数据结构基础温故-5.图(中):最小生成树算法
2015-07-29 01:05
351 查看
图的“多对多”特性使得图在结构设计和算法实现上较为困难,这时就需要根据具体应用将图转换为不同的树来简化问题的求解。
采用深度优先遍历获得的生成树称为深度优先生成树(DFS生成树),采用广度优先遍历获得的生成树称为广度优先生成树(BFS生成树)。如下图所示,无向图的DFS生成树和BFS生成树分别如图的中间和右边所示。

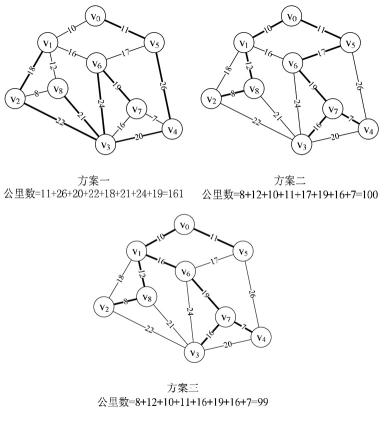
求网络的最小生成树的重要意义就在于:假如要在n个城市之间铺设光缆,由于地理环境的不同,各个城市之间铺设光缆的费用也不同。一方面要使得这n个城市可以直接或间接通信,另一方面要考虑铺设光缆的费用最低。解决这个问题的方法就是在n个顶点(城市)和不同权值的边(这里指铺设光缆的费用)所构成的无向连通图中找出最小生成树。

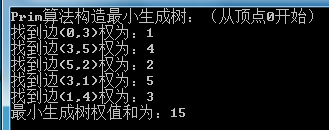
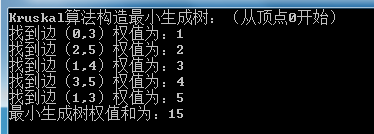
运行结果如下图所示,最小生成树的权值和为15:
Summary:Prim算法主要是对图的顶点进行操作,它适用于稠密图。
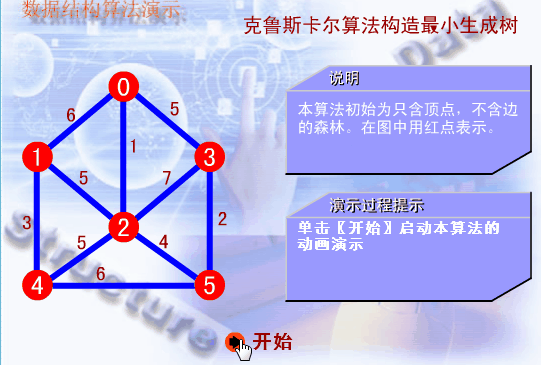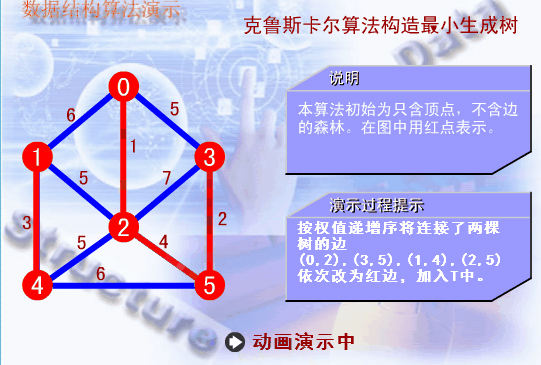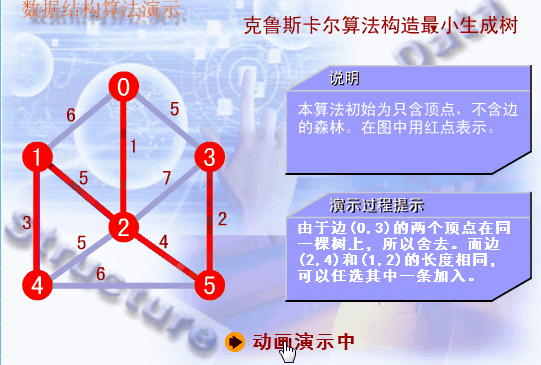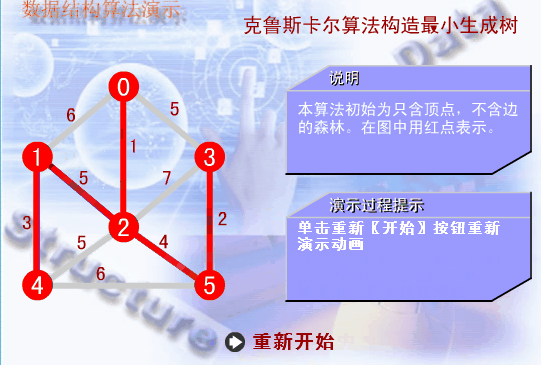
下面是一个Kruskal算法的演示:
(2)创建按权值排序的边的集合
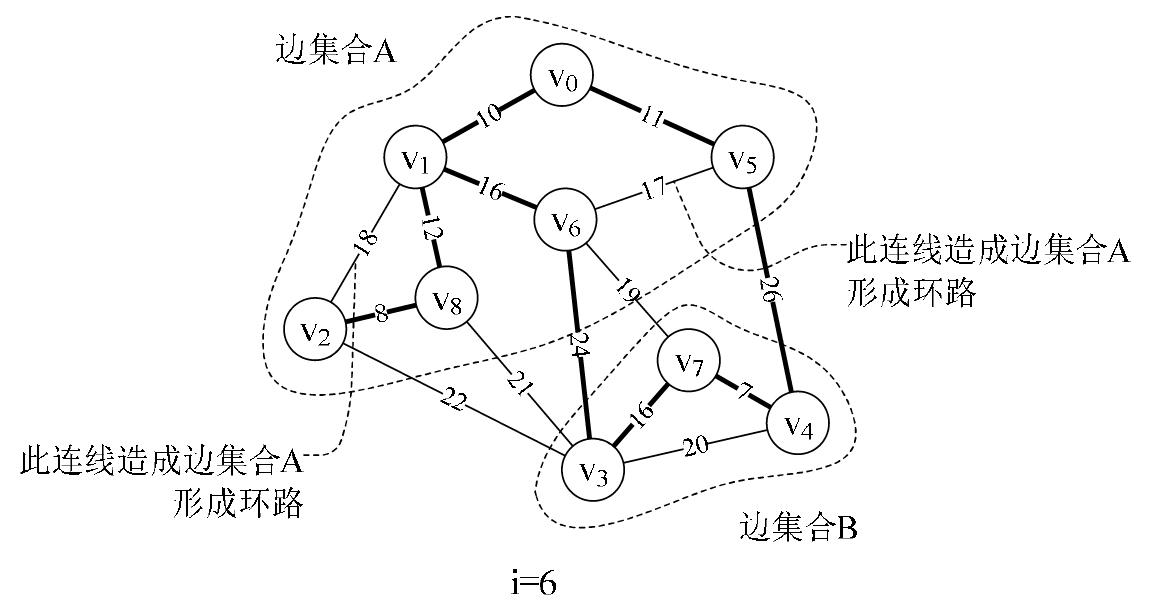
(3)Kruskal核心代码:Kruskal的实现过程是将森林变成树的过程,可以给森林中的每一棵树配置一个唯一的分组号,当两棵树合并为一棵树后,使它们具有相同的分组号。因此,在树合并时,如果两棵树具有相同的分组号,表明合并后的树存在回路。
Summary:Kruskal算法主要针对图的边进行操作,因此它适用于稀疏图。
(2)陈广,《数据结构(C#语言描述)》
(3)段恩泽,《数据结构(C#语言版)》
作者:周旭龙
出处:http://edisonchou.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
一、生成树与最小生成树
1.1 生成树
对于一个无向图,含有连通图全部顶点的一个极小连通子图成为生成树(Spanning Tree)。其本质就是从连通图任一顶点出发进行遍历操作所经过的边,再加上所有顶点构成的子图。采用深度优先遍历获得的生成树称为深度优先生成树(DFS生成树),采用广度优先遍历获得的生成树称为广度优先生成树(BFS生成树)。如下图所示,无向图的DFS生成树和BFS生成树分别如图的中间和右边所示。
1.2 最小生成树
如果连通图是一个带权的网络,称该网络的所有生成树中权值综合最小的生成树为最小生成树(Minimum Spanning Tree,MST),简称MST生成树。求网络的最小生成树的重要意义就在于:假如要在n个城市之间铺设光缆,由于地理环境的不同,各个城市之间铺设光缆的费用也不同。一方面要使得这n个城市可以直接或间接通信,另一方面要考虑铺设光缆的费用最低。解决这个问题的方法就是在n个顶点(城市)和不同权值的边(这里指铺设光缆的费用)所构成的无向连通图中找出最小生成树。
