跳跃表(skip list) 的实现
2014-06-02 17:05
302 查看
Skip List是一种随机化的数据结构,基于并联的链表,其效率可比拟于二叉查找树(对于大多数操作需要O(log n)平均时间)。基本上,跳跃列表是对有序的链表增加上附加的前进链接,增加是以随机化的方式进行的,所以在列表中的查找可以快速的跳过部分列表(因此得名)。所有操作都以对数随机化的时间进行。Skip List可以很好解决有序链表查找特定值的困难。
Skip List 定义以及构造步骤
Skip List定义
像下面这样(初中物理经常这样用,这里我也盗用下):
一个跳表,应该具有以下特征:
一个跳表应该有几个层(level)组成;
跳表的第一层包含所有的元素;
每一层都是一个有序的链表;
如果元素x出现在第i层,则所有比i小的层都包含x;
第i层的元素通过一个down指针指向下一层拥有相同值的元素;
在每一层中,-1和1两个元素都出现(分别表示INT_MIN和INT_MAX);
Top指针指向最高层的第一个元素。
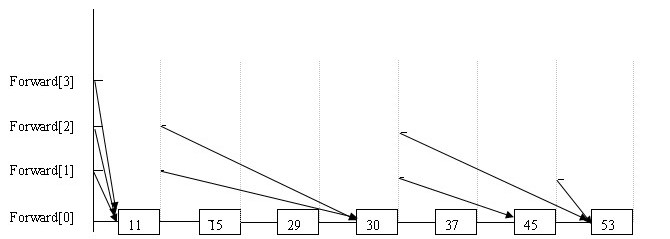
构建有序链表

的一个跳跃表如下:
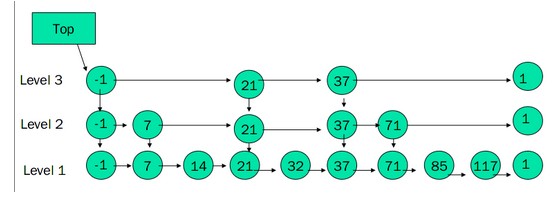
Skip List构造步骤:
1、给定一个有序的链表。
2、选择连表中最大和最小的元素,然后从其他元素中按照一定算法(随机)随即选出一些元素,将这些元素组成有序链表。这个新的链表称为一层,原链表称为其下一层。
3、为刚选出的每个元素添加一个指针域,这个指针指向下一层中值同自己相等的元素。Top指针指向该层首元素
4、重复2、3步,直到不再能选择出除最大最小元素以外的元素。
一、查找
目的:在跳跃表中查找一个元素x
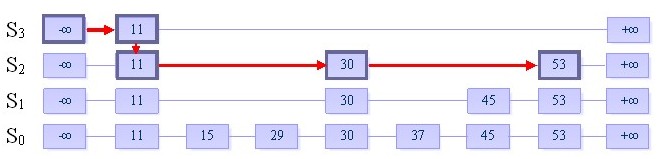
在跳跃表中查找一个元素x,按照如下几个步骤进行:
1. 从最上层的链(Sh)的开头开始
2. 假设当前位置为p,它向右指向的节点为q(p与q不一定相邻),且q的值为y。将y与x作比较
(1) x=y 输出查询成功及相关信息
(2) x>y 从p向右移动到q的位置
(3) x<y 从p向下移动一格
3. 如果当前位置在最底层的链中(S0),且还要往下移动的话,则输出查询失败
二、插入
目的:向跳跃表中插入一个元素x
首先明确,向跳跃表中插入一个元素,相当于在表中插入一列从S0中某一位置出发向上的连续一段元素。有两个参数需要确定,即插入列的位置以及它的“高度”。
关于插入的位置,我们先利用跳跃表的查找功能,找到比x小的最大的数y。根据跳跃表中所有链均是递增序列的原则,x必然就插在y的后面。
而插入列的“高度”较前者来说显得更加重要,也更加难以确定。由于它的不确定性,使得不同的决策可能会导致截然不同的算法效率。为了使插入数据之后,保持该数据结构进行各种操作均为O(logn)复杂度的性质,我们引入随机化算法(Randomized Algorithms)。
我们定义一个随机决策模块,它的大致内容如下:
产生一个0到1的随机数r r ← random()
如果r小于一个常数p,则执行方案A, if r<p then do A
否则,执行方案B else do B
初始时列高为1。插入元素时,不停地执行随机决策模块。如果要求执行的是A操作,则将列的高度加1,并且继续反复执行随机决策模块。直到第i次,模块要求执行的是B操作,我们结束决策,并向跳跃表中插入一个高度为i的列。
