黑马程序员-Java基础:集合(Collection)
2015-09-05 21:19
776 查看
------Java培训、Android培训、iOS培训、.Net培训、期待与您交流! -------
Collection集合总结
一、集合概述
集合的由来:
我们学习的语言是面向对象的语言,而面向对象的语言对事物的描述都是通过对象进行体现,那么为了方便的操作多个对象 我们应该将
这多个对象存储起来.那么既然要存储多个对象,我们就需要找一个容器类型的变量来存储.那么在我们之前的学习过程中那些都是容器
类型的变量呢?数组 , 字符串缓冲区 . 那么我们都知道数组不能满足我们变化的需求,而字符串缓冲区,返回是一个字符串,而我们的对象
不一定都是字符串.很显然这两个容器都不能满足我们的需求,那么java就给我们提供了一个比较帅气的东西,这个东西就是集合.
1、集合和数组的区别
a: 长度的区别
数组的长度是不能改变的,而集合的长度是可以改变的
b: 存储数据的类型的区别
数组可以存储基本数据类型,也可以存储引用数据类型 , 而集合只能存储引用数据类型
c: 内容的区别
数组只能存储同一种数据类型的元素 , 而集合可以存储多种数据类型的元素
2、集合中的方法
public boolean add(E e) :把指定的对象 添加到集合
public boolean addAll(Collection c) :把指定的集合添加到当前集合中
public void clear() :清除集合中的元素
public boolean remove(Object o) :从当前集合中,删除指定的元素
public boolean removeAll(Collection c) :从当前集合中,删除指定集合中的元素
public boolean contains(Object o) :判断当前集合中,是否包含指定的对象
public boolean containsAll(Collection c) :判断当前集合中,是否包含指定集合中的对象
public boolean isEmpty() :判断集合是否为空
public Iterator<E> iterator() :用来遍历集合(迭代器)
public boolean retainAll(Collection<?> c) :获取两个集合中相同的元素
public int size() :获取集合中元素的个数
public Object[] toArray() :把集合转换成数组
迭代器就是对容器中的元素进行遍历,每次取出一个元素,然后对元素进行操作。
3、ArrayList集合
ArrayList: 底层的数据结构是数组, 查询快 , 增删慢 , 线程不安全 , 效率高
ArrayList的遍历:
4、Vector集合
Vector底层的数据结构是数组 , 查询快 , 增删慢, 并且线程是安全的, 效率低
特有的功能:
public void addElement(E obj):
添加元素
public E elementAt(int index): 获取指定索引处对应的元素
public Enumeration elements(): 是遍历Vector集合的一种方式,使用类似于迭代器
5、LinkedList集合
LinkedList : 底层的数据结构是链表, 查询慢 , 增删块 , 线程是不安全的 , 效率高
特有的功能:
public void addFirst(E e): 在第一个位置添加元素
public void addLast(E e): 在最后一个位置添加元素
public E getFirst(): 获取第一个元素
public E getLast(): 获取最后一个元素
public E removeFirst(): 移除第一个元素,返回的是被移除的元素
public E removeLast(): 移除最后一个元素,返回的是被移除的元素
6、ArrayList、Vector、LinkedList的特点和区别
ArrayList:
底层数组结构;线程不同步,效率高;元素查找快、增删慢;
Vector:
底层数组结构;线程同步,安全;元素查找快、增删慢;
LinkedList:
底层链表结构,线程不同步,效率高;元素增删快、查找慢
7、泛型
概念:是一种把类型的明确推迟到了创建对象或者调用方法的时候的一种特殊类型. 参数化类型 , 可以把这个类型作为参数传递。
格式:
<数据类型>
数据类型: 只能是引用数据类型
泛型的好处:
a: 把运行期的错误提前到了编译期
b: 省去向下转型
c: 去除了黄色警告线
泛型的注意事项:
泛型只针对编译期有效,到了运行期就会把泛型去掉,其实就是泛型擦除 .