二、Prim算法
2.1 算法思想
假设N=(V,{E})是连通网,TE是N上最小生成树中边的集合。算法从U={u0}(u0∈V),TE={}开始。重复执行下述操作:在所有u∈U,v∈V-U的边(u,v)∈E中找一条代价最小的边(u0,v0)并入集合TE,同时v并入U,直至U=V为止。此时TE中必有n-1条边,则T=(V,{TE})为N的最小生成树。2.2 算法实现
下面实现的Prim算法主要基于邻接矩阵来构建:#region Test03:最小生成树算法之Prim算法测试:基于邻接矩阵
static void PrimTest()
{
int[,] cost = new int[6, 6];
// 模拟图的邻接矩阵初始化
cost[0, 1] = cost[1, 0] = 6;
cost[0, 2] = cost[2, 0] = 6;
cost[0, 3] = cost[3, 0] = 1;
cost[1, 3] = cost[3, 1] = 5;
cost[2, 3] = cost[3, 2] = 5;
cost[1, 4] = cost[4, 1] = 3;
cost[3, 4] = cost[4, 3] = 6;
cost[3, 5] = cost[5, 3] = 4;
cost[4, 5] = cost[5, 4] = 6;
cost[2, 5] = cost[5, 2] = 2;
// Prim算法构造最小生成树:从顶点0开始
Console.WriteLine("Prim算法构造最小生成树:(从顶点0开始)");
double sum = 0;
Prim(cost, 0, ref sum);
Console.WriteLine("最小生成树权值和为:{0}", sum);
}
static void Prim(int[,] V, int vertex, ref double sum)
{
int length = V.GetLength(1); // 获取元素个数
int[] lowcost = new int[length]; // 待选边的权值集合V
int[] U = new int[length]; // 最终生成树值集合U
for (int i = 0; i < length; i++)
{
lowcost[i] = V[vertex, i]; // 将邻接矩阵起始点矩阵中所在行的值加入V
U[i] = vertex; // U集合中的值全为起始顶点
}
lowcost[vertex] = -1; // 起始节点标记为已使用:-1代表已使用,后续不再判断
for (int i = 1; i < length; i++)
{
int k = 0; // k标识V集合中最小值索引
int min = int.MaxValue; // 辅助变量:记录最小权值
// 下面for循环中寻找V集合中权值最小的与顶点i邻接的顶点j
for (int j = 0; j < length; j++)
{
if (lowcost[j] > 0 && lowcost[j] < min) // 寻找范围不包括0、-1以及无穷大值
{
min = lowcost[j];
k = j; // k记录最小权值索引
}
}
// 找到了并进行打印输出
Console.WriteLine("找到边({0},{1})权为:{2}", U[k], k, min);
