一条统计Group By语句优化
2014-02-17 11:42
211 查看
在检查慢SQL时,发现一条统计SQL执行过慢,如下:
| SELECT platform, channel, COUNT(DISTINCT(platformUserId)) as cnt FROM( SELECT platform, channel, platformUserId, MIN(insertTimestamp) as rtime FROM tsz_user GROUP BY platform, channel, platformUserId ) a where a.rtime >= 1392393600 and a.rtime < 1392480000 GROUP BY platform, channel; |
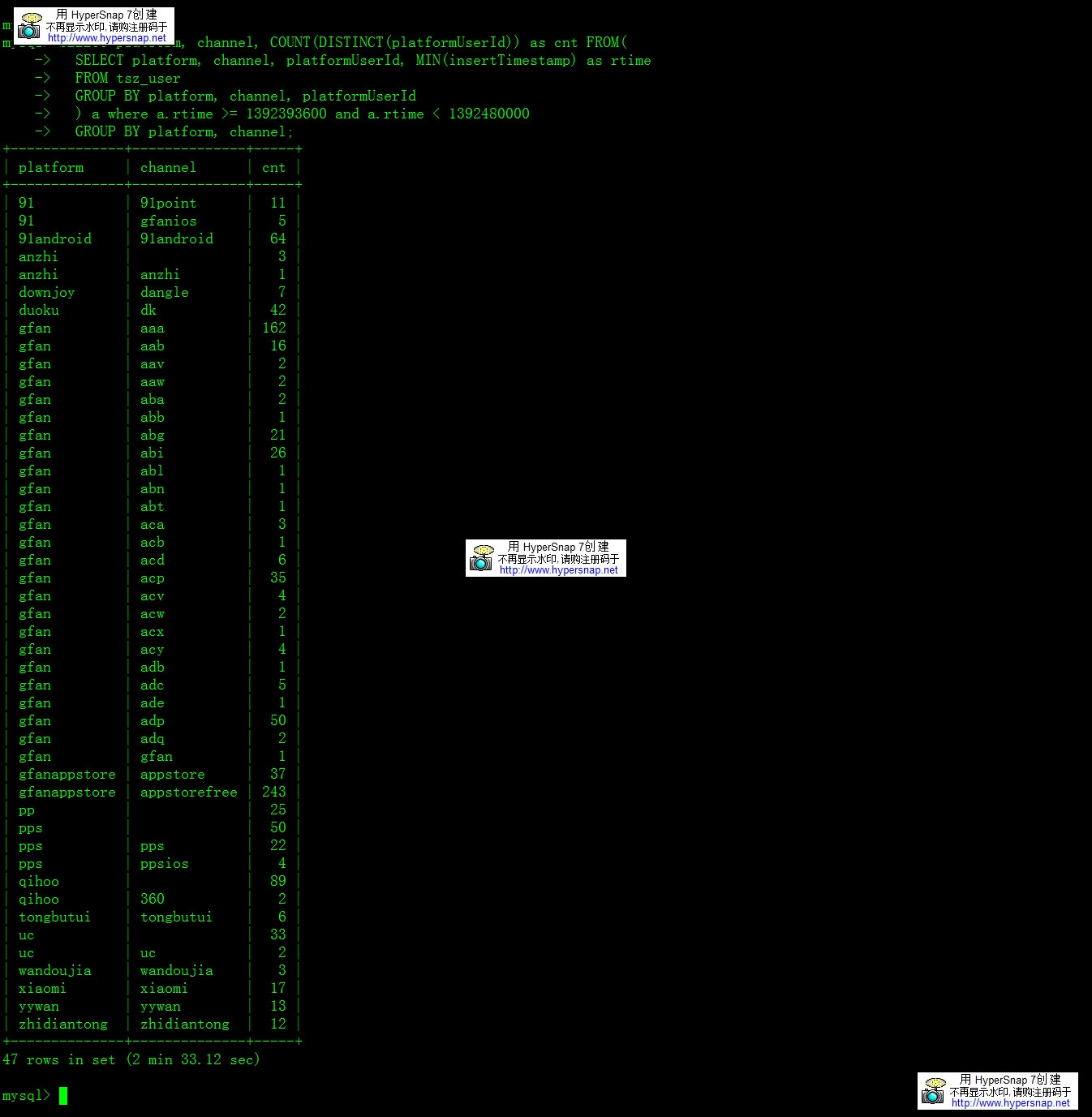
耗时2分33秒
| SELECT platform, channel, COUNT(DISTINCT(platformUserId)) as cnt FROM( SELECT