PowerVR 图形架构探索:tile-based渲染
2015-09-09 16:21
423 查看
原文链接:http://imgtec.eetrend.com/article/5282

我一直热衷于讲述我为何加入Imagination公司的故事。这个故事沿着以下路线发展:尽管我获得了图形方面的工作offer,而且是在阳光充足气候的城市,但最终我还是选择了PowerVR Graphics公司,在英国这个明显没有太多阳光的地方工作,因为我对砖墙式延迟渲染(TBDR)技术如何能在现实中应用实在是太感兴趣了。一直到现在,我的图像职业生涯大多时候聚焦在如今的概念简化的直接模式渲染器(IMRs)——大多指GeForces和Radeons显卡。
无意冒犯那群设计GeForces和Radeons显卡的家伙——他们中的一些人也是我的朋友,我也很了解这群人,但是现代分离式IMR 图形处理器上的前端架构并不是世界上最激动人心的事情。这些GPU中包含大量的专用带宽设计,以一种效率低下的方式进行像素描绘工作,但确实是一种概念简单并且能在芯片中简单表现出来的方式,从而使得GPU架构相对容易地进行设计、规范,并且已经被硬件团队构建出来了。
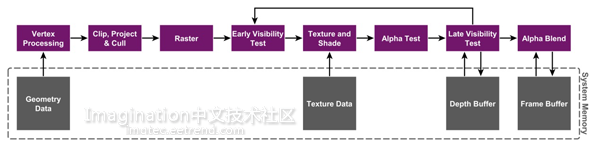
直接模式渲染器运行机制
在IMR下,你把任务交给GPU,然后就直接进行绘画了。这其中已经画了的部分,或者将要画的部分之间没有任何关联。传送三角形,然后着色。接着将它们光栅化至像素中,给这些像素着色。将这些渲染了的像素传送至屏幕上。三角形输入、像素输出、绘图任务完成!但关键是在已发生的事情、或将要发生的事情之间没有任何前后关系的情况下,任务就完成了。
在这个方面,PowerVR GPU就很不一样,这也是如今我为什么在这里工作的原因:为了探索PowerVR的架构、硬件团队和软件工程师是如何让TBDR在实际产品中发挥作用。我的直觉是TBDR将很难构建,这样它们才会运行良好从而实际提供益处。我曾获得一个机会来一探究竟,5年之后我依然在这里,协助探索将来我们会怎么发展它,以及研究GPU微体系结构的剩余部分。
在图形编程人员看来,PowerVR依旧看起来像三角形输入、像素输出、绘图任务完成这个模式。但在面罩之下,一些激动人心的事情正在发生。这个激动人心的部分让我坐在如今这个位置上,并且5年之后写述它,除此之外,关键还因为另一个E开头的单词:效率(efficient)!
总是由经典的TBDR vs.IMR辩论开始
为了帮助理解原因,让我们继续讨论IMR。阻止桌面类IMR继续缩小以适应现代嵌入式应用处理器的功耗、性能和尺寸预算需求的因素之一是带宽。这是一个非常稀缺的资源,甚至是在高端处理器上也一样——通常受限于功耗、尺寸、布线和封装等其它因素,以至于你必须尽可能高效率的使用带宽。IMR并没有很好地做到这一点,特别是在像素着色方面。要记住不止是对于构成三角形的顶点,通常总会有大量额外的像素点也被渲染了。最重要的是,在IMR中,尽管有些像素从来没有在屏幕上显示,但经常还是被着色了,因而耗费了大量珍贵的带宽和功率。下面是原因。
那些像素点的纹理需要被采样,并且这些像素点需要写到内存中去——也经常读回来再写回去!——在屏幕上进行绘制之前。尽管所有的现代IMR在硬件上有方法能尝试避免一些多余的工作,比如说创建在背景上的被画在旁边的彻底掩盖,应用开发者可以做更多的事情来高效的禁止那些机制,例如总是优先绘制创建在背景上的内容。
在我们的架构下,应用开发者在屏幕上画什么并不重要。对于透明的几何物体除外,此时开发者仍然需要管理,但除此之外,我们提交顺序是无关的。这种能力我们已经在硬件中实现了,因为之前我们是IP公司,并且现在还在制造我们自家的PC和游戏图形处理器。你可以先画背景上的内容,接着是顶层前景上的内容,我们从不会对背景内容进行像素着色,不像IMR那样。
