leetcode 10 Regular Expression Matching
2015-08-22 06:56
465 查看
Regular Expression Matching
Total Accepted: 51566 Total Submissions: 249926
Implement regular expression matching with support for ‘.’ and ‘*’.
‘.’ Matches any single character.
‘*’ Matches zero or more of the preceding element.
The matching should cover the entire input string (not partial).
The function prototype should be:
bool isMatch(const char *s, const char *p)
Some examples:
isMatch(“aa”,”a”) → false
isMatch(“aa”,”aa”) → true
isMatch(“aaa”,”aa”) → false
isMatch(“aa”, “a*”) → true
isMatch(“aa”, “.*”) → true
isMatch(“ab”, “.*”) → true
isMatch(“aab”, “c*a*b”) → true
这道题是一道很经典的题,据说也曾经是facebook的面试题,自己思考时,认为情况太多难以划分,遂搜索了网上他人的代码,大概的做法可以分为两大类:动态规划和递归,在动态规划的效率明显高于递归,但递归方法更容易理解。我主要参看了以下两个帖子:http://bangbingsyb.blogspot.com/2014/11/leetcode-regular-expression-matching.html 和http://www.2cto.com/kf/201404/290845.html
‘*’和’.’是正则表达式中两个重要的字符,它们的意义分别是:.可以匹配任意的单个字符,而*则表示可以0个或1个或多个*号前的字符。那么我么就可以解释上面例子中,aab为何和c*a*b匹配,由于*号表示取0个或1个或多个*号前的字符,那么我们就可以取0个c两个a,c*a*b变成aab,从而与aab匹配。我们可以再看一个例子:123345和1.*3*4*,看上去好像不匹配,因为123345有个5,而1.*3*4*根本就没有5。但在仔细看,会发现其实还是匹配的,因为我们可以选5个. 0个3和0个4,这样1.*3*4* 就变成了1 … . . , 由于.和任意字符匹配,所以与123345匹配。另外,要特别提一下的是,在正则表达式的规定中,*号不能出现在正则表达式的第一个位置,同时也不能出现两个连续的*。
熟悉了匹配方法,那么就来看下如何求解这个问题,我们先来看效率较高的动态规划的方法。
1. 动态规划
我们结合代码来讲:
首先是一个基本的错误判断,如果指针为空,那么必然是错误的,同时,由于第一位不能是*,所以如果发现是*,也返回false。此处要提醒一下指针为空和指向空字符串是两个概念,前者指向NULL,后者指向一个仅存有’\0’的字符串。接着继续做一些准备工作,得到两个字符串的长度,然后生成一张动态规划要用的表,然后全部初始化为false。表的维度是(slen + 1) * (plen + 1),之所以要加1,是因为我们要是用表的索引来标识匹配的串的长度,例如dp[i][j] == false 表示s串中的前i个字符和p串中的前j个字符不能匹配,而dp[slen][plen] 就表示的两个串的所有字符能否匹配,因此维度需要到(slen + 1) * (plen + 1)。
另外值得一提的是:dp[0][a] 表示s为空串的情况下,p的前a个字符与它匹配的情况,感觉上好像两者不可能匹配,其实不然,假设p为a*,那我们就可以取0个a,这样p也是空串,两者变匹配了。那么如果反过来dp[a][0]可不可能匹配呢?答案是否定的,因为p是正则表达式,即便不为空,也能通过*缩成空串,但反过来就不行了,s是普通字符串,如果不为空,那就没有办法缩成空串,而此时正则表达式又为空只能表示空串,所以两者无法匹配。
