压缩感知(I) A Compressed Sense of Compressive Sensing (I)
2016-01-08 19:50
351 查看
CS,全称一般被认为是 Compressive/Compressed Sensing/Sampling,中文叫做压缩感知,于 2004 至 2006 年之间由 David Donoho、Emamnuel Candes、Terry Tao 等人提出来之后,迅速发展壮大,虽然里组成 CS 理论的基本元素往前追溯都都有很多前人的研究,但是也是在把整个东西系统地提出来了之后,才引发了后续的广泛关注,从纯理论到纯应用甚至是新硬件的构造等等各方面。而 CS 本身也是认为是信号处理领域自 Shannon/Nyquist 采样理论以来的重大突破。
因为 Shannon/Nyquist 采样理论使得我们可以用离散信号去 perfectly 重构原来的(如果是 band-limited 并且采样率足够高的话)连续信号,而离散时间信号处理借助于计算机的力量使得人们可以实现现在的各种复杂的信号处理和滤波,如果我们还在用 Analog 设备直接对 Analog 信号进行各种处理的话,这些东西估计都难以想象吧。然而有些问题里的信号并不是完全 band-limited 的,或者要求的 Nyquist 频率过高使得硬件限制等各种原因无法完成有效地采样,然后压缩感知的理论跳出来说,如果信号在某个已知的基下面是稀疏的的话,我们可以使用远低于
Nyquist 频率的代价来完成采样并完美地恢复出原始信号,与此同时,在实际应用中的各种信号,由于具有其各自的结构性,所以通常在合适的 basic 或者 dictionary 下面都会表现出稀疏性(例如自然景观图像在小波域下是稀疏的),另外,Machine Learning 还专门有一个 topic 叫做 sparse learning,其重要的一个目标就是给定一个数据集,构造一个 dictionary 使得该数据集在这个 dictionary 下具有稀疏的线性表达。所以压缩感知的提出被认为是又一次重大革命。
当然把 CS 和 Shannon/Nyquist 采样理论直接并列起来比较的话,还是有一些设定不一样的地方,比如经典的采样理论一般讨论的需要采样的信号是连续时间的,无穷维的信号,而 CS 中虽然也有扩展理论尝试处理无穷维的信号,但是主要的着眼点还是在于长度为 的有限维信号;此外,经典的采样理论中所谓的“采样”通常是指在某一固定的频率下沿着时间轴进行……“采样”,然而 CS 中的采样则是指去测量一个线性函数作用在原始信号上的值,换句话说是计算一个内积。
