ML—线性回归系列(一)—线性回归
2015-11-25 20:53
232 查看
Andrew Zhang
Tianjin Key Laboratory of Cognitive Computing and Application
Tianjin University
Nov 25, 2015
本来以为线性回归是一个特简单的东西,最近遇到很多基于线性回归的东西,才意识到我的无知。为了记录最近的学习历程,还是从线性回归开始系统总结一下吧。
一、线性回归
在实际问题中,在考虑变量y与另外一些变量x1,x2,...,xn 之间关系的时候,为了简化往往考虑线性模型
hθ(x)=θ0+θ1x1+...+θnxn=θTx(1-1)
其中x0=1.
接下来,目标就是对于训练数据集(xi,yi),i=1,2,...,m确定模型最合适的参数θ。采用最小二乘法,定义损失函数
J(θ)=12∑mi=1(hθ(x(i))−y(i))2(1-2)
这里采用最小二乘是因为最小二乘得到的参数θ优效性最好(在所有的线性无偏估计量里面方差最小).
二、梯度下降法
最小二乘是无约束优化的凸问题,属于最简单的凸优化问题,有很多的数值求解的方法,参考参考博客[1]。本文介绍梯度下降法求解最小二乘优化问题。
在梯度法中参数θ的更新规则为:
θj=θj−αddθjJ(θ)(2-1)
其中α 为学习率,可以设定为常数,也可以采用一维搜索方法确定,具体可以查看参考博客[2]
ddθjJ(θ)
=ddθj(12∑mi=1(hθ(x(i))−y(i))2
=12∑mi=12⋅(hθ(x(i))−y(i))⋅x(i)j
=∑mi=1(hθ(x(i))−y(i))⋅x(i)j
(2-2)
公式(2-2)带入公式(2-1)得到θj的更新规则为:
θj=θj−α∑mi=1(hθ(x(i))−y(i))⋅x(i)j(2-3)
采用公式(2-3)的方法被称为批梯度下降法。由于批梯度下降法对与每一次θ的更新需要计算所有的样本,不利于在线计算,因此一般使用如下公式(2-4)所示的随机梯度下降法(理解的时候只需要每次对参数进行更新迭代的时候假设只有一个样本即可):
θj=θj−α(hθ(x(i))−y(i))⋅x(i)j(2-4)
并且往往公式(2-4)的收敛效率要远远高于(2-3),可以更早的达到收敛。
三、最小二乘的概率解释
在参考博客3中说了线性规划的最小二乘属于广义线性模型,并进行了推导,得到了
p(y|x,θ)=12π√exp(−12(y−θTx)2)(3-1)
在这里我们看一种更简单点的解释,假设输出y与输入x服从如下等式
y(i)=θTx(i)+ϵ(i)(3-2)
由于对于取样的每个样本都是独立同分布的,假设误差项ϵ(i)~N(0,σ2)
则对于每一个取样样本有
p(ϵ(i))=12π√σexp(−(ϵ(i))22σ2)(3-3)
由公式(3-2)得ϵ(i)=y(i)−θTx(i)带入公式(3-3)得到
p(y(i)|x(i);θ)=12π√σexp(−(y(i)−θTx(i))22σ2)(3-3)
公式(3-3)便是样本(x(i),y(i))的先验概率公式。接下来就是统计学里面的参数估计问题了。求解似然函数极大化似然函数即可。
似然函数为:
L(θ)=∏mi=1p(y(i)|x(i);θ)(3-4)
对数似然函数为:
l(θ)=logL(θ)=log∏mi=112π√σexp(−(y(i)−θTx(i))22σ2)(3-5)
化简公式(3-5)得
l(θ)=mlog12π√σ−12σ2∑mi=1(y(i)−θTx(i))2(3-6)
刨除公式(3-6)的常数部分,极大化似然函数(3-6)等价于极小化其中的∑mi=1(y(i)−θTx(i))2部分,即文章开头所说的最小二乘部分的J(θ)(公式(1-2))。
四、矩阵求解最小二乘
把所有的样本(x(i),y(i))用矩阵的形式表示,可以写成如下的形式
Y=Xθ+ϵ(4-1)
目标是求解θ是的ϵTϵ最小。令
S(θ)=ϵTϵ=(Y−Xθ)T(Y−Xθ)(4-2)
ddθS(θ)=2XT(Y−Xθ)=0(4-3)
即XTXθ=XTY
这里假设X=(X1,X2,...,Xn)中的列向量都是线性无关的(如果不满足就先进行一步冗余特征删除),并且m>>n,即rank(X)=n,那么rank(XTX)=rank(X)=n,即XTX可逆。
所以有最小二乘的矩阵形式解—公式(4-4)
θ=(XTX)−1XTY(4-4)
五、矩阵求解的SVD解释
在第四部分已经得到θ=(XTX)−1XTY。这一部分利用SVD知识初探线性回归几何意义(主要为岭回归铺垫)。