这一部分就进入算法的核心部分了,首先初始化dp[0][0]=true表示两个串都是空串的时候是匹配的。然后开始双重循环便利整个dp表,值得注意的是j是从1开始遍历的,这就跟我们之前讲的相关了,j为0时,表示正则表达式为空串,此时普通字符串只要不是空串,就一定不匹配,所以dp[i][0] == false, (i>0), 而我们之前初始化时,已经将表中每一格都设为false了, 因此没有必要再到循环中去计算这些值。正式进入循环以后,可以发现我们根据p[j-1]的取值划分了三大类,之所以是p[j-1]而不是p[j]是因为当前我们要求dp[i][j],即s的前i个字符和p的前j个字符的匹配情况,而p的前j个字符的最后一个就是p[j-1]. 第一类:p[j-1]既不等于*又不等于.,那么在这种情况下,dp[i][j]要为true,那么只可能是s的前i-1个字符和p的前j-1个字符匹配的情况下s的第i个字符又等于p的第j个字符。当然i必须大于0,否则s是空串,倘若p中最后一个是*,那还有机会匹配,但p中最后一个又是非*和.的字符,所以不能匹配。第二类:p[j-1]等于. ,从代码就可以看出其实过程和前一类很像只是不要求s的第i个字符等于p的第j个字符,因为.可以匹配任何一个单个字符,所以即使不相等,仍然能匹配。第三类:也是最复杂的一类,即:p[j-1]等于*,首先处理*代表取0个的情况,如图:
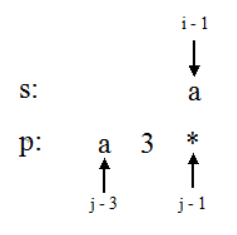
我们可以发现如果dp[i][j-2]==true,即s的前i个字符和p的前j-2个字符匹配,那么我们就可以让*表示0个,这样的话,s的前i个字符和p的前j个字符匹配了,dp[i][j] == true。
接下来是*代表取1个或多个的情况,如图:
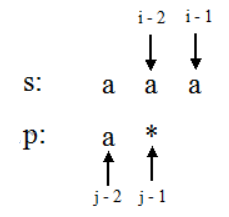
我们可以发现,如果dp[i-1][j]==true的话,那么只要p[j-2] == s[i-1]或者p[j-2] == ‘.’, 那么我们通过*多取一个p[j-2]所代表的字符,那么s的前i个字符和p的前j个字符匹配了,dp[i][j] == true。换句话说,如果dp[i-1][j]==true时,代表取x个p[j-2]所代表的字符来匹配成功,那么dp[i][j]==true时,代表取x+1个p[j-2]所代表的字符来匹配成功.
完成循环后,dp[slen][plen]代表的就是两个串整体匹配的结果。
2. 递归
先来看完整函数的代码:
首先与刚才的动态规划算法一样,我们还是首先要判断两个串是否为空,同时判断是否会是p指向*的情况,由于我们的实现通过的是递归的方式,所以这个判断条件将被多次执行,通过算法后面的描述,我们可以发现p是不会指向*的,如果指向*那么就报错返回false。第二个判断条件是如果两者都指向\0,那么说明前面都已经匹配好了,而现在两个串都结束了,说明这两个串是匹配的。第三种情况,如果p串(即:正则表达式)已经结束了,而s串仍然还有字符,那么这些字符就没法匹配,所以返回false。第四种情况,如果s串已经结束了,但p串仍然有字符,那么如果p串当前字符的下一个是*,那么就仍然有机会匹配,因为我们可以让*表示取0个*前面的字符。但如果p串当前字符的下一个不是*,那么这个字符没有办法与s串匹配,所以返回false。
那么针对p当前字符的下一个是*的情况,我们就可以有分成两大类情况,第一类是*代表取0个*前的字符,因为我们要求的是isMatch(s,p),即从s开始的串和从p开始的串的匹配情况,那么如果isMatch(s,p+2)==true,我们就可以通过使得*代表取0个*前的字符,此时,p开头的串就和p+2开头的串是相同的,从而isMatch(s,p)==true,但如果isMatch(s,p+2)==false,也并不代表isMatch(s,p)就一定为false,因为我们还可以通过使得*代表取1,2,3,…个*前的字符,来看是否有匹配的情况。最多可以到len个(len代表s串的长度),例如:s:22222222,p:2*,那么这两个串是匹配的,*代表取8个*前的字符。所以我们的for循环最多进行len次,但是绝大多数情况下是进行不到len次的,因为只要*前面的字符不等于s+i指向的字符并且*前面的字符不为.,那么就没有必要继续循环了,因为再循环也只会增加*前面的字符,所以新增加的字符同样不等于s+i指向的字符。所以必然匹配失败,所以返回false。另一方面如果*前面的字符等于s+i指向的字符,因为循环从0执行到i说明,从s开始到s+i都等于*前面的字符,此时如果从s+i+1和p+2开始的字符串匹配,那么我们就可以通过使*代表i+1个*前面的字符,来使得从s和p开始的串匹配,因此返回isMatch(s,p)==true。如果整个循环结束了仍然没有返回true或false,那么这种情况下我们应该返回false,因为*已经取了所用它可以取的值,仍然找不到匹配,所以返回false,例如:s:22222222,p:2*3。