platform, channel, platformUserId, MIN(insertTimestamp) as rtime FROM tsz_user GROUP BY platform, channel, platformUserId order by null ) a where a.rtime >= 1392393600 and a.rtime < 1392480000 GROUP BY platform, channel order by null; |
执行时间:
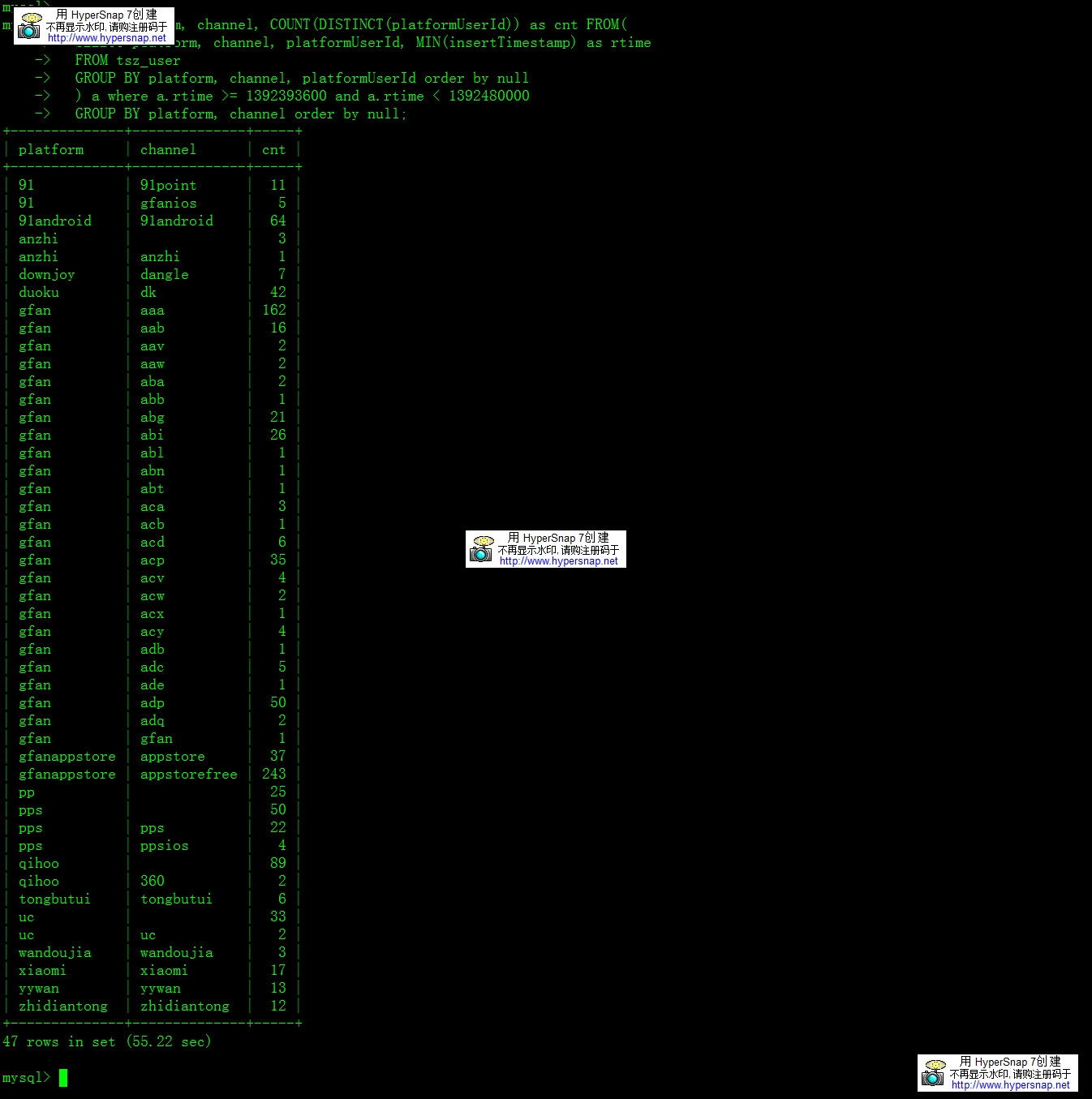
耗时55.22秒
执行计划:
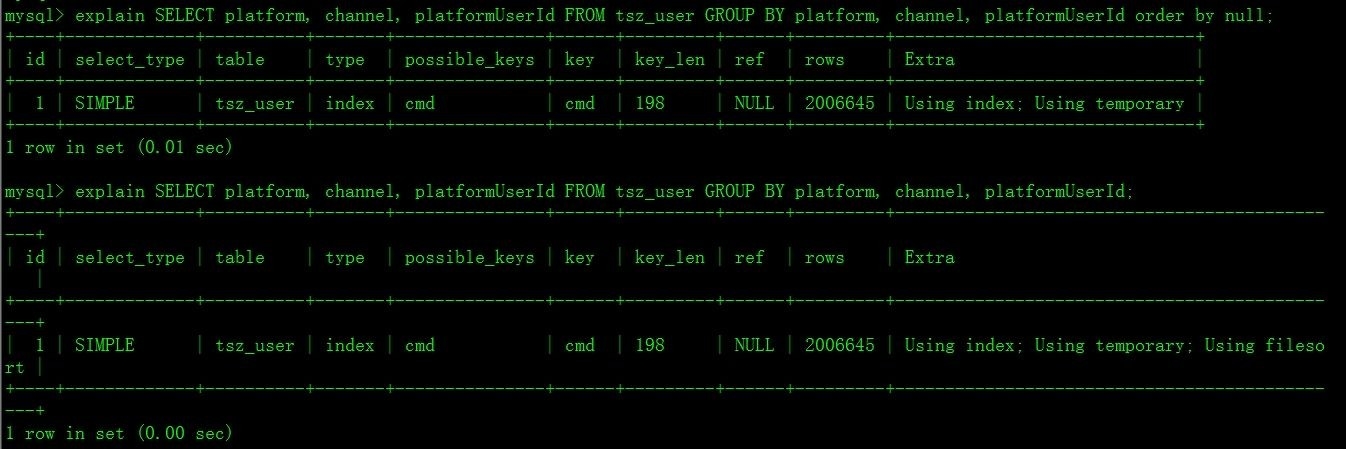
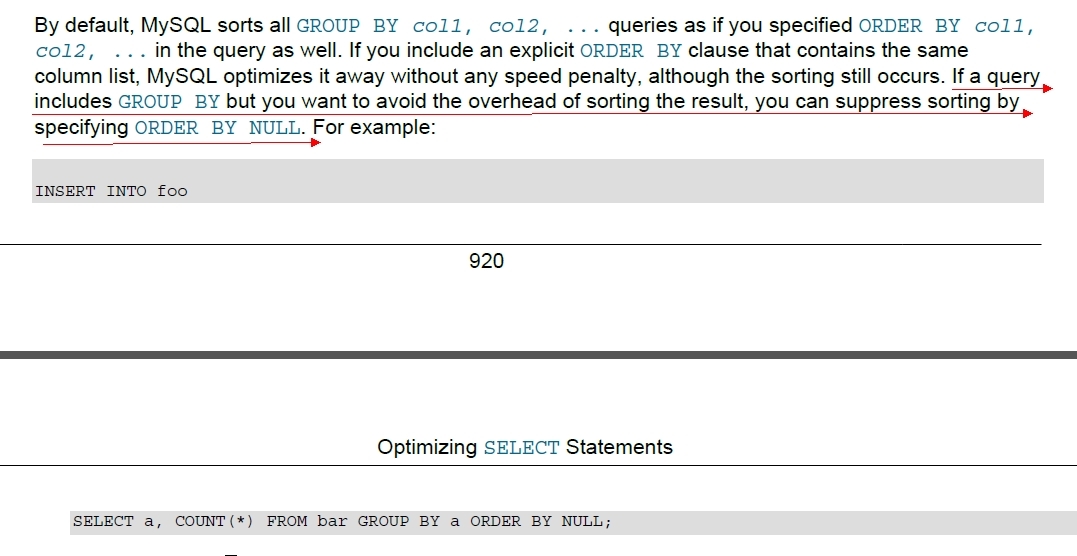
参考手册:

相关文章推荐
- 一条统计Group By语句优化
- 一条统计Group By语句优化
- 对Group By 语句的一次优化过程
- 一条SQL语句的优化学习
- 一条SQL语句统计两个表的记录数
- sql语句优化及后一条减前一条
- SQL一条语句统计记录总数及各状态数
- Oracle下一条SQL语句的优化
- oracle下一条SQL语句的优化过程(比较详细)
- 每天进步一点点——优化GROUP BY、or、和嵌套语句
- 简单LinuxC程序关于实现从终端获取一条语句并统计各种字符数量(字符输入输出)
- 一条Sql查询语句的优化
- 一个 Sql语句优化的问题- STATISTICS 统计信息
- 怎样一条SQL语句统计该年每月的数据个数
- 数据统计分析时常用sql语句 (split , row_number , group by, max 等 )
- SQL SERVER查询优化工具:统计SQL语句执行时间
- 一次ORA-4030问题诊断及解决【解决思路不错,说明了对象的统计信息与优化器的优化操作(即选择执行一个SQL语句在该优化参数环境下最佳的执行计划)间的关系】
- 记一条distinct 语句的优化。
- 对Group By 语句的一次优化过程
- 含join,order by,group by的复杂语句优化