我们来看一个例子:
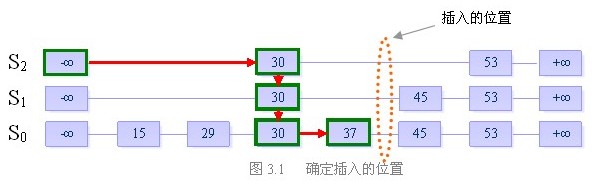
假设当前我们要插入元素“40”,且在执行了随机决策模块后得到高度为4
步骤一:找到表中比40小的最大的数,确定插入位置
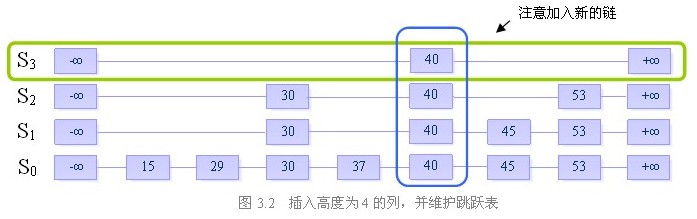
步骤二:插入高度为4的列,并维护跳跃表的结构
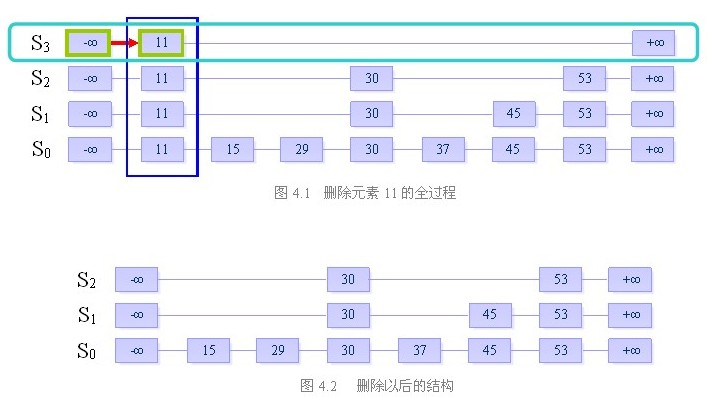
三、删除
目的:从跳跃表中删除一个元素x
删除操作分为以下三个步骤:
在跳跃表中查找到这个元素的位置,如果未找到,则退出
将该元素所在整列从表中删除
将多余的“空链”删除
§3 Skip List
完整实现
更多请参考:
点击打开链接
点击打开链接
Skip List 定义以及构造步骤
Skip List定义
像下面这样(初中物理经常这样用,这里我也盗用下):
一个跳表,应该具有以下特征:
一个跳表应该有几个层(level)组成;
跳表的第一层包含所有的元素;
每一层都是一个有序的链表;
如果元素x出现在第i层,则所有比i小的层都包含x;
第i层的元素通过一个down指针指向下一层拥有相同值的元素;
在每一层中,-1和1两个元素都出现(分别表示INT_MIN和INT_MAX);
Top指针指向最高层的第一个元素。
构建有序链表
的一个跳跃表如下:
Skip List构造步骤:
1、给定一个有序的链表。
2、选择连表中最大和最小的元素,然后从其他元素中按照一定算法(随机)随即选出一些元素,将这些元素组成有序链表。这个新的链表称为一层,原链表称为其下一层。
3、为刚选出的每个元素添加一个指针域,这个指针指向下一层中值同自己相等的元素。Top指针指向该层首元素
4、重复2、3步,直到不再能选择出除最大最小元素以外的元素。
一、查找
目的:在跳跃表中查找一个元素x
在跳跃表中查找一个元素x,按照如下几个步骤进行:
1. 从最上层的链(Sh)的开头开始
2. 假设当前位置为p,它向右指向的节点为q(p与q不一定相邻),且q的值为y。将y与x作比较
(1) x=y 输出查询成功及相关信息
(2) x>y 从p向右移动到q的位置
(3) x<y 从p向下移动一格
3. 如果当前位置在最底层的链中(S0),且还要往下移动的话,则输出查询失败
二、插入
目的:向跳跃表中插入一个元素x
首先明确,向跳跃表中插入一个元素,相当于在表中插入一列从S0中某一位置出发向上的连续一段元素。有两个参数需要确定,即插入列的位置以及它的“高度”。
关于插入的位置,我们先利用跳跃表的查找功能,找到比x小的最大的数y。根据跳跃表中所有链均是递增序列的原则,x必然就插在y的后面。
而插入列的“高度”较前者来说显得更加重要,也更加难以确定。由于它的不确定性,使得不同的决策可能会导致截然不同的算法效率。为了使插入数据之后,保持该数据结构进行各种操作均为O(logn)复杂度的性质,我们引入随机化算法(Randomized Algorithms)。
我们定义一个随机决策模块,它的大致内容如下:
产生一个0到1的随机数r r ← random()
如果r小于一个常数p,则执行方案A, if r<p then do A
否则,执行方案B else do B
初始时列高为1。插入元素时,不停地执行随机决策模块。如果要求执行的是A操作,则将列的高度加1,并且继续反复执行随机决策模块。直到第i次,模块要求执行的是B操作,我们结束决策,并向跳跃表中插入一个高度为i的列。
