Linun文本搜索之grep及正则表达式
2016-03-12 10:56
495 查看
GNU/Linux中常用的文本处理工具有三种:
grep、egrep、fgrep:文本搜索工具;
sed:流编辑器、文本编辑工具;
awk:文本报告生成器;
今天主要来说一下grep和正则表达式;
一、概述
grep(Global search REgular expression and Print out the line.),是一个文本搜索工具;根据指定“pattern(过滤条件)”对目标文本逐行进行匹配检查并打印出符合条件的行;
什么是正则表达式?
正则表达式:由一类特殊字符及文本字符所编写的模式,有些字符不表示其字面意义,而是用于表示控制或通配的功能;
而正则表达式又分为两类:
基本正则表达式:BRE
扩展正则表达式:ERE
正则表达式引擎:利用正则表达式模式分析所给定的文本的程序。
grep家族:
grep:支持使用基本正则表达式,(也可以使用一个选项“-E”支持扩展的正则表达式;到下面再说);
egrep:支持使用扩展
正则表达式;
fgrep:不支持使用正则表达式;
grep命令
grep [选项] [模式] [FILE...]
常用选项示例:
-i:忽略字符大小写;
--color=auto:对匹配到的文本着色后高亮显示(这里指的是CentOS 7);

-A num:显示匹配到的行的后n行;
-E:相当于“egrep”,表示支持扩展的正则表达式(下面会说);
-F:支持使用固定字符串,不支持正则表达式,相当于fgrep;
基本正则表达式元字符:
(1)字符匹配
.:匹配任意单个字符;
[]:匹配范围内的任意单个字符;
[^]:匹配范围外的任意单个字符;
[a-z]:所有小写字母;
[A-Z]:所有大写字母;
[0-9]:所有数字;
[:digit:]:所有的数字;
[:lower:]:所有小写字母;
[:upper:]:所有大写字母;
[:alpha:]:任意字母(包括大小写);
[:alnum:]:所有字母和数字;
[:space:]:空白字符;
[:punct:]:标点符号;
[:blank:]:空格和Tab键;
[:cntrl:]:所有的控制符(Ctrl+#);
[:print:]:所有可打印字符;
可使用man 7 glob查看;
示例:
.:查找/etc/passwd文件中以“r”开头“t”结尾中间跟了两个任意单个字符的行;
*:匹配其前面的字符任意次(包括0次);
.*:任意长度的任意字符;
\{m\}:前面的字符精确出现m次,m为非负数整数;
\{m,n\}:前面的字符出现至少m次,至多n次;
\{m,\}:至少m次,多了不限;
\{0,n\}:至多n次;
限制使用模式搜索文本,限制模式所匹配到的文本只能出现于目标文本的哪个位置;
^:行首锚定;用于模式的最左侧,^PATTERN
$:行尾锚定;用户模式的最右侧,PATTERN$
^PATTERN$:整行匹配;
^$:空行;也不能有空白字符及Tab键;
^[[:space:]]*$:查找只有空白字符的行;并统计有多少行;
单词:由非特殊字符组成的连续字符都称为单词;
\<或\b:词首锚定,用于单词模式的左侧,格式为\<PATTERN, \bPATTERN ;
练习:
查找“netstat -tan”命令的结果中,以“LISTEN”后跟0个或多个空白字符结尾的行;

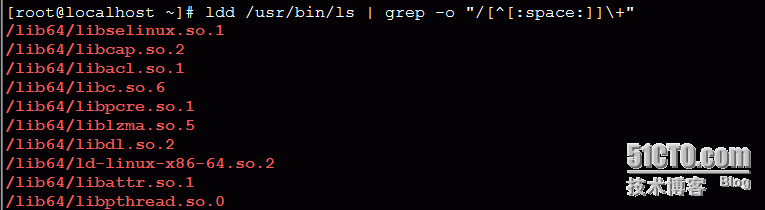
查找“ldd /usr/bin/ls”命令的结果中文件路径;
查找/etc/grub2.cfg文件中,以至少一个空白字符开头,后面又跟了非空白字符的行;

(4)分组与引用
\(PATTERN\):将次PATTERN匹配到的字符当做一个整体进行处理;
注意:分组括号中的模式匹配到的字符会被正则表达式引擎自动记录于内部的变量中,这些变量是\1,\2,\3,....
\n:模式中第n个左括号以及与之匹配的右括号之间的模式所匹配到的结果;
示例:
后向引用:引用前面括号中的模式所匹配到的字符串;
\1表示引用前面模式匹配到的结果后面加一个“r”的行;