具体来说,CS 着眼于一个 维的向量 ,采样的过程是使用一个线性函数,也就是另一个 维向量 作用上去得到 。将 个采样线性函数按行排列成一个 的矩阵 ,于是问题就变成了已知 和 ,求 。
线性代数的知识告诉我们,如果 的话, 的秩必定小于 ,此时该线性系统有无穷多个解,如果 是其中任意一个解的话,那么所有
都是该问题的解,其中
图 1
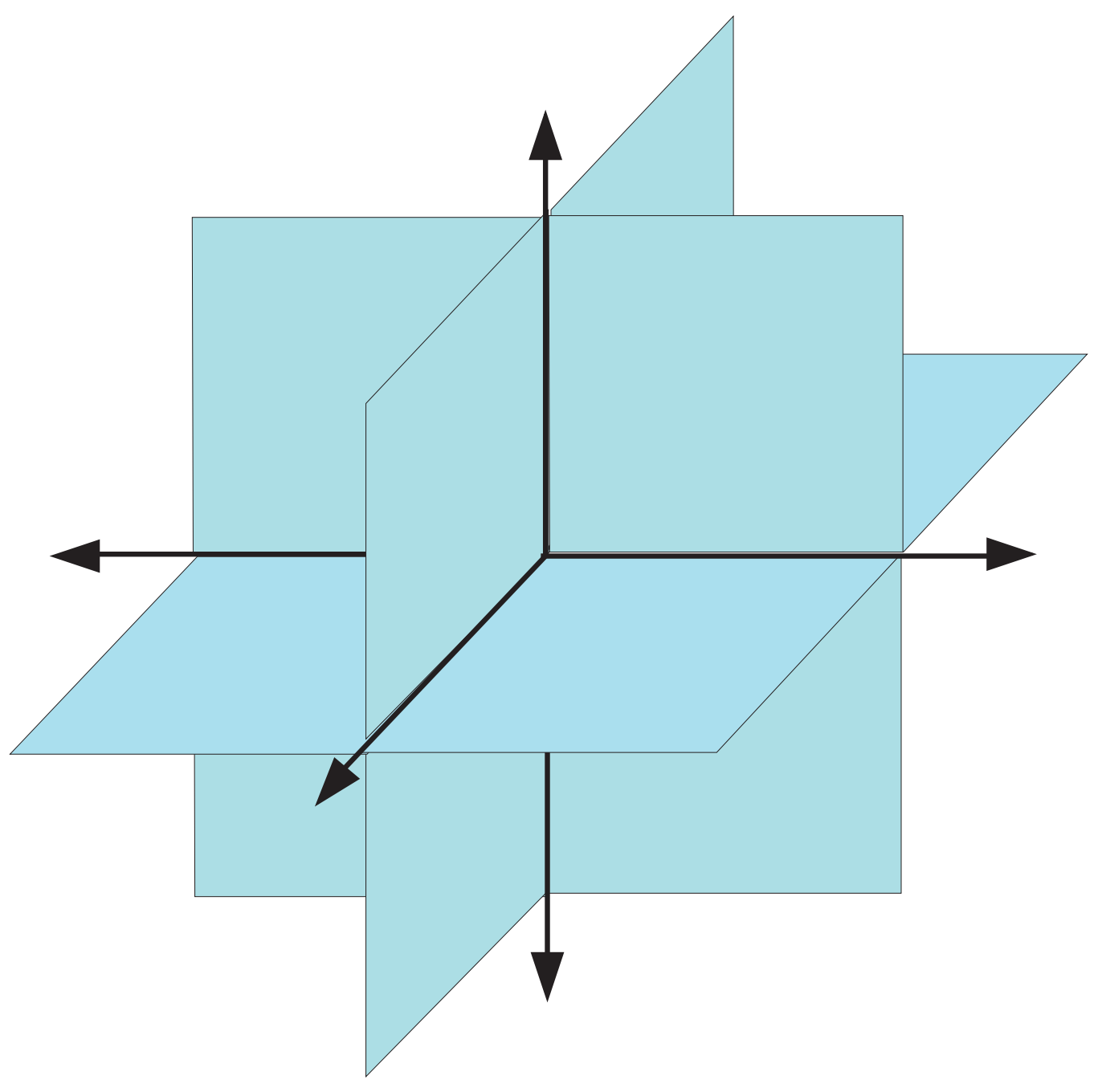
三维空间下的 2-sparse 子空间示意图。图片来自于《Compressed Sensing: Theory and Applications》。
是矩阵 的 Null Space。这代表我们采样的数量还不够 unique 地决定原始的信号。但是如果我们已知 是稀疏的,情况就不一样了。从上面的解的形式也让我们认识到 的 Null Space 的结构将会是影响该问题的重要因素。不过,再进一步之前,我们需要先定义一些符号。首先,一个向量 ,如果其中非零元素个数不超过 的话,也就是说,如果 ,那么我们称其为 -sparse
的,所有 -sparse 的向量构成一个集合,记为 ,显然 。
直观来说, 是由 个线性子空间的并构成的一个空间,它本身并不是一个线性子空间,换句话说,两个 -sparse 的和通常并不再是 -sparse 的。 下的 的示意图如图 (img:
1) 所示。
如果我们已知了 是 -sparse 的,那么的可行解的范围就缩小了,如果刚才提到的 Null Space 性质良好,就能够保证我们有唯一解。具体来说,考虑一下如果 的话,会怎样?假设 、同时是原问题的解,那么我们有
换句话说,,反过来,由于 和 都是原问题的解,它们必定各自是 -sparse 的,所以 ,但由于 和 的交集里只有零元素,因此 ,也就是说,原问题在这种情况下的解是唯一的。
为了更方便地描述这种情况,人们模仿矩阵的 rank 构造出一个叫做 spark 的量,一个矩阵 的 spark
是最小的数 使得 存在 列是线性相关的。对比一下,rank 则是最小的 使得所有 列都是线性相关的。根据定义容易看到,如果 的话,那么 的
Null Space 和 的交集必然只有零元素。
也就是说,如果我们已知原始的信号是 -sparse 的,那么用一个 spark 大于 的感知矩阵 来进行感知,就能保证所对应的原始信号是唯一的(并且这是充要条件)。不过光靠上面的分析只是证明了解唯一地存在,并没有告诉我们要如何去求得这个解,如果暴力枚举的话,将会变成一个
