自己开发网站全文检索系统
2016-01-11 20:43
661 查看
注:
- 原文: 自己开发网站全文检索系统(Nob)
- 本文永久更新链接,markdown格式源码 Github: Aidan Dai
概述
1 问题提出
2 解决的办法
全文检索系统设计与实现策略
1 系统的架构
2 模块设计
3 系统整体运作流程
实验系统执行Experiment
1 实验的目标
2 实验步骤
1.2.1 什么是全文检索
全文检索是一种将文件中所有文本与检索项匹配的文字资料检索方法。全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。
目前最大的搜索引擎Google和Baidu使用的就是全文检索技术。当然Google基于Google三宝(GFS、MapReduce、BigTable)构建了庞大的大数据处理平台。全文检索是搜索引擎技术的一个重要部分。
1.2.2. 数据分类
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据:指没有固定格式或不定长的数据,如邮件,word文档等。
非结构化数据还有一种叫法:全文数据。
1.2.3. 按数据的分类,搜索也分为两种
对结构化数据的搜索:
如对数据库的搜索:SQL语句。再如windows的搜索:文件名,类型,修改时间。
对非结构化数据的搜索:
如windows对文件内容的搜索。Linux下得grep命令。再如Google和百度可以搜素大量内容数据。
对于非结构化的数据搜索也叫做对全文数据的搜索。要获得良好的搜索体验,全文检索技术可以达到这一点。对全文数据的搜索还可以分为两种:
1、顺序扫描:如要找内容包含某个字符串的文件,会一个文档一个文档的从头到尾的找,如 Like查找 。
2、索引扫描:把非结构化的数据中的内容提取出来一部分重新组织,让它变的有结构化,这部分我们提取出来的数据就叫做索引.
单纯的使用数据库提供的全文搜索已经不能满足站点对于搜索功能的要求,目前大数据时代想要从海量数据中获取必要数据,建立强大的全文检索系统十分必要。

索引创建(Indexer)和 搜索索引(Search)。
搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
2.2.1. 信息处理
信息处理模块的核心就是索引的创建。
索引里面究竟存些什么?(Index)
索引所保存的信息一般如下:
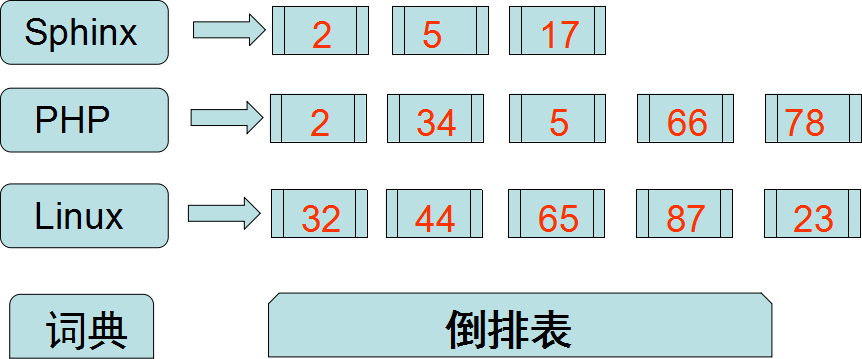
假设我现在有100篇文档,从1到100表示。
词典: 保存的是一系列的字符串。
倒排表: 指向包含字符串的文档链表。
如何创建索引?
全文检索的索引创建过程一般有以下几步:
一些需要创建索引的文档(Documents)。
将原文档传给分词组件(Tokenizer) 。
将得到的词元(Token)传给语言处理组件(Linguistic Processor)。
将得到的词(Term)传给索引组件(Indexer)。
合并相同的词(Term)成为文档倒排(Posting List)链表

Document Frequenc :即文档频次,表示总共有多少文件包含此词(Term)
Frequency :即词频率,表示此文件中包含了几个此词(Term)
补充:创建索引是系统的核心任务,需对主题词典处理、信息消重、文档建模、文档分析和过滤以及建立倒排索引。还需要要处理停词(如一些意义不大的虚词)。
2.2.2. 查询服务
查询服务的重点是搜索索引。
如何对索引进行搜索
搜索主要分为以下几步:
第一步:用户输入查询语句.
第二步:对查询语句进行词法分析,语法分析,及语言处理
第三步:搜索索引,得到符合语法树的文档.
第四步:根据得到的文档和查询语句的相关性,对结果进行排序.