假设X∈Rm×n的SVD分解为
X=UΣVT(5-1)
其中U=(u1,u2,...,un)∈Rm×n,Σ=diag(σ1,σ2,...,σn)∈Rn×n,V=(v1,v2,...,vn)∈Rn×n,v1,v2,...,vn是原始样本空间的一组标准正交基,u1,u2,...,un分别是原始样本在这组基下的正交标准化坐标。
XTX=(UΣVT)TUΣVT=VΣUTUΣVT=VΣ2VT(5-2)
带入公式4-4可得
θ=(VΣ2VT)−1(UΣVT)TY=VΣ−1UTY=∑ni=11σiviuTiY(5-3)
对于公式5-2,可以发现想要得到矩阵X的SVD分解,只需要求解矩阵XTX的特征值和特征向量就能得到Σ和V,然后根据ui=Xvi即可得到矩阵U。
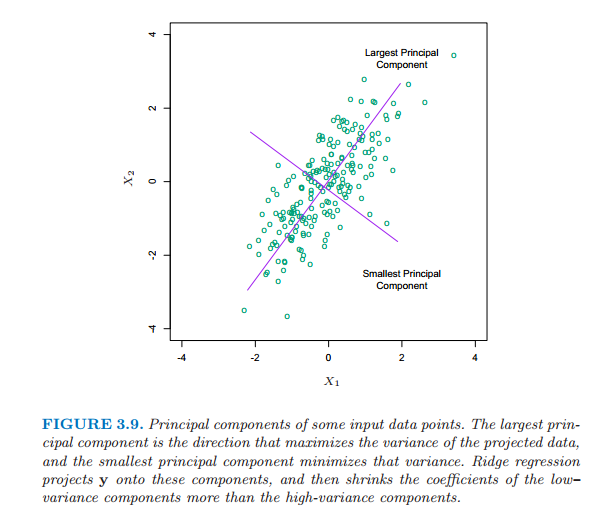
并且,根据SVD的几何意义,我们知道z=Xv1实际上是在原始空间求得新基v1使得矩阵X在新基上坐标方差Var(z1)最大。根据SVD的知识有有Var(zi)=σ2iN,Xvi=uiσi这里可见SVD实际上是广义的PCA。
六、参考博客
1、最优化方法—无约束极值问题的解法
(http://blog.csdn.net/zhangzhengyi03539/article/details/49705305)
2、最优化方法—一维搜索
(http://blog.csdn.net/zhangzhengyi03539/article/details/49704893)
3、ML—广义线性模型(GLM)
(http://blog.csdn.net/zhangzhengyi03539/article/details/46834379)
4、你应该知道的7种回归技术
Tianjin Key Laboratory of Cognitive Computing and Application
Tianjin University
Nov 25, 2015
本来以为线性回归是一个特简单的东西,最近遇到很多基于线性回归的东西,才意识到我的无知。为了记录最近的学习历程,还是从线性回归开始系统总结一下吧。
一、线性回归
在实际问题中,在考虑变量y与另外一些变量x1,x2,...,xn 之间关系的时候,为了简化往往考虑线性模型
hθ(x)=θ0+θ1x1+...+θnxn=θTx(1-1)
其中x0=1.
接下来,目标就是对于训练数据集(xi,yi),i=1,2,...,m确定模型最合适的参数θ。采用最小二乘法,定义损失函数
J(θ)=12∑mi=1(hθ(x(i))−y(i))2(1-2)
这里采用最小二乘是因为最小二乘得到的参数θ优效性最好(在所有的线性无偏估计量里面方差最小).
二、梯度下降法
最小二乘是无约束优化的凸问题,属于最简单的凸优化问题,有很多的数值求解的方法,参考参考博客[1]。本文介绍梯度下降法求解最小二乘优化问题。
在梯度法中参数θ的更新规则为:
θj=θj−αddθjJ(θ)(2-1)
其中α 为学习率,可以设定为常数,也可以采用一维搜索方法确定,具体可以查看参考博客[2]
ddθjJ(θ)
=ddθj(12∑mi=1(hθ(x(i))−y(i))2
=12∑mi=12⋅(hθ(x(i))−y(i))⋅x(i)j
=∑mi=1(hθ(x(i))−y(i))⋅x(i)j
(2-2)
公式(2-2)带入公式(2-1)得到θj的更新规则为:
θj=θj−α∑mi=1(hθ(x(i))−y(i))⋅x(i)j(2-3)
采用公式(2-3)的方法被称为批梯度下降法。由于批梯度下降法对与每一次θ的更新需要计算所有的样本,不利于在线计算,因此一般使用如下公式(2-4)所示的随机梯度下降法(理解的时候只需要每次对参数进行更新迭代的时候假设只有一个样本即可):
θj=θj−α(hθ(x(i))−y(i))⋅x(i)j(2-4)
并且往往公式(2-4)的收敛效率要远远高于(2-3),可以更早的达到收敛。
三、最小二乘的概率解释
在参考博客3中说了线性规划的最小二乘属于广义线性模型,并进行了推导,得到了
p(y|x,θ)=12π√exp(−12(y−θTx)2)(3-1)
在这里我们看一种更简单点的解释,假设输出y与输入x服从如下等式
y(i)=θTx(i)+ϵ(i)(3-2)
由于对于取样的每个样本都是独立同分布的,假设误差项ϵ(i)~N(0,σ2)
则对于每一个取样样本有
p(ϵ(i))=12π√σexp(−(ϵ(i))22σ2)(3-3)
由公式(3-2)得ϵ(i)=y(i)−θTx(i)带入公式(3-3)得到