NP Hard 问题。所以在这里有必要简单地小结一下,CS 的基本理论中所研究的问题大概分为以下几块
需要满足什么样的性质可以保证压缩感知问题的解是唯一的;又有什么样的性质可以保证这个唯一的解是可以有效地(例如,多项式时间算法)解出来的。这里除了刚才提到的 spark 以外,还有许多诸如 Null Space Property (NSP), Restricted
Isometry Property (RIP), Coherence 之类的。
构造具体的算法去进行 Decoding,这里通常分为三类:-norm 优化算法,将原始问题进行 convex relaxation;贪心算法,迭代求解;组合优化算法,通常属于理论计算机科学所研究的范围。
如何去验证一个给定的 是否满足上面提到的要求,或者给定上面的要求如何去构造一个符合要求的 。前面提到的各种性质除了 Coherence 之外基本上都无法暴力直接验证,因为需要进行子集枚举;而满足性质的矩阵构造方面,现在已经普遍接受的是使用随机矩阵进行构造,并证明构造出来的矩阵以压倒性的概率
(Overwhelming Probability
于是再回到刚才关于 Null Space 的讨论中,虽然 Spark 的条件给出了在 时候解唯一的充要条件,但是仅考虑 -sparse 信号有时候还是过于局限,因为实际问题中有很多信号本身并不是严格的 -sparse,而仅仅是近似稀疏的,也就是是说,它们可以通过一个稀疏的向量来进行近似。具体地,我们可以定义如下的 -term
approximation error
当然,如果 本身就是 -sparse 的,那么 approximation error 就为零。此外,当 是 -norm 的时候, 的最佳 -term
近似其实就是保留绝对值最大的 个分量,将剩余的分量全部置零。图 (fig:
1)以最近的一幅合作水彩作为例子,可以看到在 Wavelet 系数域里,只要保留 5% 那么多非零系数已经可以达到相当令人眼满意的近似结果 (可以搞一种绘画形式要求作画结果中最多只能保留 wavelet 或者其他什么系数域里的多少个系数非零,之类的,哈哈。)。
图 1
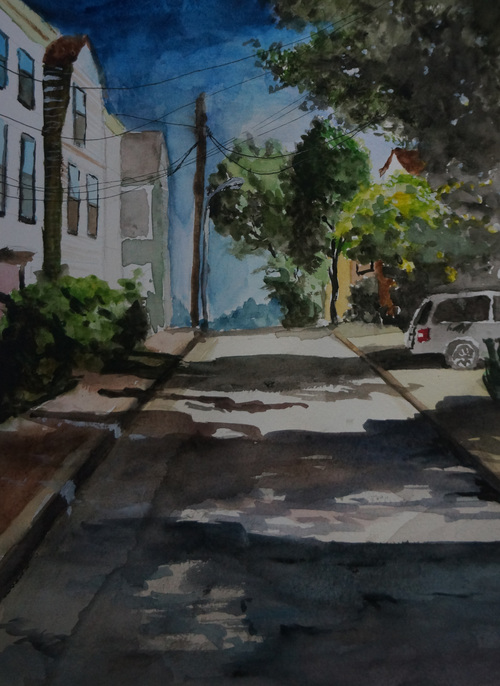
Original Image.
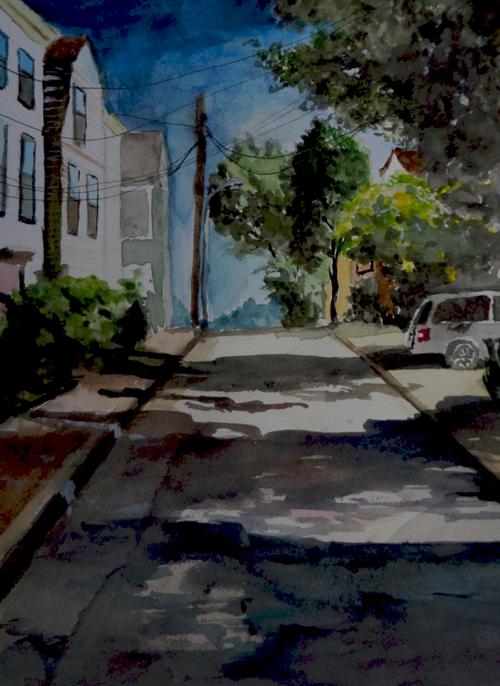
Approximation with 5-percent wavelet coefficients.

Approximation with 1-percent wavelet coefficients.