为了找出最顶层的三角形,我们高效地在GPU中对不透明的几何对象进行分类,不管应用在何时以及怎样提交这些对象。当然,如果一个开发者很好的归类几何对象,那么IMR也能很接近我们的效率,但毕竟只是少数情况。
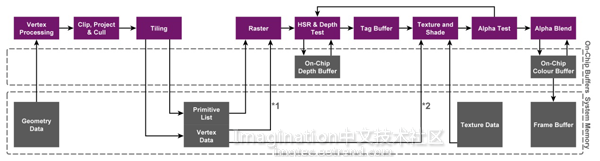
PowerVR TBDR原理
再想想所有能省去的工作,特别是对于现代内容:对于每一个像素着色,将进行不凡数量级的纹理搜寻来找出不同的东西,为了达到正确的效果,几十甚至上百个算逻单元周期会消耗在纹理数据的运行计算上,这常常意味着把像素写到中间表面上去必须得在将来的渲染传递中又将其读回来,然后接着在着色结束后,需要将像素存储在内存中,这样它才能显示在屏幕上。
而这仅仅是我们的优化之一。因此尽管我们已经避免了处理完全封闭的几何,在像素处理阶段,仍然存在着可以完成的带宽节省工作。因为我们把屏幕分成了tile,我们找出所有能放在一个tile中去的几何对象,使得我们只需处理我们需要处理的,并且我们精确的知道tile有多大(目前是32×32像素,但是在之前设计中更小并且不是方形),我们可以创建足够大的片上存储空间来同时处理那些几个tile,当我们完成着色并想把最终像素输出的时候,就不再需要使用外部存储空间了。

PowerVR GPU把屏幕分成tile
同时处理屏幕和区域有第二个好处;这是个其它GPU也利用到的好处:因为这很类似于屏幕上的像素点会和它邻域的像素点共享一些信息,这有点像当我们要转到相邻像素点上进行处理时,我们已经把数据送到cache里去,而不需要等待另一组外部存储器读取,又一次的节省了带宽。这是一个经典的空间布局利用,许多现代3D渲染中用到这个。
以上就是在处理和(特别是)带宽效率上TBDR比起IMR在顶层视图上的最大好处。但这在硬件上具体是怎么实现的呢?如果你不是偏硬件方面的,那你可以就此止步。即使没有看到下面的内容,你仍然已经理解了在嵌入式低功耗系统上我们最大化利用珍贵的可用带宽所带来的顶层上的巨大好处。
TBDR在硬件中的工作原理
对于那些对硬件里的东西感兴趣的人,让我们一起谈谈现代Rogue
GPU中上下文里的tiler。
一款3D图形应用开始于告诉我们几何对象在内存中的位置,接着我们让GPU去取出几何对象,然后进行顶点着色。在我们的GPU中,存在着负责处理每一种任务类型的非可编程步骤的模块,并称之为data master。它们代替通用着色集群或者USC(我们的着色核)做了一堆不同的事情来充当任何工作负载的定点功能位,包括从内存中取出数据。由于我们是顶点着色,因此此时是vertex data master(VDM)根据驱动提供的信息来从内存中取出顶点数据。

PowerVR 7XT系列是Rogue GPU中的最新家族
数据在内存中能够以线、三角形、点的形式存储,分为可索引和不可索引。有相关的着色程序和这些程序伴随的数据。VDM取出所有需要的东西,此时需要用到另一组内部可编程模块来帮忙,然后把它们全部送到USC进行顶点着色。USC运行着色程序,输出的顶点存储在片上。
接着它们被执行原始组装的硬件利用,对特定种类的几何对象进行剔除,然后进行剪切。如果这个几何对象是背对着的,或者被判定为完全可以从屏幕上去掉,那么它就被剔除了。屏幕上所有剩下的正对着的几何对象被送去剪切。对于不与剪切平面相交的几何对象,有一个快捷的路径可以使它进行向前的步骤,而没有多余的处理来阻挡相交测试。对于与剪切平面相交的几何对象,剪切器产生出新的几何对象,并确保传递的顶点在屏幕上(尽管它们可能在右边缘)。剪切器能干一些很酷的事情,但是要在大型图像中要进行这样的解释,剪切器则表现得不太好。