那么针对p当前字符的下一个不是*的情况,就比较简单了,因为不可能通过下一个*来‘消掉’(即取0个)当前字符,所以要想匹配,那么当前字符就必须相等,要不然p当前字符就必须是.,否则就必然匹配失败。如果当前字符相等或p当前字符是.,那么我们就要看从s+1和p+1开始的字符串是否匹配了,如果匹配,由于s指向的字符与p指向的字符匹配,那么从s和p开始的字符串就是匹配的。如果不匹配,那么p指向的字符也不能调整个数,所以从s和p开始的字符串也就是不匹配的。
下面是包含两种实现方式的完整代码
Total Accepted: 51566 Total Submissions: 249926
Implement regular expression matching with support for ‘.’ and ‘*’.
‘.’ Matches any single character.
‘*’ Matches zero or more of the preceding element.
The matching should cover the entire input string (not partial).
The function prototype should be:
bool isMatch(const char *s, const char *p)
Some examples:
isMatch(“aa”,”a”) → false
isMatch(“aa”,”aa”) → true
isMatch(“aaa”,”aa”) → false
isMatch(“aa”, “a*”) → true
isMatch(“aa”, “.*”) → true
isMatch(“ab”, “.*”) → true
isMatch(“aab”, “c*a*b”) → true
这道题是一道很经典的题,据说也曾经是facebook的面试题,自己思考时,认为情况太多难以划分,遂搜索了网上他人的代码,大概的做法可以分为两大类:动态规划和递归,在动态规划的效率明显高于递归,但递归方法更容易理解。我主要参看了以下两个帖子:http://bangbingsyb.blogspot.com/2014/11/leetcode-regular-expression-matching.html 和http://www.2cto.com/kf/201404/290845.html
‘*’和’.’是正则表达式中两个重要的字符,它们的意义分别是:.可以匹配任意的单个字符,而*则表示可以0个或1个或多个*号前的字符。那么我么就可以解释上面例子中,aab为何和c*a*b匹配,由于*号表示取0个或1个或多个*号前的字符,那么我们就可以取0个c两个a,c*a*b变成aab,从而与aab匹配。我们可以再看一个例子:123345和1.*3*4*,看上去好像不匹配,因为123345有个5,而1.*3*4*根本就没有5。但在仔细看,会发现其实还是匹配的,因为我们可以选5个. 0个3和0个4,这样1.*3*4* 就变成了1 … . . , 由于.和任意字符匹配,所以与123345匹配。另外,要特别提一下的是,在正则表达式的规定中,*号不能出现在正则表达式的第一个位置,同时也不能出现两个连续的*。
熟悉了匹配方法,那么就来看下如何求解这个问题,我们先来看效率较高的动态规划的方法。
1. 动态规划
我们结合代码来讲:
bool isMatch(char *s, char *p)
{
if(s == NULL || p == NULL || *p == '*')
return false;
int slen = strlen(s);
int plen = strlen(p);
bool **dp = (bool**)malloc(sizeof(bool*) * (slen + 1));
for(int i = 0; i <= slen; i++)
{
dp[i] = (bool*)malloc(sizeof(bool) * (plen + 1));
memset(dp[i], false, plen + 1);