回到 CS 的问题,在 本身并不是 -sparse 的时候,我们一般不指望能够完美地恢复出 来,但是通常可以希望做到和 best -term approximation 差不多好,具体来说,我们希望能够实现
(eq: 1)
其中 表示我们的 decoding/reconstruction 算法。直观来讲,等式的右边,就类似于图 (fig:
1) 中的近似结果,这是我们在看到完整的原图之后,把所有的系数从大到小排序然后只保留前 个的结果;而左边则是只观察到了矩阵 所对应的 个 sampling 值之后进行重构的结果,我们希望的是在这样的情况下得到的结果和先观察到完整图之后再做近似的结果“差不多”。另外可以看到这个结果是把之前的情况包含进来作为特殊情况的:如果 本身就是 -sparse
的,那么显然 ,所以我们可以保证无损地恢复出原来的信号来。
和之前一样,为了能够达到 (eq:
1) 中的目标,我们从 的 Null Space 入手。之前的分析中我们要求 的 Null Space 中不要有除了 0 以外的稀疏向量,现在我们考虑的对象变成了近似稀疏的向量,于是我们类似地要求 Null Space 中不要存在 0 以外的近似稀疏的向量。具体来说,我们将要求所有 满足
(eq: 2)
这个不等式直观上来说,就是在说 的 Null Space 里的向量 不应该将值“稀疏地”集中在某 项以内。比如说, 如果是 -sparse
的话,那么式 (eq:
2) 右边将会等于零,于是左边也必须等于零,所以和之前一样,严格 -sparse 的向量只有零向量;而近似 -sparse 的向量也无法存在(注意这里的常数 是和 (eq:
1) 中对应起来的同一个常数)。
为了证明这一点,我们注意到对于任意的 ,我们可以将它分解为三个部分: ,其中 由绝对值最大的 项组成, 由剩下的绝对值最大的 项组成,而 。首先,由于 ,由 (eq:
1) 我们可以保证无损重建,也就是说 。另一方面,由于 ,我们有
因此同样地,我们有 ,由此,注意到
即证。也就是说,为了实现 (eq:
1),必要条件是 的 Null Space 里的向量满足 (eq:
2),该性质又被称为Null Space Property (NSP) (NSP 还有许多其他类似的定义,不过本质上都是差不多的。)。实际上,通过改变一下常数,我们可以证明该条件同时是充分条件。具体来说,如果
(eq: 3)
那么我们可以令 decoder 为
则,由 decoder 的定义知道, 是属于 Null Space 的,于是根据 (eq:
3),我们有
即证。其中最后一个不等式是由于我们所定义的 decoder 是对其参数的 进行最小化的缘故。当然和其他具体的 最小化等 decoder 不一样,这个 decoder 也并不确定是否有有效地算法可以去进行求解的样子。
需要注意的是,我们上面的结论其实并没有明确地要求 是怎样地“近似 -sparse”,实际上 可以完全不 sparse,上面的结论仍然不会受到影响,但是结论本身可能就没有什么用处了,因为 (eq:
1) 右边本身就很大的话,这个 bound 就没有任何意义了。不过接下来我们还要再将我们的目标扩充一下:将测量误差考虑进来。换句话说,现在我们的 sample 结果将是
其中 代表测量误差。为了讨论简单起见,我们暂时回到 -sparse 的信号,此时我们希望我们的 sensing + decoding 过程是 stable 的,具体来说,我们希望对于 ,有
为了达到这个 stable 的要求,我们必须要有,对任意的
(eq: 4)
为了证明这一必要条件,我们将 分解为 ,且 ,并定义
则
记 ,则
但是如果仅仅是 (eq:
4) 的话,我们可以仅仅通过对 进行放大而达到任意想要的 stability。当然如果真的能够放大 sensing 矩阵而不同时增大测量误差的话,这确实是有效地消除测量误差所带来的影响的有效途径,但是实际中通常对 sensing 进行这种 naive 的放大之后相应的误差也会跟着放大,所以为了回避这个 trivial 的情况,我们再对 (eq:
4) 的右边也进行一下限制。于是有了下面这个性质。
定义 1(Restricted Isometry Property (RIP)). 对于矩阵 ,如果存在常数 ,使得对任意 ,都有那么我们称 满足 阶
RIP。
这是一个比之前更强的性质,由 很容易知道,如果 满足 阶 RIP,那么显然 的 spark 是大于 的,否则就存在非零 使得
除此之外,RIP 也比 NSP 要强。具体来说,我们有如下的定理。简单起见,在接下来的讨论中,我们将 NSP 限制为 为 -norm 的情况。
定理 1. 如果 满足 阶 RIP,并且 ,那么 也满足 阶的
NSP,并且对应的常数为
令 为 中绝对值最大的 项的下标集, 为 除去 之后的绝对值最大的 项的下标集,依此类推。记 ,显然,我们有