接着对比IMR,我们就到了一些奇迹发生的地方。我们在硬件上进行多阶段的计算,使效率和准确度最大化:先是一个前端阶段来跟踪着色的几何对象然后把它装进tile中,接着下一个阶段中使用装好的数据,将其光栅化然后传去像素着色,最终将其写出。为了确保事情尽可能的高效进行,两个主要阶段之间的中间加速结构必须是最佳的。
显然创建及把它读回来带来的是带宽消耗,这也是在进行比对时,我们的竞争者认为胜过我们的地方。诚然这是对的;IMR不需要处理它。但是考虑到我们处理模型中的带宽节省,建立那个加速结构——我们称之为参数缓冲器(PB)——在光栅处理之前,最终在典型的渲染情景下,特别是一些复杂游戏类的情景,我们有巨大的带宽优势。
那么我们怎么产生PB?剪切器把原始数据流和渲染目标ID输出送到内存当中,这个由渲染目标分组。可以把它当做收集相关几何对象的容器。这里面的关系很严格:我们稍后既不想读取它,也不想消耗里面的大部分数据,因为这样很浪费。存储在PB中的主要数据结构是这个阶段的输出。接着我们压缩内存,通常情况下压缩地很好,因而相比单独的步骤,我们节省了很多的PB创建带宽。
tiling的概念
那么就现在到了我们硬件架构上,并且可以说是大多数人都理解的点了:tiling。tiling引擎有一个主要的任务:输出一些标记的tile区域数据、一些相关的状态、指向构成那个区域的几何对象的指针。我们也存储遮罩以防原始的几何对象虽没有构成区域,但还是存储在内存当中了。这让我们节省了一些带宽,也减少了对那个几何对象的处理,因为这个几何对象并不是tile的构成之一。
我们把结果数据结构称为原始序列。如果你曾经购买了我们的开发者文档,你会看到在其中曾提到将原始序列称之为前端阶段和像素处理阶段间的中间数据结构。接下来是更神奇的PowerVR处理方式。
设想你正在负责构建这个点上的架构任务,对于一个给定的几何对象集,此时你需要决定什么区域需要被光栅化。这里你有一个明显可以选择的算法:边界框。在三角形周围画上一个覆盖它边界的框,与那个框相接触的tile即是你要为那个三角形进行光栅化的对象。这种方法很快,效率很高。
设想要把一个方向任意并且相对长窄的三角形画在屏幕上。你可以迅速想象到那个三角形的边界框将要跨过一些实际上这个三角形并没有接触的tile。因而当你进行光栅化的时候,你将给你的着色核增加一些工作量,而实际上这并有没给屏幕上的显示带来任何贡献。
取而代之,我们有一个回归到硬件上的算法,称为perfect tiling。它运作起来就好像你希望我们只生成tile中的几何对象确实覆盖了一些区域的tile列表。这是这个设计中最佳也是效率最高的地方之一。对于一个给定的几何对象集,这个完美的tiling引擎生成完美的tile列表。
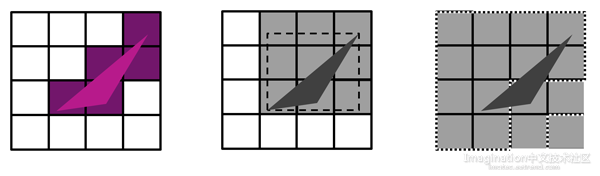
PowerVR 完美tiling vs.边界框(或者分层tiling)
tile信息连同原始tile列表被尽可能高效的打包至参数缓冲器PB中,概念上很接近它了。现实当中,在tiling的后端阶段,硬件里总有一些见鬼的事情发生,填装PB,然后为外部内存写入进行管理和引导实际内存访问,但在功能性方面仔细想想,我们还是做得很好。
对比我们的竞争者,我们前端的硬件架构确实是现代PowerVR GPU中效率能大块增长的地方。令那些知道真相的人惊讶的是,它是硬件架构上的一部分,我们的硬件架构也没有特别不一样,至少在顶层与Rogue和SGX比起来。尽管我们彻底重新设计Rogue的着色核,前端架构将和你在后代SGX
GPU IP核里看到的很类似。它起作用了,并且效果很好。那么现在我就完成了TBDR中tiling部分的讲解任务,这是个停下来的好借口。在将来的博客中,我会来讲述延迟渲染部分,因此请您继续关注。
原文链接:
http://blog.imgtec.com/powervr/a-look-at-the-powervr-graphics-architectu...
