算法学习笔记:排序算法整理
2015-12-20 06:21
288 查看
前言
算法真的是编程最核心的东西所以今天整理几种比较喜欢的排序算法,所有代码基于java实现。
bubble sort
原理:每一个元素都和它后面的所有元素比较,如果有必要,则交换,以此类推,直到倒数第二个元素和最后一个元素比较并交换完毕。这是最简单的排序法,虽然他的时间复杂度不是最小的,甚至可以说是比较大的。但是由于代码结构十分简单,所以实现起来十分容易,对于小规模数据的排序来说,bubble sort是很好的。
/**
* bubble sort
* best: O(n)
* worst: O(n^2)
* average: O(n^2)
*/
public static void bubbleSort() {
int tmp;
for (int i = 0; i < a.length - 1; i++) {
for (int j = 0; j < a.length - 1; j++) {
if (a[j] > a[j + 1]) {
tmp = a[j];
a[j] = a[j + 1];
a[j + 1] = tmp;
}
}
}
}insertion sort
原理:首先将整个数组看成两部分,前面是已经排序完成的数组,后面是还未排序完成的。每次从未排序的数组当中选择一个(其实就是第一个啦~~方便遍历嘛),对排序好的数组进行遍历对比,找到合适的位置并插入。插入法排序其实和冒泡法从代码上看十分相似。区别在于冒泡法是两次同向遍历,而插入法是一前一后异向遍历。
此法需要一点逆向思维,虽然不如冒泡法好记忆。但也是十分简单的一种排序法。
/**
* insertion Sort
* best: O(n)
* worst: O(n^2)
* average: O(n^2)
*/
public static void insertSort() {
int tmp;
for (int i = 1; i < a.length; i++) {
for (int k = i; k > 0; k--) {
if (a[k] < a[k - 1]) {
tmp = a[k];
a[k] = a[k - 1];
a[k - 1] = tmp;
}
}
}
}selection sort
原理:首先从全部数组中选出最小的,放在第一位,再从剩下的数组当中选出最小的,放在第二位,依此类推直到所有的数都选择完毕。选择排序可以说是最容易理解的自然方法(就是一般人在日常生活中使用的方法)了,但是在程序当中却可以说是最慢的,因为无论何种情况下,它的时间复杂度都是O(n^2)。
/**
* Selection Sort
* best: O(n^2)
* worst: O(n^2)
* average: O(n^2)
*/
public static void selectionSort() {
for (int i = 0; i < a.length; i++) {
int min = a[i];//假设当前元素就是最小数
int p = i;//记录当前元素的坐标
for (int j = i; j < a.length; j++) {//向后遍历,找到最小数,并记录坐标
if (a[j] < min) {
min = a[j];
p = j;
}
}
//将找到的最小数与当前元素交换
int tmp = a[p];
a[p] = a[i];
a[i] = tmp;
}
}merge sort
原理:归并排序,将整个数列两分,然后再将子数组两份,然后再两分,一直到不可分为止,然后再将这些子数组比较组合,直到得到完整的数组。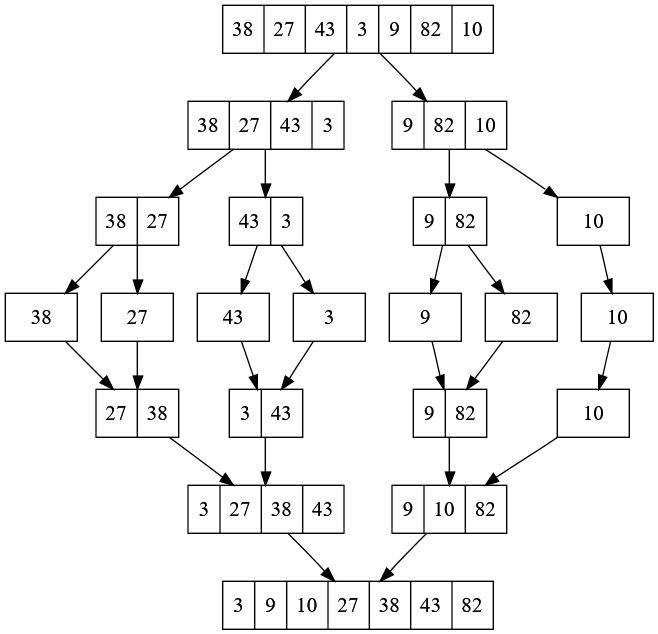
归并排序,就是所谓的Divide and Conquer,利用递归的优势,将整个数组”分而治之”,最后再整合起来。
这个方法应该是比较快的(当然还有更快的所谓bucket sort,不过呵呵。。。那种方法局限性太大了,我本身是不会用的,本文也不会讲),就是对编程的要求略高。
/**
* Merge Sort
* best: O(n*logn)
* worst: O(n*logn)
* average: O(n*logn)
*/
public static void mergeSort() {
mergeSort(0, a.length - 1);
}
private static void mergeSort(int first, int last) {