接下来我们先证明对于 ,有
于是
(eq: 5)
在证明中我们还需有用到如下的引理。
引理 1. 若 满足 阶 RIP,令 是 的 Null Space
中的一个向量,集合 定义和刚才一样,并且 ,则
其中
引理(的更 general 的情况,不要求 属于 Null Space 时)的证明可以参见 (Eldar
& Kutyniok, 2012) 第一章中的引理 1.3。继续我们定理的证明,根据引理,我们有
整理得
当 时,我们有 ,于是可以将系数除到右边而不改变不等号方向,从而得到:
再带入相应的项即证。不过,RIP 既然是更强的条件,它自然也有自己的长处。我们刚才证明了为了能够让压缩感知在有感知误差的时候也表现的 stable,RIP 是必要条件。实际上,RIP 同时也是充分条件。
定理. 如果 满足 阶 RIP,并且 ,令 是如下凸优化问题的最优解:
其中 ,而 是感知误差的一个上界估计。则
其中
证明可以参见 (Candes,
2008) 或者 (Eldar
& Kutyniok, 2012) 第一章中整理过的定理 1.9 的证明。关于这个定理,有几点需要注意的:
这个定理将之前的情况作为特殊情况包含进来。特别地,如果测量误差 为零,那么第二项将消失掉,只留下第一项。注意到不等号左边是 -norm,由 -norm 和 -norm
之间的关系,很容易得到和我们之前 NSP 中一致的结论。
更进一步,如果 本身是 -sparse 的,此时 ,于是右边整个变成零,也就是说,此时可以保证 ,亦即完美恢复。
这个定理和之前的结果不太一样的是,给出了一个切实可行的 decoder:也就是 -norm 优化问题,当 时,该问题可以通过 Linear Programming 来求解,即使 ,也是一个定义良好的凸优化问题,具有全局最优解,可以通过各种优化算法来求解。
小结一下,如果我们保证感知矩阵 满足 阶的 RIP,那么就能通过求解 -norm 优化问题来进行 decoding。不过,在满足 RIP 的情况下,除了 -norm 优化之外还有没有其他行之有效的
CS decoding 算法呢?要满足特定的 RIP 条件的时候,对于感知样本的数目 有什么样的要求呢?具体的 应该如何构造呢?虽然在本文开始的时候已经有一些剧透了,不过由于长度限制,具体的内容还是未完待续吧!
Candes, E. J. (2008). The restricted isometry property and its implications for compressed sensing.Comptes
Rendus Mathematique, 346(9-10), 589–592.
Eldar, Y. C., & Kutyniok, G. (2012). Compressed sensing: theory and applications. Cambridge
University Press.
from: http://freemind.pluskid.org/machine-learning/a-compressed-sense-of-compressive-sensing-i/
因为 Shannon/Nyquist 采样理论使得我们可以用离散信号去 perfectly 重构原来的(如果是 band-limited 并且采样率足够高的话)连续信号,而离散时间信号处理借助于计算机的力量使得人们可以实现现在的各种复杂的信号处理和滤波,如果我们还在用 Analog 设备直接对 Analog 信号进行各种处理的话,这些东西估计都难以想象吧。然而有些问题里的信号并不是完全 band-limited 的,或者要求的 Nyquist 频率过高使得硬件限制等各种原因无法完成有效地采样,然后压缩感知的理论跳出来说,如果信号在某个已知的基下面是稀疏的的话,我们可以使用远低于
Nyquist 频率的代价来完成采样并完美地恢复出原始信号,与此同时,在实际应用中的各种信号,由于具有其各自的结构性,所以通常在合适的 basic 或者 dictionary 下面都会表现出稀疏性(例如自然景观图像在小波域下是稀疏的),另外,Machine Learning 还专门有一个 topic 叫做 sparse learning,其重要的一个目标就是给定一个数据集,构造一个 dictionary 使得该数据集在这个 dictionary 下具有稀疏的线性表达。所以压缩感知的提出被认为是又一次重大革命。
当然把 CS 和 Shannon/Nyquist 采样理论直接并列起来比较的话,还是有一些设定不一样的地方,比如经典的采样理论一般讨论的需要采样的信号是连续时间的,无穷维的信号,而 CS 中虽然也有扩展理论尝试处理无穷维的信号,但是主要的着眼点还是在于长度为 的有限维信号;此外,经典的采样理论中所谓的“采样”通常是指在某一固定的频率下沿着时间轴进行……“采样”,然而 CS 中的采样则是指去测量一个线性函数作用在原始信号上的值,换句话说是计算一个内积。