泛型的应用:
泛型类:
把泛型定义在类上
格式: public class 类名<数据类型 , ... >{}
泛型方法:把泛型定义在方法上
格式: public <数据类型> 返回值类型 方法名(数据类型 变量名) {}
泛型接口: 把泛型定义在接口上
格式: public interface 接口名<数据类型> {}
泛型接口的子类:
a: 在定义子类的时候已经可以明确数据类型类
public class InterImpl implements Inter<String> {}
b: 在定义子类的时候还不明确数据类型,那么我们就需要将子类也定义成泛型类
public class InterImpl<E> implements Inter<E> {}
泛型通配符:
? :任意类型
? extends E :向下限定 , ?表示的是E或者E的子类
? super E :向上限定 , ? 表示的是E或者E的父类
增强for:
是为了简化数组或者集合的遍历而存在的
格式:
for(元素的数据类型 变量 : 数组或者Collection集合) {
直接使用变量,而这个变量就是容器中的元素
}
例:学生类,使用泛型
二、Set集合
Set的特点:无序 , 元素唯一
Set:元素是无序(存入和取出的顺序不一定一致),元素不可以重复。
|--HashSet:底层数据结构是哈希表。线程不同步。 保证元素唯一性的原理:判断元素的hashCode值是否相同。如果相同,还会
续判断元素的equals方法,是否为true。
|--TreeSet:可以对Set集合中的元素进行排序。默认按照字母的自然排序。底层数据结构是二叉树。保证元素唯一性的依
compareTo方法return 0。
Set集合的功能和Collection是一致的。
1、HashSet
HashSet:线程不安全,存取速度快。
可以通过元素的两个方法,hashCode和equals来完成保证元素唯一性。如果元素的HashCode值相同,才会判断equals是否为true。
如果元素的hashCode值不同,不会调用equals。
注意:HashSet对于判断元素是否存在,以及删除等操作,依赖的方法是元素的hashCode和equals方法。
例:学生类
2、TreeSet
(1)、TreeSet的特点:
a)底层的数据结构为二叉树结构(红黑树结构)
b)可对Set集合中的元素进行排序,是因为:TreeSet类实现了Comparable接口,该接口强制让增加到集合中的对象进行了比较,
要复写compareTo方法,才能让对象按指定需求(如人的年龄大小比较等)进行排序,并加入集合。
java中的很多类都具备比较性,其实就是实现了Comparable接口
注意:排序时,当主要条件相同时,按次要条件排序。
二叉树示意图:

(2)、TreeSet排序案例
例2-1:使用自然排序
需求:集合存在自定义对象,按照年龄进行排序
李世民---15
李连杰---15
成龙---18
刘亦菲---23
范冰冰---30
李冰冰---35
例2-3:使用内部类,并重写compare方法;
需求:键盘录入3个学生信息(姓名,语文成绩,数学成绩,英语成绩),按照总分从高到低输出到控制台
public class Student {
private String name ;
private int chineseScore ;
private int mathScore ;
private int englishScore ;
public Student() {
super();
}
public Student(String name, int chineseScore, int mathScore, int englishScore) {
super();
this.name = name;
this.chineseScore = chineseScore;
this.mathScore = mathScore;
this.englishScore = englishScore;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getChineseScore() {
return chineseScore;
}
public void setChineseScore(int chineseScore) {
this.chineseScore = chineseScore;
}
public int getMathScore() {
return mathScore;
}
public void setMathScore(int mathScore) {
this.mathScore = mathScore;
}
public int getEnglishScore() {
return englishScore;
}
public void setEnglishScore(int englishScore) {
this.englishScore = englishScore;
}
public int getTotal() {
return this.chineseScore + this.mathScore + this.englishScore ;
}
}
运行结果:
3、LinkedHashSet
LinkedHashSet: 底层的数据结构是链表和哈希表
特点:元素有序 , 并且元素唯一
有序是靠链表保证
唯一是靠哈希表保证
Collection集合总结
一、集合概述
集合的由来:
我们学习的语言是面向对象的语言,而面向对象的语言对事物的描述都是通过对象进行体现,那么为了方便的操作多个对象 我们应该将
这多个对象存储起来.那么既然要存储多个对象,我们就需要找一个容器类型的变量来存储.那么在我们之前的学习过程中那些都是容器
类型的变量呢?数组 , 字符串缓冲区 . 那么我们都知道数组不能满足我们变化的需求,而字符串缓冲区,返回是一个字符串,而我们的对象
不一定都是字符串.很显然这两个容器都不能满足我们的需求,那么java就给我们提供了一个比较帅气的东西,这个东西就是集合.