lowcost[k] = -1; // 标志为已使用
sum += min; // 累加权值
for (int j = 0; j < length; j++)
{
// 如果集合U中有多个顶点与集合V中某一顶点存在边
// 则选取最小权值边加入lowcost集合中
if (V[k, j] != 0 && (lowcost[j] == 0 || V[k, j] < lowcost[j]))
{
lowcost[j] = V[k, j]; // 更新集合lowcost
U[j] = k; // 更新集合U
}
}
}
}
#endregion运行结果如下图所示,最小生成树的权值和为15:
Summary:Prim算法主要是对图的顶点进行操作,它适用于稠密图。
三、Kruskal算法
3.1 算法思想
Kruskal算法是一种按权值的递增顺序来选择合适的边来构造最小生成树的方法。假设N=(V,{E})是连通网,则令最小生成树的初始状态为只有n个顶点而无边的非连通图T={V,{}},图中每个顶点自成一个连通分量。在E中选择代价最小的边,若该边依附的顶点落在T中不同的连通分量上,则将此边加入到T中,否则舍去此边而选择下一条代价最小的边。依次类推,直至T中所有顶点都在同一连通分量上为止。下面是一个Kruskal算法的演示:
3.2 算法实现
(1)存放边信息的结构体:记录边的起点、终点以及权值struct Edge : IComparable
{
public int Begin; // 边的起点
public int End; // 边的终点
public int Weight; // 边的权值
public Edge(int begin, int end, int weight)
{
this.Begin = begin;
this.End = end;
this.Weight = weight;
}
public int CompareTo(object obj)
{
Edge edge = (Edge)obj;
return this.Weight.CompareTo(edge.Weight);
}
}(2)创建按权值排序的边的集合
static List<Edge> BuildEdgeList(int[,] cost)
{
int length = cost.GetLength(1);
List<Edge> edgeList = new List<Edge>(); // 边集合
for (int i = 0; i < length - 1; i++)
{
for (int j = i + 1; j < length; j++)
{
if (cost[i, j] > 0)
{
if (i < j) // 将序号较小的顶点放在前面
{
Edge newEdge = new Edge(i, j, cost[i, j]);
edgeList.Add(newEdge);
}
else
{
Edge newEdge = new Edge(j, i, cost[i, j]);
edgeList.Add(newEdge);
}
}
}
}
edgeList.Sort(); // 让各边按权值从小到大排序
return edgeList;
}(3)Kruskal核心代码:Kruskal的实现过程是将森林变成树的过程,可以给森林中的每一棵树配置一个唯一的分组号,当两棵树合并为一棵树后,使它们具有相同的分组号。因此,在树合并时,如果两棵树具有相同的分组号,表明合并后的树存在回路。