查看Google搜索:
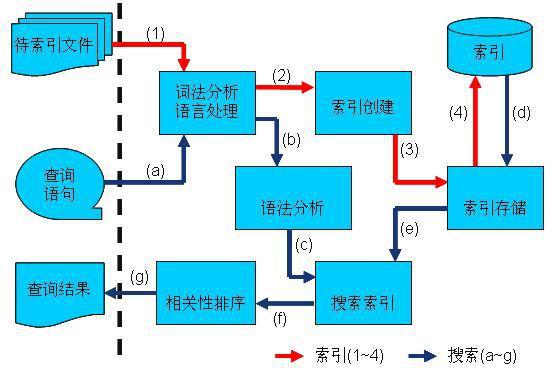
(1)、有一系列被索引文件
(2)、被索引文件经过语法分析和语言处理形成一系列词(Term)。
(3)、经过索引创建形成词典和反向索引表。
(4)、通过索引存储将索引写入硬盘。
2.3.2. 搜索过程:
(a) 用户输入查询语句。
(b) 对查询语句经过语法分析和语言分析得到一系列词(Term)。
(c) 通过语法分析得到一个查询树。
(d) 通过索引存储将索引读入到内存。
(e) 利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交,差,并得到结果文档。
(f) 将搜索到的结果文档对查询的相关性进行排序。
(g) 返回查询结果给用户。
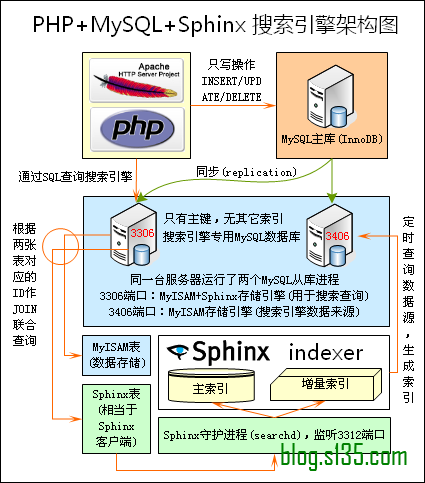
基于开源的搜索引擎coreseek来搭建本次实验系统。Coreseek是基于Sphinx的中文全文检索系统,良好的支持了中文分词。但是基本原理是配置方法和Sphinx类似。
Sphinx是一个基于SQL的全文检索引擎,可以结合MySQL,PostgreSQL做全文搜索,它可以提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索。
(2)、创建数据源(略)
(3)、安装测试coreseek(请参考我的另一篇博文)
(4)、搭建php WEB全文检索
其余内容请参见原文
- 原文: 自己开发网站全文检索系统(Nob)
- 本文永久更新链接,markdown格式源码 Github: Aidan Dai
概述
1 问题提出
2 解决的办法
全文检索系统设计与实现策略
1 系统的架构
2 模块设计
3 系统整体运作流程
实验系统执行Experiment
1 实验的目标
2 实验步骤
1. 概述
1.1. 问题提出
假如你拥有一个庞大的网站,内容又多,那么来访者往往很难找到自己所需要的东东,这时候你就需要一个站内搜索来帮助来访者更快的找到索要的资料了!1.2. 解决的办法
搭建自己的全文检索系统。1.2.1 什么是全文检索
全文检索是一种将文件中所有文本与检索项匹配的文字资料检索方法。全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。
目前最大的搜索引擎Google和Baidu使用的就是全文检索技术。当然Google基于Google三宝(GFS、MapReduce、BigTable)构建了庞大的大数据处理平台。全文检索是搜索引擎技术的一个重要部分。
1.2.2. 数据分类
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据:指没有固定格式或不定长的数据,如邮件,word文档等。
非结构化数据还有一种叫法:全文数据。
1.2.3. 按数据的分类,搜索也分为两种
对结构化数据的搜索:
如对数据库的搜索:SQL语句。再如windows的搜索:文件名,类型,修改时间。
对非结构化数据的搜索:
如windows对文件内容的搜索。Linux下得grep命令。再如Google和百度可以搜素大量内容数据。
对于非结构化的数据搜索也叫做对全文数据的搜索。要获得良好的搜索体验,全文检索技术可以达到这一点。对全文数据的搜索还可以分为两种:
1、顺序扫描:如要找内容包含某个字符串的文件,会一个文档一个文档的从头到尾的找,如 Like查找 。
2、索引扫描:把非结构化的数据中的内容提取出来一部分重新组织,让它变的有结构化,这部分我们提取出来的数据就叫做索引.
单纯的使用数据库提供的全文搜索已经不能满足站点对于搜索功能的要求,目前大数据时代想要从海量数据中获取必要数据,建立强大的全文检索系统十分必要。
2. 全文检索系统设计与实现策略
2.1. 系统的架构
这里用一张图说明:2.2. 模块设计
全文检索大体分两个过程:索引创建(Indexer)和 搜索索引(Search)。
搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
2.2.1. 信息处理
信息处理模块的核心就是索引的创建。
索引里面究竟存些什么?(Index)
索引所保存的信息一般如下:
假设我现在有100篇文档,从1到100表示。
词典: 保存的是一系列的字符串。
倒排表: 指向包含字符串的文档链表。
如何创建索引?