1、集合和数组的区别
a: 长度的区别
数组的长度是不能改变的,而集合的长度是可以改变的
b: 存储数据的类型的区别
数组可以存储基本数据类型,也可以存储引用数据类型 , 而集合只能存储引用数据类型
c: 内容的区别
数组只能存储同一种数据类型的元素 , 而集合可以存储多种数据类型的元素
2、集合中的方法
public boolean add(E e) :把指定的对象 添加到集合
public boolean addAll(Collection c) :把指定的集合添加到当前集合中
public void clear() :清除集合中的元素
public boolean remove(Object o) :从当前集合中,删除指定的元素
public boolean removeAll(Collection c) :从当前集合中,删除指定集合中的元素
public boolean contains(Object o) :判断当前集合中,是否包含指定的对象
public boolean containsAll(Collection c) :判断当前集合中,是否包含指定集合中的对象
public boolean isEmpty() :判断集合是否为空
public Iterator<E> iterator() :用来遍历集合(迭代器)
public boolean retainAll(Collection<?> c) :获取两个集合中相同的元素
public int size() :获取集合中元素的个数
public Object[] toArray() :把集合转换成数组
迭代器就是对容器中的元素进行遍历,每次取出一个元素,然后对元素进行操作。
3、ArrayList集合
ArrayList: 底层的数据结构是数组, 查询快 , 增删慢 , 线程不安全 , 效率高
ArrayList的遍历:
public class ArrayListDemo {
public static void main(String[] args) {
// 创建集合对象
ArrayList al = new ArrayList() ;
// 添加元素
al.add("武松") ;
al.add("小李广") ;
al.add("林冲") ;
// 遍历
// 第一种方式: 使用迭代器遍历
Iterator it = al.iterator() ;
// 循环
while(it.hasNext()) {
// 向下转型
String s = (String)it.next() ;
// 输出
System.out.println(s.length() + "---" + s);
}
System.out.println("------------------------------");
// 第二种方式: 使用for循环进行遍历
for(int x = 0 ; x < al.size() ; x++) {
// 向下转型
String s = (String)al.get(x) ;
// 输出
System.out.println(s + "----" + s.length());
}
}
}4、Vector集合
Vector底层的数据结构是数组 , 查询快 , 增删慢, 并且线程是安全的, 效率低
特有的功能:
public void addElement(E obj):
添加元素
public E elementAt(int index): 获取指定索引处对应的元素
public Enumeration elements(): 是遍历Vector集合的一种方式,使用类似于迭代器
public class VectorDemo {
public static void main(String[] args) {
// 创建集合对象
Vector vector = new Vector() ;
// public void addElement(E obj): 添加元素
vector.addElement("hello") ;
vector.addElement("world") ;
vector.addElement("java") ;
// public E elementAt(int index) 获取指定索引处对应的元素
// System.out.println(vector.elementAt(0));
// public Enumeration elements(): 使用遍历Vector集合的一种方式,和iterator()方法很相似
Enumeration en = vector.elements() ;
//Enumeration: boolean hasMoreElements()方法: 用来判断集合中是否存在元素
//Enumeration: E nextElement(): 获取下一个元素
while(en.hasMoreElements()) {
// 向下转型
String s = (String)en.nextElement() ;
// 输出
System.out.println(s + "----" + s.length());
}
// 输出
// System.out.println("vector : " + vector);
}
}5、LinkedList集合
LinkedList : 底层的数据结构是链表, 查询慢 , 增删块 , 线程是不安全的 , 效率高
特有的功能:
public void addFirst(E e): 在第一个位置添加元素
public void addLast(E e): 在最后一个位置添加元素
public E getFirst(): 获取第一个元素
public E getLast(): 获取最后一个元素
public E removeFirst(): 移除第一个元素,返回的是被移除的元素
public E removeLast(): 移除最后一个元素,返回的是被移除的元素
public class LinkedListDemo {
public static void main(String[] args) {
// 创建一个集合对象
LinkedList ld = new LinkedList() ;
// 添加元素
ld.add("hello") ;
ld.add("world") ;
ld.add("java") ;
// public void addFirst(E e): 在列表的开始位置添加元素
ld.addFirst("javaee") ;
// public void addLast(E e):在末尾添加元素
ld.addLast("Ajax") ;
// public E getFirst(): 获取第一个元素
System.out.println(ld.getFirst());
// public E getLast(): 获取最有一个元素
System.out.println(ld.getLast());
// public E removeFirst(): 移除第一个元素 ,返回的是被移除的元素
System.out.println(ld.removeFirst());
// public E removeLast(): 移除最后一个元素 , 返回的是被移除的元素
System.out.println(ld.removeLast());
// 输出
System.out.println("ld : " + ld);
}
}6、ArrayList、Vector、LinkedList的特点和区别
ArrayList:
底层数组结构;线程不同步,效率高;元素查找快、增删慢;
Vector:
底层数组结构;线程同步,安全;元素查找快、增删慢;
LinkedList:
底层链表结构,线程不同步,效率高;元素增删快、查找慢
7、泛型
概念:是一种把类型的明确推迟到了创建对象或者调用方法的时候的一种特殊类型. 参数化类型 , 可以把这个类型作为参数传递。
格式:
<数据类型>
数据类型: 只能是引用数据类型
泛型的好处:
a: 把运行期的错误提前到了编译期
b: 省去向下转型
c: 去除了黄色警告线
泛型的注意事项:
泛型只针对编译期有效,到了运行期就会把泛型去掉,其实就是泛型擦除 .
