[3.1]Spark Streaming初体验之NetworkWordCount案例完美解读
2016-05-14 13:23
405 查看
参考
DT大数据梦工厂@王家林系列Spark Streaming官网
场景
分别用scala与java写一个Spark应用程序:实时监听、接收并计算某socket中字符及其出现的次数。例如:在socket中输入 “hello world hello spark” 则计算结果为 (hello,2) (world,1) (spark,1)实验
java版
package cool.pengych.spark.streaming;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
public class WordCountOnline
{
public static void main(String[] args)
{
/*
* 第一步:配置SparkConf
*/
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("WordCountOnline");
/*
* 第二步:创建SparkStreamingContext
*/
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(1));
/*
* 第三步:创建Spark Streaming输入数据来源 input stream
*/
JavaReceiverInputDStream<String> lines = jsc.socketTextStream("localhost", 9999);
/*
*第四步:基于DStream进行编程
*/
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String line) throws Exception{
return Arrays.asList(line.split(" "));
}
});
JavaPairDStream<String,Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String,Integer> call(String word) throws Exception{
return new Tuple2<String,Integer>(word,1);
}
});
JavaPairDStream<String, Integer> wordsCount = pairs.reduceByKey(new Function2<Integer,Integer,Integer>(){
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
wordsCount.print();
/*
* 第五步:启动StreamingContext的执行.
*/
jsc.start();
jsc.awaitTermination();
}
}scala官网版
package main.scala
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.DStream.toPairDStreamFunctions
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit(1)
}
// Create the context with a 1 second batch size
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
// Create a socket stream on target ip:port and count the
// words in input stream of \n delimited text (eg. generated by 'nc')
// Note that no duplication in storage level only for running locally.
// Replication necessary in distributed scenario for fault tolerance.
val lines = ssc.socketTextStream("localhost", 9999,StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
// scalastyle:on printlnscala精简版
package main.scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.dstream.DStream
object WordsCountOnline {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("Network words onLine")
val ssc = new StreamingContext(sparkConf,Seconds(1))
ssc.socketTextStream("localhost", 9999, StorageLevel.MEMORY_AND_DISK_SER).flatMap { line =>line.split(" ") }.map { word => (word,1) }.reduceByKey(_+_).print
ssc.start()
ssc.awaitTerminationOrTimeout(10000)
}
}执行结果
16/05/14 12:19:10 INFO DAGScheduler: Job 16 finished: print at WordsCountOnline.scala:20, took 0.018674 s ------------------------------------------- Time: 1463199550000 ms ------------------------------------------- (yes,3) (yse,1) 16/05/14 12:19:10 INFO JobScheduler: Finished job streaming job 1463199550000 ms.0 from job set of time 1463199550000 ms
执行过程
第一步:配置SparkConf
1、至少2条线程:因为spark streaming 应用程序在运行的时候至少有一条线程在不断的循环接收数据,并且至少有一条线程用于处理接收的数据,否则的话,随着时间的推移,内存和磁盘都会不堪重负。2、对于集群而言,每个Excecutor一般肯定不止一个Thread,那对于处理Spark Streaming的应用程序而言,每个Executor一般分配多少Core比较合适?经验:5个左右是最佳的!