我们来看一个例子:
假设当前我们要插入元素“40”,且在执行了随机决策模块后得到高度为4
步骤一:找到表中比40小的最大的数,确定插入位置
步骤二:插入高度为4的列,并维护跳跃表的结构
三、删除
目的:从跳跃表中删除一个元素x
删除操作分为以下三个步骤:
在跳跃表中查找到这个元素的位置,如果未找到,则退出
将该元素所在整列从表中删除
将多余的“空链”删除
§3 Skip List
完整实现
// myskiplist.cpp an implemention of skip list written in c++
#include <iostream>
#include <cstring> // to get the declaration of function memset
#include <cmath>
#include <cstdlib>
#include <ctime>
using namespace std;
const float P = 0.5; //随机数产生概率
const int MAX_LEVEL = 4; //最大层数
float frand();
int randomLevel(); //产生一个随机层数
//Definition of node 节点
template<class T>
struct snode
{
T value;
snode<T>** fwd; //array of pointers 指向snode的指针数组
snode(int level,const T& value = T())
{
//在0层的节点有一个前项指针,1层节点有两个前项指针,依次类推
//因此在level层分配指向前项的指针数组的个数应该是level+1
fwd = new snode<T>* [MAX_LEVEL + 1];
//fwd指针数组中的所有指针初始化为NULL
memset(fwd, 0, sizeof(snode<T>*) * (MAX_LEVEL + 1));
this->value = value;
}
// Destructor
~snode()
{
delete [] fwd;
}
};
// Definition of class skiplist跳表
template <class T>
class skiplist
{
public:
int level; //跳表有多少层
snode<T> * head; //指向表头的指针
skiplist()
{
head = new snode<T>(MAX_LEVEL, T());
level = 0;
}
// Destructor
~skiplist()
{
delete head;
}
void print() const;
bool empty() const;
bool contains(const T& val) const;
void insert(const T& val);
void erase(const T& val);
};
//打印表内容
//print the contents of a skiplist to the console
//This function simply traverses the level 0 pointers
//and visits every node while printing out the values.