p(y(i)|x(i);θ)=12π√σexp(−(y(i)−θTx(i))22σ2)(3-3)
公式(3-3)便是样本(x(i),y(i))的先验概率公式。接下来就是统计学里面的参数估计问题了。求解似然函数极大化似然函数即可。
似然函数为:
L(θ)=∏mi=1p(y(i)|x(i);θ)(3-4)
对数似然函数为:
l(θ)=logL(θ)=log∏mi=112π√σexp(−(y(i)−θTx(i))22σ2)(3-5)
化简公式(3-5)得
l(θ)=mlog12π√σ−12σ2∑mi=1(y(i)−θTx(i))2(3-6)
刨除公式(3-6)的常数部分,极大化似然函数(3-6)等价于极小化其中的∑mi=1(y(i)−θTx(i))2部分,即文章开头所说的最小二乘部分的J(θ)(公式(1-2))。
四、矩阵求解最小二乘
把所有的样本(x(i),y(i))用矩阵的形式表示,可以写成如下的形式
Y=Xθ+ϵ(4-1)
目标是求解θ是的ϵTϵ最小。令
S(θ)=ϵTϵ=(Y−Xθ)T(Y−Xθ)(4-2)
ddθS(θ)=2XT(Y−Xθ)=0(4-3)
即XTXθ=XTY
这里假设X=(X1,X2,...,Xn)中的列向量都是线性无关的(如果不满足就先进行一步冗余特征删除),并且m>>n,即rank(X)=n,那么rank(XTX)=rank(X)=n,即XTX可逆。
所以有最小二乘的矩阵形式解—公式(4-4)
θ=(XTX)−1XTY(4-4)
五、矩阵求解的SVD解释
在第四部分已经得到θ=(XTX)−1XTY。这一部分利用SVD知识初探线性回归几何意义(主要为岭回归铺垫)。
假设X∈Rm×n的SVD分解为
X=UΣVT(5-1)
其中U=(u1,u2,...,un)∈Rm×n,Σ=diag(σ1,σ2,...,σn)∈Rn×n,V=(v1,v2,...,vn)∈Rn×n,v1,v2,...,vn是原始样本空间的一组标准正交基,u1,u2,...,un分别是原始样本在这组基下的正交标准化坐标。
XTX=(UΣVT)TUΣVT=VΣUTUΣVT=VΣ2VT(5-2)
带入公式4-4可得
θ=(VΣ2VT)−1(UΣVT)TY=VΣ−1UTY=∑ni=11σiviuTiY(5-3)
对于公式5-2,可以发现想要得到矩阵X的SVD分解,只需要求解矩阵XTX的特征值和特征向量就能得到Σ和V,然后根据ui=Xvi即可得到矩阵U。
并且,根据SVD的几何意义,我们知道z=Xv1实际上是在原始空间求得新基v1使得矩阵X在新基上坐标方差Var(z1)最大。根据SVD的知识有有Var(zi)=σ2iN,Xvi=uiσi这里可见SVD实际上是广义的PCA。
六、参考博客
1、最优化方法—无约束极值问题的解法
(http://blog.csdn.net/zhangzhengyi03539/article/details/49705305)
2、最优化方法—一维搜索
(http://blog.csdn.net/zhangzhengyi03539/article/details/49704893)
3、ML—广义线性模型(GLM)
(http://blog.csdn.net/zhangzhengyi03539/article/details/46834379)
4、你应该知道的7种回归技术

相关文章推荐
- HTTP协议笔记
- Spine动画的使用
- MIT算法导论-第一讲-算法分析
- 机器语言
- Ubuntu12.04 Version 安装二三事
- PHP 预定义常量 $_SERVER
- Kafka+Spark Streaming+Redis实时计算整合实践
- android ListView 设置header和footer的问题
- netty5学习笔记-内存池5-PoolThreadCache
- cas 无锁操作
- 设计模式:模版模式(Template Pattern)
- UVA1511 Buy or Build 二进制枚举+最小生成树kruskal
- netty5学习笔记-内存池5-PoolThreadCache
- CC2530在IAR编辑时候8.10和8.20版本之间的兼容性问题
- VisualStudioOnline协同工作流程
- UIScrollView视差效果动画
- FreeMarker导出word,解决\n换行问题
- JSP通过IP获取用户(客户端)的地理位置信息
- CodeUI Test:UIMap录制文件分析一
- Highcharts ajax获取json对象动态生成报表生成 .