全文检索的索引创建过程一般有以下几步:
一些需要创建索引的文档(Documents)。
将原文档传给分词组件(Tokenizer) 。
将得到的词元(Token)传给语言处理组件(Linguistic Processor)。
将得到的词(Term)传给索引组件(Indexer)。
合并相同的词(Term)成为文档倒排(Posting List)链表
Document Frequenc :即文档频次,表示总共有多少文件包含此词(Term)
Frequency :即词频率,表示此文件中包含了几个此词(Term)
补充:创建索引是系统的核心任务,需对主题词典处理、信息消重、文档建模、文档分析和过滤以及建立倒排索引。还需要要处理停词(如一些意义不大的虚词)。
2.2.2. 查询服务
查询服务的重点是搜索索引。
如何对索引进行搜索
搜索主要分为以下几步:
第一步:用户输入查询语句.
第二步:对查询语句进行词法分析,语法分析,及语言处理
第三步:搜索索引,得到符合语法树的文档.
第四步:根据得到的文档和查询语句的相关性,对结果进行排序.
查看Google搜索:
2.3. 系统整体运作流程
2.3.1. 索引过程:(1)、有一系列被索引文件
(2)、被索引文件经过语法分析和语言处理形成一系列词(Term)。
(3)、经过索引创建形成词典和反向索引表。
(4)、通过索引存储将索引写入硬盘。
2.3.2. 搜索过程:
(a) 用户输入查询语句。
(b) 对查询语句经过语法分析和语言分析得到一系列词(Term)。
(c) 通过语法分析得到一个查询树。
(d) 通过索引存储将索引读入到内存。
(e) 利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交,差,并得到结果文档。
(f) 将搜索到的结果文档对查询的相关性进行排序。
(g) 返回查询结果给用户。
3. 实验/系统执行(Experiment)
3.1. 实验的目标
实验的搜索引擎能够正常运行,索引和检索两个阶段的工作。通过本次实验,将验证笔者设计设计思路的可行性。基于开源的搜索引擎coreseek来搭建本次实验系统。Coreseek是基于Sphinx的中文全文检索系统,良好的支持了中文分词。但是基本原理是配置方法和Sphinx类似。
Sphinx是一个基于SQL的全文检索引擎,可以结合MySQL,PostgreSQL做全文搜索,它可以提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索。
3.2. 实验步骤
(1)、准备工作(略)(2)、创建数据源(略)
(3)、安装测试coreseek(请参考我的另一篇博文)
(4)、搭建php WEB全文检索
#search.php
SetServer ( '127.0.0.1', 9312);
$cl->SetConnectTimeout ( 3 );
$cl->SetArrayResult ( true );
$cl->SetMatchMode ( SPH_MATCH_ANY);
$res = $cl->Query ( $keyword, "*" );
$info = array();
if ($res != null) {
$info['id'] = $res ['id'];
$info['total'] = $res ['total'];
$info['time'] = $res ['time'];
$idarr = array();
foreach ( $res ['matches'] as $doc ) {
$idarr[] = $doc['id'];
}
//从mysql中检索结果id
$ids = join ( ',', $idarr );
mysql_connect ( "localhost", "root", "" );
mysql_select_db ( "fulltext" );
$sql = "select * from documents where id in({$ids})";
mysql_query ( "set names utf8" );
$resdb = mysql_query ($sql);
//设置高亮属性
$opts = array(
'before_match'=>"",
'after_match'=>""
);
$htmlres = array();
while ($row = mysql_fetch_assoc($resdb)) {
$res2 = $cl->BuildExcerpts($row, "mysql",$keyword, $opts);
$id = $res2[0];
echo $title = $res2[1];
echo $content = $res2[2];
$htmlres[] = array('id'=>$id,'title'=>$title,'content'=>$content);
}
}
$_SESSION['info'] = $info;
$_SESSION['htmlres'] = $htmlres;
header("Location: index.php");其余内容请参见原文

相关文章推荐
- wget网站镜像下载
- 架构知识体系
- iOS研发中架构设计与分层,常见架构设计
- html设置自定义的网站图标和被收藏时显示的图标
- 基于Flume的美团日志收集系统(一)架构和设计
- BIND:DNS主从服务器架构和安全控制详解
- java处理高并发高负载类网站的优化方法
- Hbase原理、基本概念、基本架构
- VS2012发布网站详细步骤
- 第14章2节《MonkeyRunner源码剖析》 HierarchyViewer实现原理-HierarchyViewer架构概述 2
- 第14章2节《MonkeyRunner源码剖析》 HierarchyViewer实现原理-HierarchyViewer架构概述 1
- iOS应用架构谈part4-本地持久化方案及动态部署
- 架构师行为准则
- Clean架构
- 最近看了一位牛人介绍的LOL服务器架构,所以就写一篇博客记录一下收获
- 一些前端网站
- 理解RESTFul架构
- 秒杀系统架构分析与实战
- DRBD+Heartbeat+mysql 高可用性负载均衡
- Android的系统架构及组件