}首先是一个基本的错误判断,如果指针为空,那么必然是错误的,同时,由于第一位不能是*,所以如果发现是*,也返回false。此处要提醒一下指针为空和指向空字符串是两个概念,前者指向NULL,后者指向一个仅存有’\0’的字符串。接着继续做一些准备工作,得到两个字符串的长度,然后生成一张动态规划要用的表,然后全部初始化为false。表的维度是(slen + 1) * (plen + 1),之所以要加1,是因为我们要是用表的索引来标识匹配的串的长度,例如dp[i][j] == false 表示s串中的前i个字符和p串中的前j个字符不能匹配,而dp[slen][plen] 就表示的两个串的所有字符能否匹配,因此维度需要到(slen + 1) * (plen + 1)。
另外值得一提的是:dp[0][a] 表示s为空串的情况下,p的前a个字符与它匹配的情况,感觉上好像两者不可能匹配,其实不然,假设p为a*,那我们就可以取0个a,这样p也是空串,两者变匹配了。那么如果反过来dp[a][0]可不可能匹配呢?答案是否定的,因为p是正则表达式,即便不为空,也能通过*缩成空串,但反过来就不行了,s是普通字符串,如果不为空,那就没有办法缩成空串,而此时正则表达式又为空只能表示空串,所以两者无法匹配。
dp[0][0] = true;
for(int i = 0; i <= slen; i++)
{
for(int j = 1; j <= plen; j++)
{
if(p[j-1] != '.' && p[j-1] != '*')
{
if(i > 0 && s[i-1] == p[j-1] && dp[i-1][j-1])
dp[i][j] = true;
}
else if(p[j-1] == '.')
{
if(i > 0 && dp[i-1][j-1])
dp[i][j] = true;
}
else
{
if(dp[i][j-2])
dp[i][j] = true;
else if(i > 0 && (s[i-1] == p[j-2] || p[j-2] == '.') && dp[i-1][j])
dp[i][j] = true;
}
}
}
return dp[slen][plen];
}这一部分就进入算法的核心部分了,首先初始化dp[0][0]=true表示两个串都是空串的时候是匹配的。然后开始双重循环便利整个dp表,值得注意的是j是从1开始遍历的,这就跟我们之前讲的相关了,j为0时,表示正则表达式为空串,此时普通字符串只要不是空串,就一定不匹配,所以dp[i][0] == false, (i>0), 而我们之前初始化时,已经将表中每一格都设为false了, 因此没有必要再到循环中去计算这些值。正式进入循环以后,可以发现我们根据p[j-1]的取值划分了三大类,之所以是p[j-1]而不是p[j]是因为当前我们要求dp[i][j],即s的前i个字符和p的前j个字符的匹配情况,而p的前j个字符的最后一个就是p[j-1]. 第一类:p[j-1]既不等于*又不等于.,那么在这种情况下,dp[i][j]要为true,那么只可能是s的前i-1个字符和p的前j-1个字符匹配的情况下s的第i个字符又等于p的第j个字符。当然i必须大于0,否则s是空串,倘若p中最后一个是*,那还有机会匹配,但p中最后一个又是非*和.的字符,所以不能匹配。第二类:p[j-1]等于. ,从代码就可以看出其实过程和前一类很像只是不要求s的第i个字符等于p的第j个字符,因为.可以匹配任何一个单个字符,所以即使不相等,仍然能匹配。第三类:也是最复杂的一类,即:p[j-1]等于*,首先处理*代表取0个的情况,如图:
我们可以发现如果dp[i][j-2]==true,即s的前i个字符和p的前j-2个字符匹配,那么我们就可以让*表示0个,这样的话,s的前i个字符和p的前j个字符匹配了,dp[i][j] == true。
接下来是*代表取1个或多个的情况,如图:
我们可以发现,如果dp[i-1][j]==true的话,那么只要p[j-2] == s[i-1]或者p[j-2] == ‘.’, 那么我们通过*多取一个p[j-2]所代表的字符,那么s的前i个字符和p的前j个字符匹配了,dp[i][j] == true。换句话说,如果dp[i-1][j]==true时,代表取x个p[j-2]所代表的字符来匹配成功,那么dp[i][j]==true时,代表取x+1个p[j-2]所代表的字符来匹配成功.