泛型的应用:
泛型类:
把泛型定义在类上
格式: public class 类名<数据类型 , ... >{}
泛型方法:把泛型定义在方法上
格式: public <数据类型> 返回值类型 方法名(数据类型 变量名) {}
泛型接口: 把泛型定义在接口上
格式: public interface 接口名<数据类型> {}
泛型接口的子类:
a: 在定义子类的时候已经可以明确数据类型类
public class InterImpl implements Inter<String> {}
b: 在定义子类的时候还不明确数据类型,那么我们就需要将子类也定义成泛型类
public class InterImpl<E> implements Inter<E> {}
泛型通配符:
? :任意类型
? extends E :向下限定 , ?表示的是E或者E的子类
? super E :向上限定 , ? 表示的是E或者E的父类
增强for:
是为了简化数组或者集合的遍历而存在的
格式:
for(元素的数据类型 变量 : 数组或者Collection集合) {
直接使用变量,而这个变量就是容器中的元素
}
例:学生类,使用泛型
public class Student {
private String name ;
private int age ;
public Student() {
super();
// TODO Auto-generated constructor stub
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}public class GenericTest {
public static void main(String[] args) {
// 创建集合对象
ArrayList<Student> al = new ArrayList<Student>() ;
// 创建自定义对象
Student s1 = new Student("不良帅" , 200) ;
Student s2 = new Student("冥帝" , 13) ;
Student s3 = new Student("李星云" , 18) ;
Student s4 = new Student("姬如雪" , 16) ;
// 把自定义对象添加到集合中
al.add(s1) ;
al.add(s2) ;
al.add(s3) ;
al.add(s4) ;
// 遍历
// 使用迭代器进行遍历
Iterator<Student> it = al.iterator() ;
// 循环
while(it.hasNext()) {
// 获取元素
Student s = it.next() ;
// 输出
System.out.println(s.getName() + "---" + s.getAge());
}
}
}二、Set集合
Set的特点:无序 , 元素唯一
Set:元素是无序(存入和取出的顺序不一定一致),元素不可以重复。
|--HashSet:底层数据结构是哈希表。线程不同步。 保证元素唯一性的原理:判断元素的hashCode值是否相同。如果相同,还会
续判断元素的equals方法,是否为true。
|--TreeSet:可以对Set集合中的元素进行排序。默认按照字母的自然排序。底层数据结构是二叉树。保证元素唯一性的依
compareTo方法return 0。
Set集合的功能和Collection是一致的。
public static void main(String[] args) {
// 创建对象
Set<String> set = new HashSet<String>() ;
// 添加元素
set.add("hello") ;
set.add("java") ;
set.add("world") ;
set.add("java") ;
// 遍历
// Set集合不能使用普通for进行遍历
for(String s : set){
System.out.println(s);
}
}
}1、HashSet
HashSet:线程不安全,存取速度快。
可以通过元素的两个方法,hashCode和equals来完成保证元素唯一性。如果元素的HashCode值相同,才会判断equals是否为true。
如果元素的hashCode值不同,不会调用equals。
注意:HashSet对于判断元素是否存在,以及删除等操作,依赖的方法是元素的hashCode和equals方法。
例:学生类
public class Student {
private String name ;
private int age ;
public Student() {
super();
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
}public class HashSetDemo {
public static void main(String[] args) {
// 创建集合对象
HashSet<Student> hashSet = new HashSet<Student>() ;
// 创建自定义对象
Student s1 = new Student("刘亦菲" , 23) ;
Student s2 = new Student("范冰冰" , 32) ;
Student s3 = new Student("李冰冰" , 35) ;
Student s4 = new Student("刘亦菲" , 23) ;
Student s5 = new Student("刘亦菲" , 18) ;
Student s6 = new Student("李冰冰" , 35) ;
// 把元素添加到集合中
hashSet.add(s1) ;
hashSet.add(s2) ;
hashSet.add(s3) ;
hashSet.add(s4) ;
hashSet.add(s5) ;
hashSet.add(s6) ;
// 遍历
for(Student s : hashSet) {
// 输出
System.out.println(s.getName() + "----" + s.getAge());
}
}
}2、TreeSet
(1)、TreeSet的特点:
a)底层的数据结构为二叉树结构(红黑树结构)
b)可对Set集合中的元素进行排序,是因为:TreeSet类实现了Comparable接口,该接口强制让增加到集合中的对象进行了比较,
要复写compareTo方法,才能让对象按指定需求(如人的年龄大小比较等)进行排序,并加入集合。
java中的很多类都具备比较性,其实就是实现了Comparable接口
注意:排序时,当主要条件相同时,按次要条件排序。
二叉树示意图:
(2)、TreeSet排序案例
例2-1:使用自然排序
public class TreeSetDemo {
public static void main(String[] args) {
// 创建对象
TreeSet<Integer> treeSet = new TreeSet<Integer>() ; // 使用自然排序
// 添加元素
// 存储下列元素: 20 , 18 , 23 , 22 , 17 , 24, 19 , 18 , 24
treeSet.add(20) ;
treeSet.add(18) ;
treeSet.add(23) ;
treeSet.add(22) ;
treeSet.add(17) ;
treeSet.add(24) ;
treeSet.add(19) ;
treeSet.add(18) ;
treeSet.add(24) ;
// 遍历
for(Integer i : treeSet) {
System.out.println(i);
}
}
}例2-2:实现Comparator接口,并重写compare方法;需求:集合存在自定义对象,按照年龄进行排序
public class MyComparator implements Comparator<Student> {
@Override
public int compare(Student s1, Student s2) {
// 比较年龄
int num = s1.getAge() - s2.getAge() ;
// 比较姓名
int num2 = (num == 0) ? s1.getName().compareTo(s2.getName()) : num ;
return num2;
}
}public class Student {
private String name ;
private int age ;
public Student() {
super();
// TODO Auto-generated constructor stub
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}public class TreeSetDemo {
public static void main(String[] args) {
// 创建对象
// TreeSet<Student> treeSet = new TreeSet<Student>(new MyComparator()) ;
TreeSet<Student> treeSet = new TreeSet<Student>( new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
// 比较年龄
int num = s1.getAge() - s2.getAge() ;
// 比较姓名
int num2 = (num == 0) ? s1.getName().compareTo(s2.getName()) : num ;
return num2;
}
}) ;
// 创建自定义对象
Student s1 = new Student("刘亦菲" , 23) ;
Student s2 = new Student("李冰冰" , 35) ;
Student s3 = new Student("范冰冰" , 30) ;
Student s4 = new Student("成龙" , 18) ;
Student s5 = new Student("李连杰" , 15) ;
Student s6 = new Student("李世民" , 15) ;
// 把自定义对象添加到集合中
treeSet.add(s1) ;
treeSet.add(s2) ;
treeSet.add(s3) ;
treeSet.add(s4) ;
treeSet.add(s5) ;
treeSet.add(s6) ;
// 遍历
for(Student s : treeSet) {
// 输出
System.out.println(s.getName() + "---" + s.getAge());
}
}
}运行结果:李世民---15
李连杰---15
成龙---18
刘亦菲---23
范冰冰---30
李冰冰---35
例2-3:使用内部类,并重写compare方法;
需求:键盘录入3个学生信息(姓名,语文成绩,数学成绩,英语成绩),按照总分从高到低输出到控制台
public class Student {
private String name ;
private int chineseScore ;
private int mathScore ;
private int englishScore ;
public Student() {
super();
}
public Student(String name, int chineseScore, int mathScore, int englishScore) {
super();
this.name = name;
this.chineseScore = chineseScore;
this.mathScore = mathScore;
this.englishScore = englishScore;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getChineseScore() {
return chineseScore;
}
public void setChineseScore(int chineseScore) {
this.chineseScore = chineseScore;
}
public int getMathScore() {
return mathScore;