具体来说,CS 着眼于一个 维的向量 ,采样的过程是使用一个线性函数,也就是另一个 维向量 作用上去得到 。将 个采样线性函数按行排列成一个 的矩阵 ,于是问题就变成了已知 和 ,求 。
线性代数的知识告诉我们,如果 的话, 的秩必定小于 ,此时该线性系统有无穷多个解,如果 是其中任意一个解的话,那么所有
都是该问题的解,其中
图 1
三维空间下的 2-sparse 子空间示意图。图片来自于《Compressed Sensing: Theory and Applications》。
是矩阵 的 Null Space。这代表我们采样的数量还不够 unique 地决定原始的信号。但是如果我们已知 是稀疏的,情况就不一样了。从上面的解的形式也让我们认识到 的 Null Space 的结构将会是影响该问题的重要因素。不过,再进一步之前,我们需要先定义一些符号。首先,一个向量 ,如果其中非零元素个数不超过 的话,也就是说,如果 ,那么我们称其为 -sparse
的,所有 -sparse 的向量构成一个集合,记为 ,显然 。
直观来说, 是由 个线性子空间的并构成的一个空间,它本身并不是一个线性子空间,换句话说,两个 -sparse 的和通常并不再是 -sparse 的。 下的 的示意图如图 (img:
1) 所示。
如果我们已知了 是 -sparse 的,那么的可行解的范围就缩小了,如果刚才提到的 Null Space 性质良好,就能够保证我们有唯一解。具体来说,考虑一下如果 的话,会怎样?假设 、同时是原问题的解,那么我们有
换句话说,,反过来,由于 和 都是原问题的解,它们必定各自是 -sparse 的,所以 ,但由于 和 的交集里只有零元素,因此 ,也就是说,原问题在这种情况下的解是唯一的。
为了更方便地描述这种情况,人们模仿矩阵的 rank 构造出一个叫做 spark 的量,一个矩阵 的 spark
是最小的数 使得 存在 列是线性相关的。对比一下,rank 则是最小的 使得所有 列都是线性相关的。根据定义容易看到,如果 的话,那么 的
Null Space 和 的交集必然只有零元素。
也就是说,如果我们已知原始的信号是 -sparse 的,那么用一个 spark 大于 的感知矩阵 来进行感知,就能保证所对应的原始信号是唯一的(并且这是充要条件)。不过光靠上面的分析只是证明了解唯一地存在,并没有告诉我们要如何去求得这个解,如果暴力枚举的话,将会变成一个
NP Hard 问题。所以在这里有必要简单地小结一下,CS 的基本理论中所研究的问题大概分为以下几块
需要满足什么样的性质可以保证压缩感知问题的解是唯一的;又有什么样的性质可以保证这个唯一的解是可以有效地(例如,多项式时间算法)解出来的。这里除了刚才提到的 spark 以外,还有许多诸如 Null Space Property (NSP), Restricted
Isometry Property (RIP), Coherence 之类的。
构造具体的算法去进行 Decoding,这里通常分为三类:-norm 优化算法,将原始问题进行 convex relaxation;贪心算法,迭代求解;组合优化算法,通常属于理论计算机科学所研究的范围。
如何去验证一个给定的 是否满足上面提到的要求,或者给定上面的要求如何去构造一个符合要求的 。前面提到的各种性质除了 Coherence 之外基本上都无法暴力直接验证,因为需要进行子集枚举;而满足性质的矩阵构造方面,现在已经普遍接受的是使用随机矩阵进行构造,并证明构造出来的矩阵以压倒性的概率
(Overwhelming Probability
;p) 满足给定的性质。
于是再回到刚才关于 Null Space 的讨论中,虽然 Spark 的条件给出了在 时候解唯一的充要条件,但是仅考虑 -sparse 信号有时候还是过于局限,因为实际问题中有很多信号本身并不是严格的 -sparse,而仅仅是近似稀疏的,也就是是说,它们可以通过一个稀疏的向量来进行近似。具体地,我们可以定义如下的 -term
approximation error
当然,如果 本身就是 -sparse 的,那么 approximation error 就为零。此外,当 是 -norm 的时候, 的最佳 -term
近似其实就是保留绝对值最大的 个分量,将剩余的分量全部置零。图 (fig:
1)以最近的一幅合作水彩作为例子,可以看到在 Wavelet 系数域里,只要保留 5% 那么多非零系数已经可以达到相当令人眼满意的近似结果 (可以搞一种绘画形式要求作画结果中最多只能保留 wavelet 或者其他什么系数域里的多少个系数非零,之类的,哈哈。)。
图 1
Original Image.