完成循环后,dp[slen][plen]代表的就是两个串整体匹配的结果。
2. 递归
先来看完整函数的代码:
bool isMatch(char *s, char *p)
{
if(s == NULL || p == NULL || *p == '*')
return false;
if(*s == '\0' && *p == '\0')
return true;
if(*p == '\0' && *s != '\0')
return false;
if(*s == '\0' && *(p+1) != '*')
return false;
if(*(p+1) == '*')
{
if(isMatch(s, p+2))
return true;
int len = strlen(s);
for(int i = 0; i < len; i++)
{
if(*(s+i) != *p && *p!= '.')
{
return false;
}
if(isMatch(s+i+1, p+2))
return true;
}
return false;
}
else
{
if(*s != *p && *p != '.')
return false;
return isMatch(s+1, p+1);
}
}首先与刚才的动态规划算法一样,我们还是首先要判断两个串是否为空,同时判断是否会是p指向*的情况,由于我们的实现通过的是递归的方式,所以这个判断条件将被多次执行,通过算法后面的描述,我们可以发现p是不会指向*的,如果指向*那么就报错返回false。第二个判断条件是如果两者都指向\0,那么说明前面都已经匹配好了,而现在两个串都结束了,说明这两个串是匹配的。第三种情况,如果p串(即:正则表达式)已经结束了,而s串仍然还有字符,那么这些字符就没法匹配,所以返回false。第四种情况,如果s串已经结束了,但p串仍然有字符,那么如果p串当前字符的下一个是*,那么就仍然有机会匹配,因为我们可以让*表示取0个*前面的字符。但如果p串当前字符的下一个不是*,那么这个字符没有办法与s串匹配,所以返回false。
那么针对p当前字符的下一个是*的情况,我们就可以有分成两大类情况,第一类是*代表取0个*前的字符,因为我们要求的是isMatch(s,p),即从s开始的串和从p开始的串的匹配情况,那么如果isMatch(s,p+2)==true,我们就可以通过使得*代表取0个*前的字符,此时,p开头的串就和p+2开头的串是相同的,从而isMatch(s,p)==true,但如果isMatch(s,p+2)==false,也并不代表isMatch(s,p)就一定为false,因为我们还可以通过使得*代表取1,2,3,…个*前的字符,来看是否有匹配的情况。最多可以到len个(len代表s串的长度),例如:s:22222222,p:2*,那么这两个串是匹配的,*代表取8个*前的字符。所以我们的for循环最多进行len次,但是绝大多数情况下是进行不到len次的,因为只要*前面的字符不等于s+i指向的字符并且*前面的字符不为.,那么就没有必要继续循环了,因为再循环也只会增加*前面的字符,所以新增加的字符同样不等于s+i指向的字符。所以必然匹配失败,所以返回false。另一方面如果*前面的字符等于s+i指向的字符,因为循环从0执行到i说明,从s开始到s+i都等于*前面的字符,此时如果从s+i+1和p+2开始的字符串匹配,那么我们就可以通过使*代表i+1个*前面的字符,来使得从s和p开始的串匹配,因此返回isMatch(s,p)==true。如果整个循环结束了仍然没有返回true或false,那么这种情况下我们应该返回false,因为*已经取了所用它可以取的值,仍然找不到匹配,所以返回false,例如:s:22222222,p:2*3。
那么针对p当前字符的下一个不是*的情况,就比较简单了,因为不可能通过下一个*来‘消掉’(即取0个)当前字符,所以要想匹配,那么当前字符就必须相等,要不然p当前字符就必须是.,否则就必然匹配失败。如果当前字符相等或p当前字符是.,那么我们就要看从s+1和p+1开始的字符串是否匹配了,如果匹配,由于s指向的字符与p指向的字符匹配,那么从s和p开始的字符串就是匹配的。如果不匹配,那么p指向的字符也不能调整个数,所以从s和p开始的字符串也就是不匹配的。
下面是包含两种实现方式的完整代码
#include "stdio.h"
#include "string.h"
#include <stdlib.h>
#include <string>
#include <vector>
#include <iostream>
using namespace std;