我一直热衷于讲述我为何加入Imagination公司的故事。这个故事沿着以下路线发展:尽管我获得了图形方面的工作offer,而且是在阳光充足气候的城市,但最终我还是选择了PowerVR Graphics公司,在英国这个明显没有太多阳光的地方工作,因为我对砖墙式延迟渲染(TBDR)技术如何能在现实中应用实在是太感兴趣了。一直到现在,我的图像职业生涯大多时候聚焦在如今的概念简化的直接模式渲染器(IMRs)——大多指GeForces和Radeons显卡。
无意冒犯那群设计GeForces和Radeons显卡的家伙——他们中的一些人也是我的朋友,我也很了解这群人,但是现代分离式IMR 图形处理器上的前端架构并不是世界上最激动人心的事情。这些GPU中包含大量的专用带宽设计,以一种效率低下的方式进行像素描绘工作,但确实是一种概念简单并且能在芯片中简单表现出来的方式,从而使得GPU架构相对容易地进行设计、规范,并且已经被硬件团队构建出来了。
直接模式渲染器运行机制
在IMR下,你把任务交给GPU,然后就直接进行绘画了。这其中已经画了的部分,或者将要画的部分之间没有任何关联。传送三角形,然后着色。接着将它们光栅化至像素中,给这些像素着色。将这些渲染了的像素传送至屏幕上。三角形输入、像素输出、绘图任务完成!但关键是在已发生的事情、或将要发生的事情之间没有任何前后关系的情况下,任务就完成了。
在这个方面,PowerVR GPU就很不一样,这也是如今我为什么在这里工作的原因:为了探索PowerVR的架构、硬件团队和软件工程师是如何让TBDR在实际产品中发挥作用。我的直觉是TBDR将很难构建,这样它们才会运行良好从而实际提供益处。我曾获得一个机会来一探究竟,5年之后我依然在这里,协助探索将来我们会怎么发展它,以及研究GPU微体系结构的剩余部分。
在图形编程人员看来,PowerVR依旧看起来像三角形输入、像素输出、绘图任务完成这个模式。但在面罩之下,一些激动人心的事情正在发生。这个激动人心的部分让我坐在如今这个位置上,并且5年之后写述它,除此之外,关键还因为另一个E开头的单词:效率(efficient)!
总是由经典的TBDR vs.IMR辩论开始
为了帮助理解原因,让我们继续讨论IMR。阻止桌面类IMR继续缩小以适应现代嵌入式应用处理器的功耗、性能和尺寸预算需求的因素之一是带宽。这是一个非常稀缺的资源,甚至是在高端处理器上也一样——通常受限于功耗、尺寸、布线和封装等其它因素,以至于你必须尽可能高效率的使用带宽。IMR并没有很好地做到这一点,特别是在像素着色方面。要记住不止是对于构成三角形的顶点,通常总会有大量额外的像素点也被渲染了。最重要的是,在IMR中,尽管有些像素从来没有在屏幕上显示,但经常还是被着色了,因而耗费了大量珍贵的带宽和功率。下面是原因。
那些像素点的纹理需要被采样,并且这些像素点需要写到内存中去——也经常读回来再写回去!——在屏幕上进行绘制之前。尽管所有的现代IMR在硬件上有方法能尝试避免一些多余的工作,比如说创建在背景上的被画在旁边的彻底掩盖,应用开发者可以做更多的事情来高效的禁止那些机制,例如总是优先绘制创建在背景上的内容。
在我们的架构下,应用开发者在屏幕上画什么并不重要。对于透明的几何物体除外,此时开发者仍然需要管理,但除此之外,我们提交顺序是无关的。这种能力我们已经在硬件中实现了,因为之前我们是IP公司,并且现在还在制造我们自家的PC和游戏图形处理器。你可以先画背景上的内容,接着是顶层前景上的内容,我们从不会对背景内容进行像素着色,不像IMR那样。
为了找出最顶层的三角形,我们高效地在GPU中对不透明的几何对象进行分类,不管应用在何时以及怎样提交这些对象。当然,如果一个开发者很好的归类几何对象,那么IMR也能很接近我们的效率,但毕竟只是少数情况。
PowerVR TBDR原理