Approximation with 5-percent wavelet coefficients.
Approximation with 1-percent wavelet coefficients.
回到 CS 的问题,在 本身并不是 -sparse 的时候,我们一般不指望能够完美地恢复出 来,但是通常可以希望做到和 best -term approximation 差不多好,具体来说,我们希望能够实现
(eq: 1)
其中 表示我们的 decoding/reconstruction 算法。直观来讲,等式的右边,就类似于图 (fig:
1) 中的近似结果,这是我们在看到完整的原图之后,把所有的系数从大到小排序然后只保留前 个的结果;而左边则是只观察到了矩阵 所对应的 个 sampling 值之后进行重构的结果,我们希望的是在这样的情况下得到的结果和先观察到完整图之后再做近似的结果“差不多”。另外可以看到这个结果是把之前的情况包含进来作为特殊情况的:如果 本身就是 -sparse
的,那么显然 ,所以我们可以保证无损地恢复出原来的信号来。
和之前一样,为了能够达到 (eq:
1) 中的目标,我们从 的 Null Space 入手。之前的分析中我们要求 的 Null Space 中不要有除了 0 以外的稀疏向量,现在我们考虑的对象变成了近似稀疏的向量,于是我们类似地要求 Null Space 中不要存在 0 以外的近似稀疏的向量。具体来说,我们将要求所有 满足
(eq: 2)
这个不等式直观上来说,就是在说 的 Null Space 里的向量 不应该将值“稀疏地”集中在某 项以内。比如说, 如果是 -sparse
的话,那么式 (eq:
2) 右边将会等于零,于是左边也必须等于零,所以和之前一样,严格 -sparse 的向量只有零向量;而近似 -sparse 的向量也无法存在(注意这里的常数 是和 (eq:
1) 中对应起来的同一个常数)。
为了证明这一点,我们注意到对于任意的 ,我们可以将它分解为三个部分: ,其中 由绝对值最大的 项组成, 由剩下的绝对值最大的 项组成,而 。首先,由于 ,由 (eq:
1) 我们可以保证无损重建,也就是说 。另一方面,由于 ,我们有
因此同样地,我们有 ,由此,注意到
即证。也就是说,为了实现 (eq:
1),必要条件是 的 Null Space 里的向量满足 (eq:
2),该性质又被称为Null Space Property (NSP) (NSP 还有许多其他类似的定义,不过本质上都是差不多的。)。实际上,通过改变一下常数,我们可以证明该条件同时是充分条件。具体来说,如果
(eq: 3)
那么我们可以令 decoder 为
则,由 decoder 的定义知道, 是属于 Null Space 的,于是根据 (eq:
3),我们有
即证。其中最后一个不等式是由于我们所定义的 decoder 是对其参数的 进行最小化的缘故。当然和其他具体的 最小化等 decoder 不一样,这个 decoder 也并不确定是否有有效地算法可以去进行求解的样子。
需要注意的是,我们上面的结论其实并没有明确地要求 是怎样地“近似 -sparse”,实际上 可以完全不 sparse,上面的结论仍然不会受到影响,但是结论本身可能就没有什么用处了,因为 (eq:
1) 右边本身就很大的话,这个 bound 就没有任何意义了。不过接下来我们还要再将我们的目标扩充一下:将测量误差考虑进来。换句话说,现在我们的 sample 结果将是
其中 代表测量误差。为了讨论简单起见,我们暂时回到 -sparse 的信号,此时我们希望我们的 sensing + decoding 过程是 stable 的,具体来说,我们希望对于 ,有
为了达到这个 stable 的要求,我们必须要有,对任意的
(eq: 4)
为了证明这一必要条件,我们将 分解为 ,且 ,并定义
则
记 ,则
但是如果仅仅是 (eq:
4) 的话,我们可以仅仅通过对 进行放大而达到任意想要的 stability。当然如果真的能够放大 sensing 矩阵而不同时增大测量误差的话,这确实是有效地消除测量误差所带来的影响的有效途径,但是实际中通常对 sensing 进行这种 naive 的放大之后相应的误差也会跟着放大,所以为了回避这个 trivial 的情况,我们再对 (eq:
4) 的右边也进行一下限制。于是有了下面这个性质。
定义 1(Restricted Isometry Property (RIP)). 对于矩阵 ,如果存在常数 ,使得对任意 ,都有那么我们称 满足 阶
RIP。
这是一个比之前更强的性质,由 很容易知道,如果 满足 阶 RIP,那么显然 的 spark 是大于 的,否则就存在非零 使得