bool isMatch(char *s, char *p) { if(s == NULL || p == NULL || *p == '*') return false; if(*s == '\0' && *p == '\0') return true; if(*p == '\0' && *s != '\0') return false; if(*s == '\0' && *(p+1) != '*') return false; if(*(p+1) == '*') { if(isMatch(s, p+2)) return true; int len = strlen(s); for(int i = 0; i < len; i++) { if(*(s+i) != *p && *p!= '.') { return false; } if(isMatch(s+i+1, p+2)) return true; } return false; } else { if(*s != *p && *p != '.') return false; return isMatch(s+1, p+1); } }
bool isMatch3(char *s, char *p)
{
if(s == NULL || p == NULL || *p == '*')
return false;
int slen = strlen(s);
int plen = strlen(p);
bool **dp = (bool**)malloc(sizeof(bool*) * (slen + 1));
for(int i = 0; i <= slen; i++)
{
dp[i] = (bool*)malloc(sizeof(bool) * (plen + 1));
memset(dp[i], false, plen + 1);
}
dp[0][0] = true;
for(int i = 0; i <= slen; i++)
{
for(int j = 1; j <= plen; j++)
{
if(p[j-1] != '.' && p[j-1] != '*')
{
if(i > 0 && s[i-1] == p[j-1] && dp[i-1][j-1])
dp[i][j] = true;
}
else if(p[j-1] == '.')
{
if(i > 0 && dp[i-1][j-1])
dp[i][j] = true;
}
else
{
if(dp[i][j-2])
dp[i][j] = true;
else if(i > 0 && (s[i-1] == p[j-2] || p[j-2] == '.') && dp[i-1][j])
dp[i][j] = true;
}
}
}
return dp[slen][plen];
}
int main()
{
char s[1000], p[1000];
while(true)
{
scanf("%s",s);
if(strcmp(s,"end") == 0)
break;
printf("%s\n",s);
scanf("%s",p);
if(strcmp(s,"end") == 0)
break;
printf("%s\n",p);
string ss(s);
string sp(p);
//s[0] = '\0';
printf("%d", isMatch(s, p));
printf("%d\n", isMatch3(s, p));
}
return 0;
}

相关文章推荐
- leetcode 179 Largest Number
- leetcode 24 Swap Nodes in Pairs
- leetcode 2 Add Two Numbers 方法1
- leetcode 2 Add Two Numbers 方法2
- [LeetCode]47 Permutations II
- [LeetCode]65 Valid Number
- [LeetCode]123 Best Time to Buy and Sell Stock III
- [LeetCode] String Reorder Distance Apart
- [LeetCode] Sliding Window Maximum
- [LeetCode] Find the k-th Smallest Element in the Union of Two Sorted Arrays
- [LeetCode] Determine If Two Rectangles Overlap
- [LeetCode] A Distance Maximizing Problem
- leetcode_linearList
- leetcode_linearList02
- LeetCode[Day 1] Two Sum 题解
- LeetCode[Day 2] Median of Two Sorted Arrays 题解
- LeetCode[Day 3] Longest Substring Without... 题解
- LeetCode [Day 4] Add Two Numbers 题解
- LeetCode [Day 5] Longest Palindromic Substring 题解
- LeetCode [Day 6] ZigZag Conversion 题解