template<class T>
void skiplist<T>::print() const
{
const snode<T>* p = head->fwd[0];
cout << "{";
while (p != NULL) {
cout << p->value;
p = p->fwd[0];
if (p != NULL) {
cout << ",";
}
}
cout << "}\n";
}
//判断表是否为空表
// Return true if skiplist is empty, otherwise return false
template<class T>
bool skiplist<T>::empty()const
{
return head->fwd[0] == NULL;
}
//搜索指定的值val
// Return true if val is in the list, else return false
template<class T>
bool skiplist<T>::contains(const T& val) const
{
snode<T>* p = head;
for (int i = level; i >= 0; i--) {
while (p->fwd[i] != NULL && p->fwd[i]->value < val) {
p = p->fwd[i];
}
}
p = p->fwd[0];
/*
*p 的值有三种可能
*1, p指向的节点的元素值等于搜索元素val
*2, p指向的节点的元素值大于所查找的元素val
*3, p的值位NULL
*/
return p != NULL && p->value == val;
}
//向表中插入一个元素
// Insert an element into list
template<class T>
void skiplist<T>::insert(const T& val)
{
snode<T>* p = head;
snode<T>* update[MAX_LEVEL + 1]; //update用来保存插入或者删除元素时,每层该元素前驱项的位置
//update数组中的所有指针必须初始化为NULL
memset(update, 0, sizeof(snode<T>*) * (MAX_LEVEL + 1)); //We need string.h for memset
//从上到下查找可以插入的位置将可以
//插入位置的前一个位置保存到update数组中
for (int i = level; i >= 0; i--) {
while (p->fwd[i] != NULL && p->fwd[i]->value < val) {
p = p->fwd[i];
}
update[i] = p;
}
p = p->fwd[0];
//如果是空表或者搜索值不在表中才将元素插入
//如果元素val已经存在,什么都不做(不能有重复项)
if (p == NULL || p->value != val) {
//产生一个随机层数randlevel
int randlevel = randomLevel();
//如果插入的层比当前表的层高则要更新相关的upate和level
if (level < randlevel) {
for (int i = level + 1; i <= randlevel; i++) {
update[i] = head;
}
level = randlevel;
}
//产生一个新的待插入节点
p = new snode<T>(randlevel, val);
//从下到上一层层插入新节点
//逐层更新节点的指针
for (int i = 0; i <= randlevel; i++) {
p->fwd[i] = update[i]->fwd[i];
update[i]->fwd[i] = p;
}
}
}
// Delete an element from list
template<class T>
void skiplist<T>::erase(const T& val)
{
//表不能为空
if(empty()) {
cout << "Failed: empty list" << endl;
exit(1);
}
snode<T>* p = head;
snode<T>* update[MAX_LEVEL + 1];
memset(update, 0, sizeof(snode<T>*) * (MAX_LEVEL + 1));
for (int i = level; i >= 0; i--) {
while (p->fwd[i] != NULL && p->fwd[i]->value < val) {
p = p->fwd[i];
}
update[i] = p;
}
p = p->fwd[0];
if (p->value == val) {
//修改将被删除节点的前趋节点的指针
for (int i = 0; i <= level; i++) {
if (update[i]->fwd[i] != p)
break;
update[i]->fwd[i] = p->fwd[i];
}
delete p;
//删除一个节点后必须要检查是否要减少list的level值
while(level > 0 && head->fwd[level] == NULL) {
level--;
}
}
}
//随机数产生器,产生一个在0 到1 之间的随机数
float frand()
{
return (float)rand() / RAND_MAX;
}
//随机产生节点所在的层
int randomLevel()
{
static bool first = true;
int k = 1;
while(first) {
srand((unsigned)time(NULL));
first = false;
}
while(frand() < P) {
k++;
}
return k < MAX_LEVEL ? k : MAX_LEVEL;
}
// 建立一个skiplist 并做测试
int main()
{
skiplist<int> sl;
if (sl.empty()) {
cout << "The list is empty" << endl;
}
sl.print();
sl.insert(5);
sl.insert(3);
sl.insert(7);
sl.insert(7);
sl.insert(6);
sl.print();
if (sl.contains(6)) {
cout << "6 is in the list\n";
}
sl.erase(7);
sl.print();
if (!sl.contains(7)) {
cout << "7 has been deleted\n";
}
return 0;
}更多请参考:
点击打开链接
点击打开链接

相关文章推荐
- Skip List(跳跃表)原理详解与实现
- Java实现跳跃表(skiplist)的简单实例
- Skip List(跳跃表)原理详解与实现【转】
- 跳跃表SkipList原理代码实现
- 跳跃表(Skip List)-实现(Java)
- 结合redis设计与实现的redis源码学习-5-skiplist(跳跃表)
- skiplist 跳跃表详解及其编程实现
- 【转】浅析SkipList跳跃表原理及代码实现
- 【算法导论33】跳跃表(Skip list)原理与java实现
- 【算法导论33】跳跃表(Skip list)原理与java实现
- SkipList跳跃表(Java实现)
- 浅析SkipList跳跃表原理及代码实现
- Skip list -- 跳跃表的插入删除搜索等ADT操作的实现与测试
- 跳跃表(skiplist)实现及简单分析
- Skip List(跳跃表)原理详解与实现
- 算法: skiplist 跳跃表代码实现和原理
- 跳跃表(skip list)基本原理及C/C++实现
- Skip List(跳跃表)原理详解与实现
- Skip List(跳跃表)原理详解与实现
- Skip List跳跃表代码实现