二、扩展正则表达式
egrep:支持使用扩展正则表达式,相当于“grep -E”
扩展正则表达式的元字符:多数和上面一样,这里知举例说明不同之处;
字符匹配:
.:任意单个字符;
[]:范围内的任意单个字符;
[^]:范围外的任意单个字符;
次数匹配:
*:任意次;
?:0次或一次;
+:匹配其前面的字符1次或多次;
位置锚定:
^:行首
$:行尾
\<,\b:词首
\>,\b:词尾
分组及引用
(pattern):分组,括号中的模式匹配到的字符会被记录与正则表达式引擎内部的变量中;

或者:表示C或者cat; ls或者LS;

第一次写博客,写的不是很好,请多多指教。

本文出自 “黑白琴键、” 博客,请务必保留此出处http://lizonglun.blog.51cto.com/11039641/1750170
grep、egrep、fgrep:文本搜索工具;
sed:流编辑器、文本编辑工具;
awk:文本报告生成器;
今天主要来说一下grep和正则表达式;
一、概述
grep(Global search REgular expression and Print out the line.),是一个文本搜索工具;根据指定“pattern(过滤条件)”对目标文本逐行进行匹配检查并打印出符合条件的行;
什么是正则表达式?
正则表达式:由一类特殊字符及文本字符所编写的模式,有些字符不表示其字面意义,而是用于表示控制或通配的功能;
而正则表达式又分为两类:
基本正则表达式:BRE
扩展正则表达式:ERE
正则表达式引擎:利用正则表达式模式分析所给定的文本的程序。
grep家族:
grep:支持使用基本正则表达式,(也可以使用一个选项“-E”支持扩展的正则表达式;到下面再说);
egrep:支持使用扩展
正则表达式;
fgrep:不支持使用正则表达式;
grep命令
grep [选项] [模式] [FILE...]
常用选项示例:
-i:忽略字符大小写;
[root@localhost~]# cat test.txt He love his lover. he like his lover. he love his liker. He like his liker. [root@localhost~]# grep -i "he" test.txt He lovehis lover. he likehis lover. he lovehis liker. He likehis liker.-n:显示行号;
[root@localhost ~]# grep -ni "he" test.txt 1:He love his lover. 2:he like his lover. 3:he love his liker. 4:He like his liker.-o:仅显示匹配到的文本自身;
[root@localhost ~]# grep "bash$" /etc/passwd root:x:0:0:root:/root:/bin/bash mageedu:x:1000:1000:mageedu:/home/mageedu:/bin/bash gentoo:x:3003:3003::/home/gentoo:/bin/bash ubuntu:x:3004:4004::/home/ubuntu:/bin/bash mint:x:3100:3100::/home/mint:/bin/bash hadoop:x:3102:3102::/home/hadoop:/bin/bash hive:x:991:986::/home/hive:/bin/bash linxuejing:x:3103:3103::/home/linxuejing:/bin/bash [root@localhost ~]# grep -o "bash$" /etc/passwd bash bash bash bash bash bash bash bash 注:这里首先是显示以bash结尾的行,然后加“-o”选项只显示匹配到字符串本身;-v:--invert-match:取反,反相匹配;
[root@localhost ~]# grep -v "bash$" /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin ...... 注:显示不是以“bash”结尾的行;
--color=auto:对匹配到的文本着色后高亮显示(这里指的是CentOS 7);
# alias alias cp='cp -i' alias egrep='egrep --color=auto' alias fgrep='fgrep --color=auto' alias grep='grep --color=auto' alias l.='ls -d .* --color=auto' alias ll='ls -l --color=auto' alias ls='ls --color=auto' alias mv='mv -i' alias rm='rm -i' alias which='alias | /usr/bin/which--tty-only --read-alias --show-dot --show-tilde' 注:CentOS 5,6的话需要以alias grep='grep --color=auto'手动来定义;-q,--quiet:静默模式,不输出任何信息;
root@localhost ~]# grep -q "root"/etc/passwd [root@localhost ~]# echo $? 0 可使用“$?”来显示上条命令的执行状态结果,“0”表示成功,有匹配到字符串;-e PATTERN:多模式匹配;
[root@localhost~]# grep -e "r..t" -e "b..h" /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin ftp:x:14:50:FTPUser:/var/ftp:/sbin/nologin chrony:x:993:990::/var/lib/chrony:/sbin/nologin mageedu:x:1000:1000:mageedu:/home/mageedu:/bin/bash gentoo:x:3003:3003::/home/gentoo:/bin/bash ubuntu:x:3004:4004::/home/ubuntu:/bin/bash mint:x:3100:3100::/home/mint:/bin/bash hadoop:x:3102:3102::/home/hadoop:/bin/bash hive:x:991:986::/home/hive:/bin/bash linxuejing:x:3103:3103::/home/linxuejing:/bin/bash-f FILE:FILE为每行包含了一个pattern的文本文件,及grep script;