if (first < last) {
int mid = (first + last) / 2;
mergeSort(first, mid);//递归左边数组
mergeSort(mid + 1, last);//递归右边数组
merge(first, mid, last);//组合当前的数组
}
}
private static void merge(int first, int mid, int last) {
int[] tmp = new int[last - first + 1];
int ll = first;
int rl = mid + 1;
int k = 0;
//两个都不为空
while (ll <= mid && rl <= last) {
tmp[k++] = (a[ll] < a[rl]) ? a[ll++] : a[rl++];
}
//左边不空
while (ll <= mid) {
tmp[k++] = a[ll++];
}
//右边不空
while (rl <= last) {
tmp[k++] = a[rl++];
}
for (int i = 0; i < k; i++)
a[first + i] = tmp[i];
}quick sort
原理:先选定一个中心数pivot,随便选,可以是第一个,也可以是最后一个,甚至可以是中间随便一个,然后遍历整个数组,将大于pivot的数放在右边,小于pivot的数放在左边,然后再分别递归左右两边的子数组。这个算法也是采用分治的思想(Divid and Conquer),基本上采用分治思想的算法,时间复杂度都和n*logn有关,所以效率都还行~~~~
这个算法其实好理解,难点应该在代码的实现上,如果你没有记住代码的话,重新编写可能会遇到两个问题
数组的坐标要搞清楚,因为是直接在原数组上操作,一步错,步步错。
怎么样将数组分成两段也是难点,我的思路是,遍历整个数组,将所有小于pivot的数都弄到数组前半段,并记录第一个大于pivot数的坐标s。那么一旦发现有新的小数,则可以直接和位于s的那个数交换,并重新记录,这样一来,就保证被记录的坐标之间的所有数都小于pivot,最后再把pivot换到s位置。实现了数组的分段。
public static void quickSort() {
quickSort(0, a.length - 1);
}
private static synchronized void quickSort(int first, int last) {
if (first < last) {
int pivot = partition(first, last);
//这里要注意,递归的时候需要绕过已经选出来了的中心数pivot
quickSort(first, pivot - 1);
quickSort(pivot + 1, last);
}
}
private static int partition(int first, int last) {
int s = first;
int tmp;
for (int l = first; l < last; l++) {
if (a[l] < a[last]) {
tmp = a[l];
a[l] = a[s];
a[s] = tmp;
s++;
}
}
tmp = a[last];
a[last] = a[s];
a[s] = tmp;
return s;
}heap sort
原理:1. 首先将整个数组重新排列成符合最大堆(或者最小堆)结构的数。
2. 既然这个数组符合堆结构,那么它的根元素必然是最大或者最小的,这时我们可以取出这个根元素,就可以得到整个数列的最大值或者最小值了。
3. 剩下的元素再重复刚才的步骤,直到所有的元素都取出,得到排列好的数组。
heap sort放在最后面讲,其实是因为它最难以理解,无论从代码实现还是理论知识方面都是。但是它的效率又相当优秀,所以不得不学习。。。
学习heap sort(堆排序)之前,首先要理解binary tree(二叉树)的概念,然后再理解binary heap(二叉堆)。如果懒得看wiki也没有关系,简单来说,所谓的二叉堆就是下面这个样子。
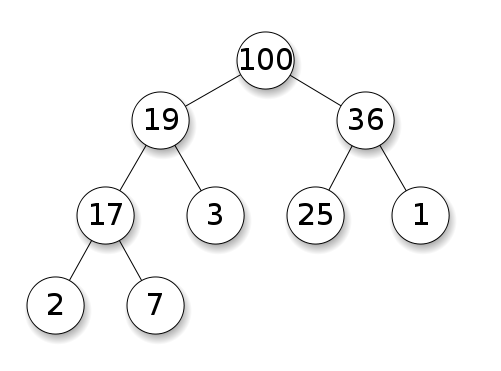
这是一个最大二叉堆,它有三个特性,我归纳如下:
每个结点最多两个子结点。
越上面越大(或者越小)。
除了最下面一层叶子,其余的结点必须长满!