}
public void setMathScore(int mathScore) {
this.mathScore = mathScore;
}
public int getEnglishScore() {
return englishScore;
}
public void setEnglishScore(int englishScore) {
this.englishScore = englishScore;
}
public int getTotal() {
return this.chineseScore + this.mathScore + this.englishScore ;
}
}
public class TreeSetTest {
public static void main(String[] args) {
// 创建对象
TreeSet<Student> treeSet = new TreeSet<Student>(new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
// 按照总分从高到低输出到控制台。
int num = s2.getTotal() - s1.getTotal() ;
// 比较语文成绩
int num2 = (num == 0) ? s2.getChineseScore() - s1.getChineseScore() : num ;
// 比较数学成绩
int num3 = (num2 == 0 )? s2.getMathScore() - s1.getMathScore() : num2 ;
// 比较英语成绩
int num4 = (num3 == 0) ? s2.getEnglishScore() - s1.getEnglishScore() : num3 ;
// 比较姓名
int num5 = (num4 == 0) ? s2.getName().compareTo(s1.getName()) : num4 ;
return num5;
}
}) ;
// 键盘录入学生信息
for(int x = 0 ; x < 3 ; x++) {
Scanner sc = new Scanner(System.in) ; // 创建Scanner对象
System.out.println("请您输入姓名: ");
String userName = sc.nextLine() ;
System.out.println("请您输入语文成绩:" );
String chineseScoreStr = sc.nextLine() ;
System.out.println("请您输入数学成绩:" );
String mathScoreStr = sc.nextLine() ;
System.out.println("请您输入英语成绩:" );
String englishScoreStr = sc.nextLine() ;
// 把数据封装成一个学生对象
Student s = new Student() ;
s.setName(userName) ;
s.setChineseScore(Integer.parseInt(chineseScoreStr)) ;
s.setMathScore(Integer.parseInt(mathScoreStr)) ;
s.setEnglishScore(Integer.parseInt(englishScoreStr)) ;
// 把学生对象添加到集合中
treeSet.add(s) ;
}
System.out.println("学生信息录入完毕........");
// 遍历
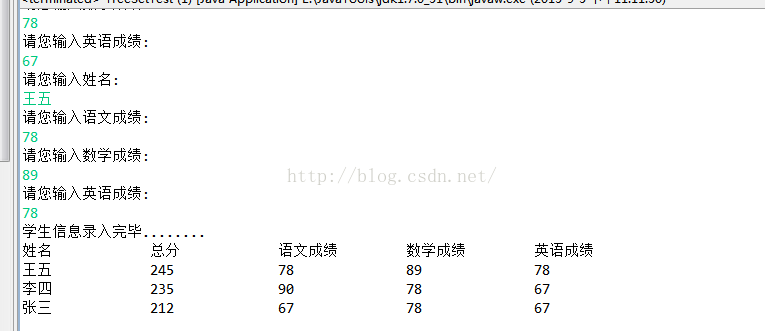
System.out.println("姓名\t\t总分\t\t语文成绩\t\t数学成绩\t\t英语成绩");
for(Student s : treeSet) {
System.out.println(s.getName() + "\t\t" + s.getTotal() + "\t\t" + s.getChineseScore() + "\t\t" + s.getMathScore() + "\t\t" + s.getEnglishScore());
}
}
}运行结果:
3、LinkedHashSet
LinkedHashSet: 底层的数据结构是链表和哈希表
特点:元素有序 , 并且元素唯一
有序是靠链表保证
唯一是靠哈希表保证
public class LinkedHashSetDemo {
public static void main(String[] args) {
// 创建对象
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<String>() ;
// 添加元素
linkedHashSet.add("hello") ;
linkedHashSet.add("world") ;
linkedHashSet.add("java") ;
linkedHashSet.add("java") ;
// 遍历
for(String s : linkedHashSet) {
System.out.println(s);
}
}
}

相关文章推荐
- 数组中只出现1次的两个数字(面试题)
- 常见的链表面试题大汇总:
- 管理层必学!刘备如何面试诸葛亮?
- Java面试题之一---------字符串截取(字节分配)(编码)
- 黑马程序员之IO字符流及缓冲器
- 找到一个重复元素 - 面试题
- 黑马程序员——Java中的面向对象
- 黑马程序员之Collection类
- 黑马程序员之Map集合以及Collections静态方法
- BAT面试
- 临睡前的十分钟,决定未来职场的高度
- 程序员的十个层次
- 说我装13?过来,打屎你!(揭秘程序员装13面具)
- 程序员有趣的面试智力题
- 黑马程序员-Java基础:常用API
- 腾讯面试(三)
- 【年度总结】一个程序员的自我修养
- 黑马程序员--IO流(操作对象、管道流、RandomAccessFile)
- [翻译]程序员需要掌握的6项相关技能
- 黑马程序员——面向对象(多态+接口实现)-第18天