[root@localhost~]# vim grep.txt root bash
-A num:显示匹配到的行的后n行;
[root@localhost ~]# grep -A 1"hadoop" /etc/passwd hadoop:x:3102:3102::/home/hadoop:/bin/bash hive:x:991:986::/home/hive:/bin/bash-B num:显示匹配到的行的前n行;
[root@localhost ~]# grep -B 1 "hadoop" /etc/passwd fedora:x:3101:3101::/home/fedora:/bin/csh hadoop:x:3102:3102::/home/hadoop:/bin/bash-C num:显示匹配到行的前后n行;
[root@localhost ~]# grep -C 2 "hadoop" /etc/passwd mint:x:3100:3100::/home/mint:/bin/bash fedora:x:3101:3101::/home/fedora:/bin/csh hadoop:x:3102:3102::/home/hadoop:/bin/bash hive:x:991:986::/home/hive:/bin/bash linxuejing:x:3103:3103::/home/linxuejing:/bin/bash
-E:相当于“egrep”,表示支持扩展的正则表达式(下面会说);
-F:支持使用固定字符串,不支持正则表达式,相当于fgrep;
基本正则表达式元字符:
(1)字符匹配
.:匹配任意单个字符;
[]:匹配范围内的任意单个字符;
[^]:匹配范围外的任意单个字符;
[a-z]:所有小写字母;
[A-Z]:所有大写字母;
[0-9]:所有数字;
[:digit:]:所有的数字;
[:lower:]:所有小写字母;
[:upper:]:所有大写字母;
[:alpha:]:任意字母(包括大小写);
[:alnum:]:所有字母和数字;
[:space:]:空白字符;
[:punct:]:标点符号;
[:blank:]:空格和Tab键;
[:cntrl:]:所有的控制符(Ctrl+#);
[:print:]:所有可打印字符;
可使用man 7 glob查看;
示例:
.:查找/etc/passwd文件中以“r”开头“t”结尾中间跟了两个任意单个字符的行;
[root@localhost ~]# grep "r..t" /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin[]:查找/tmp/meminfo文件中以S或s开头的行;
[root@localhost ~]# grep"^[Ss]" /tmp/meminfo SwapCached: 0 kB SwapTotal: 2098172 kB SwapFree: 2098172 kB Shmem: 13128 kB Slab: 234936 kB SReclaimable: 193688 kB SUnreclaim: 41248 kB swap[a-z]:表示“i”后面根两个字符不区分大小写的行;
[root@localhost ~]# ifconfig | grep -i"i[a-z][a-z]" eno16777736:flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu1500 inet 192.168.254.130 netmask 255.255.255.0 broadcast 192.168.254.255 inet6 fe80::20c:29ff:fe8e:eb7c prefixlen64 scopeid 0x20<link> TX errors 0 dropped 0 overruns0 carrier0 collisions0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu65536 inet 127.0.0.1 netmask 255.0.0.0 inet6::1 prefixlen128 scopeid 0x10<host> TX errors 0 dropped 0 overruns0 carrier0 collisions0[[:alpha:]]:查找文件中以任意字母开头的行;
[root@localhost ~]# grep"^[[:alpha:]]" /tmp/grub2.cfg
set pager=1
LH
if [ -s $prefix/grubenv ]; then
fi
if [ "${next_entry}" ] ; then
else
fi
if [ x"${feature_menuentry_id}" =xy ]; then
else
fi
........(2)次数匹配:*:匹配其前面的字符任意次(包括0次);
[root@localhost ~]# grep "x*y"test2.txt abcy yabcd xxxyabc abgdsfy asdy\+:匹配其前面的字符至少1次;
[root@localhost ~]# grep "x\+y"test2.txt xxxyabc
.*:任意长度的任意字符;
[root@localhost ~]# grep"x.*y" test2.txt xxxyabc xjgbdfg,n,gnjgy9\?:匹配前面的字符0次或1次(最多一次),前面的可有可无;
[root@localhost~]# grep "x\?y" test2.txt abcy yabcd xxxyabc abgdsfy asdy xjgbdfg,n,gnjgy
\{m\}:前面的字符精确出现m次,m为非负数整数;
root@localhost~]# grep "x\{2\}" test2.txt
xxxyabc\{m,n\}:前面的字符出现至少m次,至多n次;
\{m,\}:至少m次,多了不限;
\{0,n\}:至多n次;
[root@localhost~]# grep "x\{1,3\}y" test2.txt