理解二叉堆的概念以后,我们就可以知道,如果一个数组的排列符合二叉堆的结构,我们就可以轻易的得到它的最大值或是最小值,所谓排序,就是不断取出这些最值的过程
所以说堆排序的主要目的,其实就是把目标数组弄成二叉堆。
说起来简单,但是做起来却不容易,第一个难点,就是一般人很难将上图的二叉堆,和代码里面的数组联系起来,也就是说无法理解,这么一棵二维的树,怎么能放进一维的数组里面呢?
先说方法:

如图所示,根结点放在0位,左儿子放在1位,右儿子放在2位,以此类推,左儿子的左儿子放在3位,左儿子的右儿子放在4位。
直观点儿来讲,就是把二叉堆,从上到下,从左到右依次放入数组就行了。。。
但是这还是按照”人“的思路来操作的,那么如何在代码中实现呢?或者说,数学规律是什么呢?
总的来说,就是对于第 n 个结点,它的左儿子,放在 2n+1 位,右儿子则放在 2n+2了。
反过来讲,对于一个数组来说,无论它里面的元素如何排列,只要我们按照上面的规律来访问它,那么它就可以看成是一个二叉树
我至今还对想出这个方法的前辈表示无尽的膜拜 Orz。思路怎么来的,我就不讲了,数学证明什么的,你也不要想了。。。因为我也说不清楚,我只能拾人牙慧,直接讲解决方法了。
找到了这个规律,我们就可以把一个数组当成是binary tree(二叉树)来操作,并把它弄成binary heap(二叉堆)。
如何在代码中实现二叉树到二叉堆的转换呢?
有两种方式:从上往下,或者从下往上,本文只介绍从下往上的方式。
以最大二叉堆为例
通过二叉堆的特性我们可以看出,如果把它放入数组当中,那么最后一个元素必定是叶子,而这个叶子的根,也应该是整个二叉堆当中的最后一个拥有叶子的结点,在它之前的所有结点,都应该拥有叶子!
如果我们从这个结点开始,遍历之前所有的结点,那么我们实际上就对所有的元素进行了操作。
根据数学规律,假设最后一个元素的坐标是 n=2i+1 或 n=2i+2,那么最后一个拥有叶子的结点的坐标就是 i=n/2−1,因为无论 n=2i+1 还是 n=2i+2,程序运算
i=n/2-1;所得来的 i 都一样,因为 n/2 是向下取整的。
知道了从哪里开始,还要知道怎么做。
我们需要做的就是保证以该结点为根,它下面所有的结点所组成的二叉树,是二叉堆。
我们先找出结点所对应的两片叶子当中较大的那片,再与结点比较,如果结点比该叶子大,则表明这是二叉堆,退出操作,如果结点比该叶子小,则交换结点与叶子,交换以后,因为叶子变成了较小的数,所以它可能比它的叶子还要小。所以如果这片叶子向下还有叶子,则应该将这片叶子看成结点,循环执行上面的操作,如果这片叶子下面没有叶子,则程退出循环。
moveDown流程图:
Created with Raphaël 2.1.0开始是否有叶子? 找出最大叶子比结点大?交换结点与叶子结束yesnoyesno
moveDown函数代码:
private static void moveDown(int i, int n) {
int lc = 2 * i + 1;
while (lc < n) {
if (lc < n - 1 && a[lc] < a[lc + 1]) {
lc++;
}
if (a[i] < a[lc]) {
int tmp = a[i];
a[i] = a[lc];
a[lc] = tmp;
i = lc;
lc = 2 * i + 1;
}
else {
lc = n;
}
}
}这里需要说明的是,如果是从上往下的做法,这个函数并不适用,因为它无法完全遍历整个二叉树,故而它没办法保证整个二叉树就是二叉堆,它只能保证,有交换动作的那一个分支符合二叉堆的特性,但由于我们是从下往上操作,在所有下层的数据率先符合二叉堆的前提下,这种不完全的遍历反而大大的提高了执行效率
主函数分成两步:
从下往上遍历所有的根,完成最大堆的初始化。
将根元素和最后一个叶元素交换,此时,整个数组的最后一个元素可以确定就是最大值,而前面N-1个元素当中,除了根元素(第1个元素),其余的元素都符合二叉堆的结构,所以我们只需要再执行一次moveDown操作,让根元素融入到整个二叉堆当中,就可以了。
public static void heapSort() {
for (int i = a.length / 2 - 1; i >= 0; i--) {
moveDown(i, a.length);
}
for (int i = a.length - 1; i >= 1; i--) {
int tmp = a[i];
a[i] = a[0];
a[0] = tmp;
