你最重要的能力 !! ---IBM数据摇滚节参赛感悟
- 代码能力并不是你最重要的能力 !! ---IBM数据摇滚节参赛感悟
- 线程的基本概念,状态,和状态之间的关系
- maven基础篇(2)-基本配置说明
- 一种为使用Log4j的分布式应用提供云端日志服务的方法
- 802.11MAC帧分析
- 线性表的顺序存储——顺序表