再想想所有能省去的工作,特别是对于现代内容:对于每一个像素着色,将进行不凡数量级的纹理搜寻来找出不同的东西,为了达到正确的效果,几十甚至上百个算逻单元周期会消耗在纹理数据的运行计算上,这常常意味着把像素写到中间表面上去必须得在将来的渲染传递中又将其读回来,然后接着在着色结束后,需要将像素存储在内存中,这样它才能显示在屏幕上。
而这仅仅是我们的优化之一。因此尽管我们已经避免了处理完全封闭的几何,在像素处理阶段,仍然存在着可以完成的带宽节省工作。因为我们把屏幕分成了tile,我们找出所有能放在一个tile中去的几何对象,使得我们只需处理我们需要处理的,并且我们精确的知道tile有多大(目前是32×32像素,但是在之前设计中更小并且不是方形),我们可以创建足够大的片上存储空间来同时处理那些几个tile,当我们完成着色并想把最终像素输出的时候,就不再需要使用外部存储空间了。
PowerVR GPU把屏幕分成tile
同时处理屏幕和区域有第二个好处;这是个其它GPU也利用到的好处:因为这很类似于屏幕上的像素点会和它邻域的像素点共享一些信息,这有点像当我们要转到相邻像素点上进行处理时,我们已经把数据送到cache里去,而不需要等待另一组外部存储器读取,又一次的节省了带宽。这是一个经典的空间布局利用,许多现代3D渲染中用到这个。
以上就是在处理和(特别是)带宽效率上TBDR比起IMR在顶层视图上的最大好处。但这在硬件上具体是怎么实现的呢?如果你不是偏硬件方面的,那你可以就此止步。即使没有看到下面的内容,你仍然已经理解了在嵌入式低功耗系统上我们最大化利用珍贵的可用带宽所带来的顶层上的巨大好处。
TBDR在硬件中的工作原理
对于那些对硬件里的东西感兴趣的人,让我们一起谈谈现代Rogue
GPU中上下文里的tiler。
一款3D图形应用开始于告诉我们几何对象在内存中的位置,接着我们让GPU去取出几何对象,然后进行顶点着色。在我们的GPU中,存在着负责处理每一种任务类型的非可编程步骤的模块,并称之为data master。它们代替通用着色集群或者USC(我们的着色核)做了一堆不同的事情来充当任何工作负载的定点功能位,包括从内存中取出数据。由于我们是顶点着色,因此此时是vertex data master(VDM)根据驱动提供的信息来从内存中取出顶点数据。
PowerVR 7XT系列是Rogue GPU中的最新家族
数据在内存中能够以线、三角形、点的形式存储,分为可索引和不可索引。有相关的着色程序和这些程序伴随的数据。VDM取出所有需要的东西,此时需要用到另一组内部可编程模块来帮忙,然后把它们全部送到USC进行顶点着色。USC运行着色程序,输出的顶点存储在片上。
接着它们被执行原始组装的硬件利用,对特定种类的几何对象进行剔除,然后进行剪切。如果这个几何对象是背对着的,或者被判定为完全可以从屏幕上去掉,那么它就被剔除了。屏幕上所有剩下的正对着的几何对象被送去剪切。对于不与剪切平面相交的几何对象,有一个快捷的路径可以使它进行向前的步骤,而没有多余的处理来阻挡相交测试。对于与剪切平面相交的几何对象,剪切器产生出新的几何对象,并确保传递的顶点在屏幕上(尽管它们可能在右边缘)。剪切器能干一些很酷的事情,但是要在大型图像中要进行这样的解释,剪切器则表现得不太好。
接着对比IMR,我们就到了一些奇迹发生的地方。我们在硬件上进行多阶段的计算,使效率和准确度最大化:先是一个前端阶段来跟踪着色的几何对象然后把它装进tile中,接着下一个阶段中使用装好的数据,将其光栅化然后传去像素着色,最终将其写出。为了确保事情尽可能的高效进行,两个主要阶段之间的中间加速结构必须是最佳的。
显然创建及把它读回来带来的是带宽消耗,这也是在进行比对时,我们的竞争者认为胜过我们的地方。诚然这是对的;IMR不需要处理它。但是考虑到我们处理模型中的带宽节省,建立那个加速结构——我们称之为参数缓冲器(PB)——在光栅处理之前,最终在典型的渲染情景下,特别是一些复杂游戏类的情景,我们有巨大的带宽优势。