moveDown(0, i);
}
}最后贴出完整的代码如下:
public static void heapSort() {
for (int i = a.length / 2 - 1; i >= 0; i--) {
moveDown(i, a.length);
}
for (int i = a.length - 1; i >= 1; i--) {
int tmp = a[i];
a[i] = a[0];
a[0] = tmp;
moveDown(0, i);
}
}
private static void moveDown(int i, int n) {
int lc = 2 * i + 1;
while (lc < n) {
if (lc < n - 1 && a[lc] < a[lc + 1]) {
lc++;
}
if (a[i] < a[lc]) {
int tmp = a[i];
a[i] = a[lc];
a[lc] = tmp;
i = lc;
lc = 2 * i + 1;
}
else {
lc = n;
}
}
}关于时间复杂度的计算
计算步骤放这里方便以后复习用~~以merge sort为例:
假设数组的长度是2k,分治法会将这个数组一分为二,每段数组长度就是2k−1。
然后再将这两个数组组合起来,以上面的程序为例,组合的函数就是
private static void merge(int first, int mid, int last) {
int[] tmp = new int[last - first + 1];
int ll = first;
int rl = mid + 1;
int k = 0;
//两个都不为空
while (ll <= mid && rl <= last) {
tmp[k++] = (a[ll] < a[rl]) ? a[ll++] : a[rl++];
}
//左边不空
while (ll <= mid) {
tmp[k++] = a[ll++];
}
//右边不空
while (rl <= last) {
tmp[k++] = a[rl++];
}
for (int i = 0; i < k; i++)
a[first + i] = tmp[i];
}当中,赋值有4次,循环n次,循环中赋值1次,循环中加法2次,最后把临时数组放入原数组又用了n次。
所以merge函数一共有4n+4步。
这样一来,可以计算完成merge sort需要的运算次数:
T(n)=2T(n2)+4n+4
展开上面的式子:
T(n)=2T(n2)+4n+4=4T(n4)+2∗4n+4∗(1+2)=8T(n8)+3∗4n+4∗(1+2+4)=...
⇒T(n)=2iT(n2i)+i∗4n+4∗(20+21+22+...+2i−1)
令 :
S=20+21+22+...+2i−1
⇒2∗S=21+22+...+2i
⇒S=2∗S−S=2i−1
代入后,得到展开式:
T(n)=2iT(n2i)+i∗4n+4∗(2i−1)
令:
n=2k,i≤k,i∈N
当i=k时
⇒T(n)=2kT(1)+k∗4n+4∗(2k−1)
因为T(1)时,数组不需要操作,故T(1)=0
⇒T(n)=k∗4n+4∗(2k−1)
又因为 2k=n⇒k=logn
T(n)=4n∗logn+4∗(n−1)
最终得到时间复杂度O(n):
O(n)=n∗logn

相关文章推荐
- 【jQuery】自定义对象级插件——lifocuscolor插件
- Lesson5 一阶自治微分方程
- 【jQuery】右键菜单插件——contextmenu
- C++ list用法
- 【jQuery】搜索插件——autocomplete
- Leetcode: Number of Digit One
- A引擎走法
- 根据SVN showlog跟踪代码
- 发送邮件的方法
- Leetcode: Power of Two
- 【jQuery】cookie插件——cookie
- 特别码字3
- 【jQuery】图片放大镜插件——jqzoom
- 特别码字2
- 309. Best Time to Buy and Sell Stock with Cooldown
- 【jQuery】图片灯箱插件——lightBox
- 普法知识(43):法定职责必须为、法无授权不可为
- Android内核之FrameWork学习
- 【jQuery】表单插件——ajaxForm()方法
- spark-1.2.0 集群环境搭建