第二步:创建SparkStreamingContext
1、SparkStreaming应用程序所有功能的其始点和程序调度的核心。SparkStreamingContext的构建可以基于SparkConf参数,也可基于持久化的SparkStreamingContext的内容恢复过来:典型的场景是Driver崩溃后重新启动,由于Spark Streaming具有连续7*24小时不间断运行的特征,所有需要在Driver重新启动后继续上一次的状态,此时状态的恢复需要基于曾经的checkpoint。2、在一个Spark Streaming应用程序中可以创建若干个SparkStreamingContext对象,使用下一个SparkStreaming之前要把前面正在运行的SparkStreamingContext对象关闭调,由此,我们获得一个重大启发:SparkStreaming只是Spark Core上的一个应用程序而已,只不过Spark Streaming构架箱运行的话需要Spark工程师写业务逻辑处理数据。
第三步:创建Spark Streaming输入数据来源 input stream

1、数据输入来源可以基于 File、HDFS、Flume、Kafka、Socket等。
2、以socket端口为例,Spark streaming链接上该端口并在运行的时候一直监听该端口的数据(当然该端口服务必须存在:nt -lk 9999 :在本地启动一个socket服务,该服务监听并接收从端口9999写入的数据),并且在后续会根据业务需要不断的有数据产生。
3、如果经常在每间隔5秒钟没有数据的话,不断启动空的Job其实会造成调度资源的浪费,因为并没有数据需要发生计算。
实际的企业级生成环境的代码在具体提交Job 前会判断是否有数据,没有的话就不再提交Job。
第四步:基于DStream编程
就像对于RDD编程一样基于DStream进行编程。DStream是RDD产生的类,在SparkStreaming具体发生计算前,其实质是把每个Batch的DStream的操作翻译成为对RDD的操作。注:
1、Spark Streamig应用程序要执行具体的Job,对DStream就必须有output Stream的操作,output Stream有很多类型的触发函数例如:print、savaAsTextFile etc。其中最重要的一个方法是foreachRDD,因为Spark Streaming处理的结果,一般都会放在Redis、DB、DashBoard等上面,foreachRDD主要就是用来完成这些功能的,而且可以随意的自定义具体数据到底放在哪里。
2、print 并不会直接触发Job的执行 ,因为现在的一切都是在Spark Streaming框架的控制之下的,对于Spark Streaming而言具体是否真正触发Job运行是基于设置的Durations时间间隔。
3、Spark Streaming执行引擎也就是Driver开始运行,Driver启动的时候是位于一条新的线程中的,当然其内部有消息循环体,用于接收应用程序本身或者Excecutor中的消息。
总结
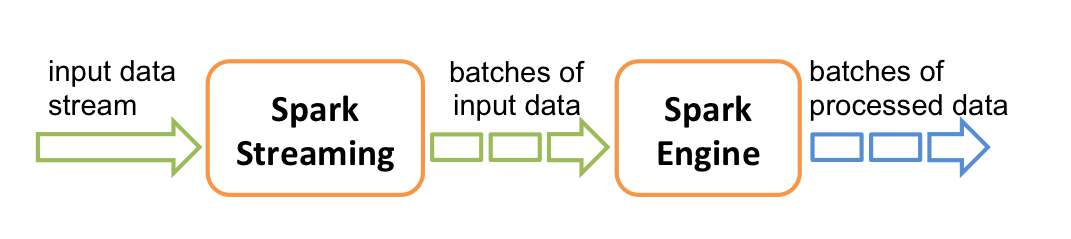
DStream(discretized stream)是RDD产生的类或者抽象(a DStream is represented as a sequence of RDDs.),在SparkStreaming具体发生计算前,其实质是把每个Batch的DStream操作翻译成为对RDD的操作。

相关文章推荐
- 学习SpringMVC(三)之RequestParam
- Android开发利器
- tomcat 基于apr配置https
- Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock'
- Javascript复习第五天几种对象的创建方式
- 【ZJOI2008】树的统计
- 线程的基本概念状态和之间的关系
- SerializeField和HideInInspector
- 代码能力并不是你最重要的能力 !! ---IBM数据摇滚节参赛感悟
- 代码能力并不是你最重要的能力 !! ---IBM数据摇滚节参赛感悟
- 线程的基本概念,状态,和状态之间的关系
- maven基础篇(2)-基本配置说明
- 一种为使用Log4j的分布式应用提供云端日志服务的方法
- 802.11MAC帧分析
- 线性表的顺序存储——顺序表
- 排序 希尔排序
- boost.asio学习
- 数据结构(c)——排序算法
- 亚信笔试题
- 求x的y次幂