那么我们怎么产生PB?剪切器把原始数据流和渲染目标ID输出送到内存当中,这个由渲染目标分组。可以把它当做收集相关几何对象的容器。这里面的关系很严格:我们稍后既不想读取它,也不想消耗里面的大部分数据,因为这样很浪费。存储在PB中的主要数据结构是这个阶段的输出。接着我们压缩内存,通常情况下压缩地很好,因而相比单独的步骤,我们节省了很多的PB创建带宽。
tiling的概念
那么就现在到了我们硬件架构上,并且可以说是大多数人都理解的点了:tiling。tiling引擎有一个主要的任务:输出一些标记的tile区域数据、一些相关的状态、指向构成那个区域的几何对象的指针。我们也存储遮罩以防原始的几何对象虽没有构成区域,但还是存储在内存当中了。这让我们节省了一些带宽,也减少了对那个几何对象的处理,因为这个几何对象并不是tile的构成之一。
我们把结果数据结构称为原始序列。如果你曾经购买了我们的开发者文档,你会看到在其中曾提到将原始序列称之为前端阶段和像素处理阶段间的中间数据结构。接下来是更神奇的PowerVR处理方式。
设想你正在负责构建这个点上的架构任务,对于一个给定的几何对象集,此时你需要决定什么区域需要被光栅化。这里你有一个明显可以选择的算法:边界框。在三角形周围画上一个覆盖它边界的框,与那个框相接触的tile即是你要为那个三角形进行光栅化的对象。这种方法很快,效率很高。
设想要把一个方向任意并且相对长窄的三角形画在屏幕上。你可以迅速想象到那个三角形的边界框将要跨过一些实际上这个三角形并没有接触的tile。因而当你进行光栅化的时候,你将给你的着色核增加一些工作量,而实际上这并有没给屏幕上的显示带来任何贡献。
取而代之,我们有一个回归到硬件上的算法,称为perfect tiling。它运作起来就好像你希望我们只生成tile中的几何对象确实覆盖了一些区域的tile列表。这是这个设计中最佳也是效率最高的地方之一。对于一个给定的几何对象集,这个完美的tiling引擎生成完美的tile列表。
PowerVR 完美tiling vs.边界框(或者分层tiling)
tile信息连同原始tile列表被尽可能高效的打包至参数缓冲器PB中,概念上很接近它了。现实当中,在tiling的后端阶段,硬件里总有一些见鬼的事情发生,填装PB,然后为外部内存写入进行管理和引导实际内存访问,但在功能性方面仔细想想,我们还是做得很好。
对比我们的竞争者,我们前端的硬件架构确实是现代PowerVR GPU中效率能大块增长的地方。令那些知道真相的人惊讶的是,它是硬件架构上的一部分,我们的硬件架构也没有特别不一样,至少在顶层与Rogue和SGX比起来。尽管我们彻底重新设计Rogue的着色核,前端架构将和你在后代SGX
GPU IP核里看到的很类似。它起作用了,并且效果很好。那么现在我就完成了TBDR中tiling部分的讲解任务,这是个停下来的好借口。在将来的博客中,我会来讲述延迟渲染部分,因此请您继续关注。
原文链接:
http://blog.imgtec.com/powervr/a-look-at-the-powervr-graphics-architectu...

相关文章推荐
- Android架构之从startActivity追踪分析Android系统架构
- 2015年史上最全的SEO网站优化方案流程
- 系统架构搭建
- 高可用Heartbeat安装配置
- Storm系列(五)架构分析之Nimbus启动过程
- 软件编程网站收集
- Spark入门实战系列--4.Spark运行架构
- 大型集团网站建设和程序部署
- 理财平台架构分析
- iOS架构分析
- 纯CSS实现家谱树(组织架构树同理)
- 从管理国家领悟大厅类游戏架构。
- 分布式架构模型
- 本地局域网用wordpress搭建个人网站
- 网站SEO方面经常使用的技巧有哪些
- Android基本架构
- Android基本架构
- IIS网站日记分析
- Lvs+Keepalived+MySQL Cluster架设高可用负载均衡Mysql集群
- Kafka设计剖析(一):Kafka背景及架构介绍