xxxyabc
[root@localhost~]# grep "x\{3,\}y" test2.txt
xxxyabc# 显示“i”后面出现3个字符;
[root@localhost~]# ifconfig | grep"i[[:alpha:]]\{3\}"
inet 192.168.254.130 netmask255.255.255.0 broadcast 192.168.254.255
inet6 fe80::20c:29ff:fe8e:eb7c prefixlen 64 scopeid0x20<link>
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0(3)位置锚定限制使用模式搜索文本,限制模式所匹配到的文本只能出现于目标文本的哪个位置;
^:行首锚定;用于模式的最左侧,^PATTERN
[root@localhost~]# grep "^root" /etc/passwd root:x:0:0:root:/root:/bin/bash # 显示以root字符串开头的行;
$:行尾锚定;用户模式的最右侧,PATTERN$
^PATTERN$:整行匹配;
^$:空行;也不能有空白字符及Tab键;
^[[:space:]]*$:查找只有空白字符的行;并统计有多少行;
[root@localhost~]# grep "^[[:space:]]*$" /etc/grub2.cfg | wc -l 17单词锚定:\<PATTERN\>
单词:由非特殊字符组成的连续字符都称为单词;
[root@localhost ~]# cat test3.txt root rootls rootnkll openroot [root@localhost ~]# grep "\<root\>" test3.txt root
\<或\b:词首锚定,用于单词模式的左侧,格式为\<PATTERN, \bPATTERN ;
[root@localhost~]# grep "\<root" /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin\>或\b:词尾锚定,用于单词模式的右侧,格式为PATTERN\>, PATTERN\b ;
[root@localhost~]# grep "bash\>" /etc/passwd root:x:0:0:root:/root:/bin/bash mageedu:x:1000:1000:mageedu:/home/mageedu:/bin/bash gentoo:x:3003:3003::/home/gentoo:/bin/bash ubuntu:x:3004:4004::/home/ubuntu:/bin/bash mint:x:3100:3100::/home/mint:/bin/bash hadoop:x:3102:3102::/home/hadoop:/bin/bash hive:x:991:986::/home/hive:/bin/bash linxuejing:x:3103:3103::/home/linxuejing:/bin/bash
练习:
查找“netstat -tan”命令的结果中,以“LISTEN”后跟0个或多个空白字符结尾的行;
查找“ldd /usr/bin/ls”命令的结果中文件路径;
查找/etc/grub2.cfg文件中,以至少一个空白字符开头,后面又跟了非空白字符的行;
(4)分组与引用
\(PATTERN\):将次PATTERN匹配到的字符当做一个整体进行处理;
注意:分组括号中的模式匹配到的字符会被正则表达式引擎自动记录于内部的变量中,这些变量是\1,\2,\3,....
\n:模式中第n个左括号以及与之匹配的右括号之间的模式所匹配到的结果;
示例:
后向引用:引用前面括号中的模式所匹配到的字符串;
\1表示引用前面模式匹配到的结果后面加一个“r”的行;
二、扩展正则表达式
egrep:支持使用扩展正则表达式,相当于“grep -E”
扩展正则表达式的元字符:多数和上面一样,这里知举例说明不同之处;
字符匹配:
.:任意单个字符;
[]:范围内的任意单个字符;
[^]:范围外的任意单个字符;
次数匹配:
*:任意次;
?:0次或一次;
root@localhost~]# egrep "x?y" test2.txt abcy yabcd xxxxxxxxyabc abgdsfy asdy xjgbdfg,n,gnjgy
+:匹配其前面的字符1次或多次;
[root@localhost~]# egrep "x+y" test2.txt xxxxxxxxyabc{m}:精确匹配m次;
[root@localhost~]# egrep "x{5}y" test2.txt
xxxxxxxxyabc
# 精确匹配前面的字符5次; {m,n}:至少m次,至多n次;[root@localhost~]# egrep "x{3,6}y" test2.txt
xxxxxxxxyabc
# 匹配前面的字符至少3次,至多6次;位置锚定:
^:行首
$:行尾
\<,\b:词首
\>,\b:词尾
分组及引用
(pattern):分组,括号中的模式匹配到的字符会被记录与正则表达式引擎内部的变量中;
或者:表示C或者cat; ls或者LS;
第一次写博客,写的不是很好,请多多指教。
本文出自 “黑白琴键、” 博客,请务必保留此出处http://lizonglun.blog.51cto.com/11039641/1750170

相关文章推荐
- android的消息处理机制
- E. The shortest problem
- 进军pc市场 华为剑走偏锋可有戏?
- 复制vmware虚拟机后,eth0无法显示问题
- javascript 同源策略
- Python缓存机制介绍
- Android 中Webview 自适应屏幕
- 三十而立
- 【杭电】[3790]最短路径问题
- 面向对象与面向过程的区别
- 多线程(三)
- C++中的main函数
- Linux 文件系统与设备文件系统 (一)—— udev 设备文件系统
- linux 设置用户ID、设置组ID
- Tcl internal variables
- Android开发之创建App Widget和更新Widget内容
- XMAPP,非本地访问phpmyadmin出现Access forbidden的问题
- JavaScript进阶之路——认识和使用Promise,重构你的Js代码
- Shadow mapping
- 学习进度条