除此之外,RIP 也比 NSP 要强。具体来说,我们有如下的定理。简单起见,在接下来的讨论中,我们将 NSP 限制为 为 -norm 的情况。
定理 1. 如果 满足 阶 RIP,并且 ,那么 也满足 阶的
NSP,并且对应的常数为
令 为 中绝对值最大的 项的下标集, 为 除去 之后的绝对值最大的 项的下标集,依此类推。记 ,显然,我们有
接下来我们先证明对于 ,有
于是
(eq: 5)
在证明中我们还需有用到如下的引理。
引理 1. 若 满足 阶 RIP,令 是 的 Null Space
中的一个向量,集合 定义和刚才一样,并且 ,则
其中
引理(的更 general 的情况,不要求 属于 Null Space 时)的证明可以参见 (Eldar
& Kutyniok, 2012) 第一章中的引理 1.3。继续我们定理的证明,根据引理,我们有
整理得
当 时,我们有 ,于是可以将系数除到右边而不改变不等号方向,从而得到:
再带入相应的项即证。不过,RIP 既然是更强的条件,它自然也有自己的长处。我们刚才证明了为了能够让压缩感知在有感知误差的时候也表现的 stable,RIP 是必要条件。实际上,RIP 同时也是充分条件。
定理. 如果 满足 阶 RIP,并且 ,令 是如下凸优化问题的最优解:
其中 ,而 是感知误差的一个上界估计。则
其中
证明可以参见 (Candes,
2008) 或者 (Eldar
& Kutyniok, 2012) 第一章中整理过的定理 1.9 的证明。关于这个定理,有几点需要注意的:
这个定理将之前的情况作为特殊情况包含进来。特别地,如果测量误差 为零,那么第二项将消失掉,只留下第一项。注意到不等号左边是 -norm,由 -norm 和 -norm
之间的关系,很容易得到和我们之前 NSP 中一致的结论。
更进一步,如果 本身是 -sparse 的,此时 ,于是右边整个变成零,也就是说,此时可以保证 ,亦即完美恢复。
这个定理和之前的结果不太一样的是,给出了一个切实可行的 decoder:也就是 -norm 优化问题,当 时,该问题可以通过 Linear Programming 来求解,即使 ,也是一个定义良好的凸优化问题,具有全局最优解,可以通过各种优化算法来求解。
小结一下,如果我们保证感知矩阵 满足 阶的 RIP,那么就能通过求解 -norm 优化问题来进行 decoding。不过,在满足 RIP 的情况下,除了 -norm 优化之外还有没有其他行之有效的
CS decoding 算法呢?要满足特定的 RIP 条件的时候,对于感知样本的数目 有什么样的要求呢?具体的 应该如何构造呢?虽然在本文开始的时候已经有一些剧透了,不过由于长度限制,具体的内容还是未完待续吧!
References
Candes, E. J. (2008). The restricted isometry property and its implications for compressed sensing.ComptesRendus Mathematique, 346(9-10), 589–592.
Eldar, Y. C., & Kutyniok, G. (2012). Compressed sensing: theory and applications. Cambridge
University Press.
from: http://freemind.pluskid.org/machine-learning/a-compressed-sense-of-compressive-sensing-i/

相关文章推荐
- 压缩感知在目标跟踪的应用
- 压缩感知在目标跟踪的应用
- 关于人脸识别,稀疏表示的若干论文的小结
- 压缩感知(Compressive Sensing)一
- 序
- 压缩感知(Compressive Sensing)
- Real-Time Compressive Tracking(CT) 札记
- 关于多元一次方程组更多的故事
- 数字图像处理:基本算法-卷积和相关
- 稀疏表达唯一解的证明
- 压缩感知(Compressive Sensing)学习之(一)
- 压缩感知(Compressive Sensing)学习之(二)
- 初识压缩感知Compressive Sensing
- 压缩感知进阶——有关稀疏矩阵
- 压缩感知学习资源
- 压缩感知重构算法——SP算法
- 压缩感知中常用的待还原信号种类
- 周志华《Machine Learning》学习笔记(13)--特征选择与稀疏学习
- 对OMP的理解
- 采样、过采样和压缩感知