static void Kruskal(int[,] cost, int vertex, ref double sum)
{
int length = cost.GetLength(1);
List<Edge> edgeList = BuildEdgeList(cost); // 获取边的有序集合
int[] groups = new int[length]; // 存放分组号的辅助数组
for (int i = 0; i < length; i++)
{
// 辅助数组的初始化:每个顶点配置一个唯一的分组号
groups[i] = i;
}
for (int k = 1, j = 0; k < length; j++)
{
int begin = edgeList[j].Begin; // 边的起始顶点
int end = edgeList[j].End; // 边的结束顶点
int groupBegin = groups[begin]; // 起始顶点所属分组号
int groupEnd = groups[end]; // 结束顶点所属分组号
// 判断是否存在回路:通过分组号来判断->不是一个分组即不存在回路
if (groupBegin != groupEnd)
{
// 打印最小生成树边的信息
Console.WriteLine("找到边({0},{1})权值为:{2}", begin, end, edgeList[j].Weight);
sum += edgeList[j].Weight; // 权值之和累加
k++;
for (int i = 0; i < length; i++)
{
// 两棵树合并为一课后,将树的所有顶点所属分组号设为一致
if (groups[i] == groupEnd)
{
groups[i] = groupBegin;
}
}
}
}
}Summary:Kruskal算法主要针对图的边进行操作,因此它适用于稀疏图。
参考资料
(1)程杰,《大话数据结构》(2)陈广,《数据结构(C#语言描述)》
(3)段恩泽,《数据结构(C#语言版)》
作者:周旭龙
出处:http://edisonchou.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。

相关文章推荐
- 数据结构和算法学习笔记-2
- 数据结构之双向链表(JAVA实现)
- 数据结构---二叉树(1)
- 数据结构实验之队列一:排队买饭 SDUT
- HDU 5316 Magician(线段树区间合并入门)
- 黑马程序员——高新技术---Java基础-集合特点和数据结构总结
- 数据结构实验之二叉树的建立与遍历 SDUT
- 数据结构实验:连通分量个数
- HDU 1277 - 全文检索
- 进程01
- 数据结构和算法学习笔记-1
- 数据结构与算法学习目录
- java数据结构
- 数据结构实验之栈二:一般算术表达式转换成后缀式 SDUT
- 数据结构与算法-抽象数据类型
- 数据结构与算法-抽象数据类型
- 步步为营(十四)常用数据结构(7)STL-Queue(队列)priority_queue(优先队列)
- 我的软考之路(四)——数据结构和算法(2)树和二叉树
- caffe study - 数据结构(1)
- 步步为营(十三)常用数据结构(6)STL-Stack(栈)