一条统计Group By语句优化
2014-02-17 11:42
176 查看
在检查慢SQL时,发现一条统计SQL执行过慢,如下:
原SQL
执行时间:
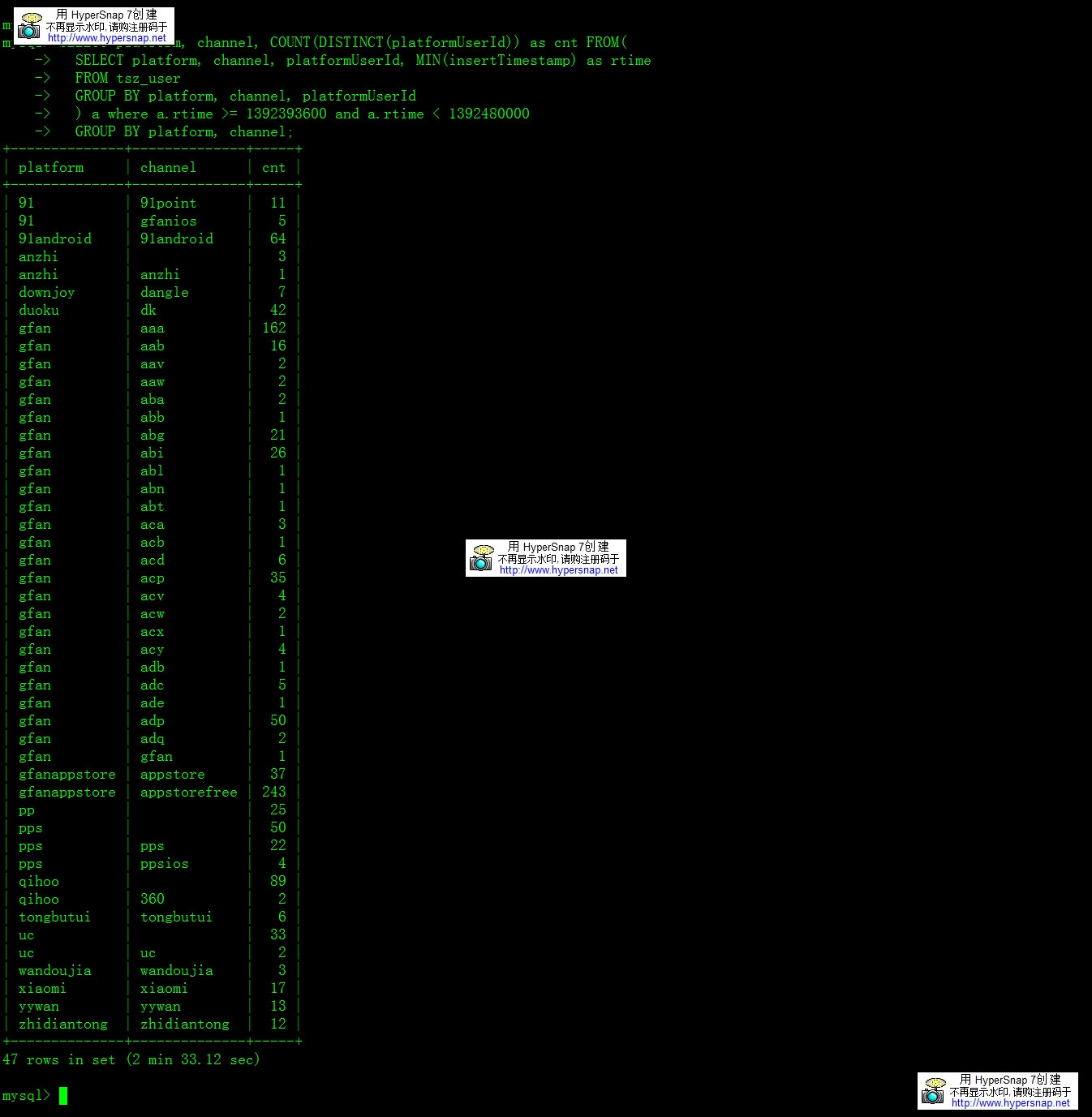
耗时2分33秒
优化后SQL
执行时间:
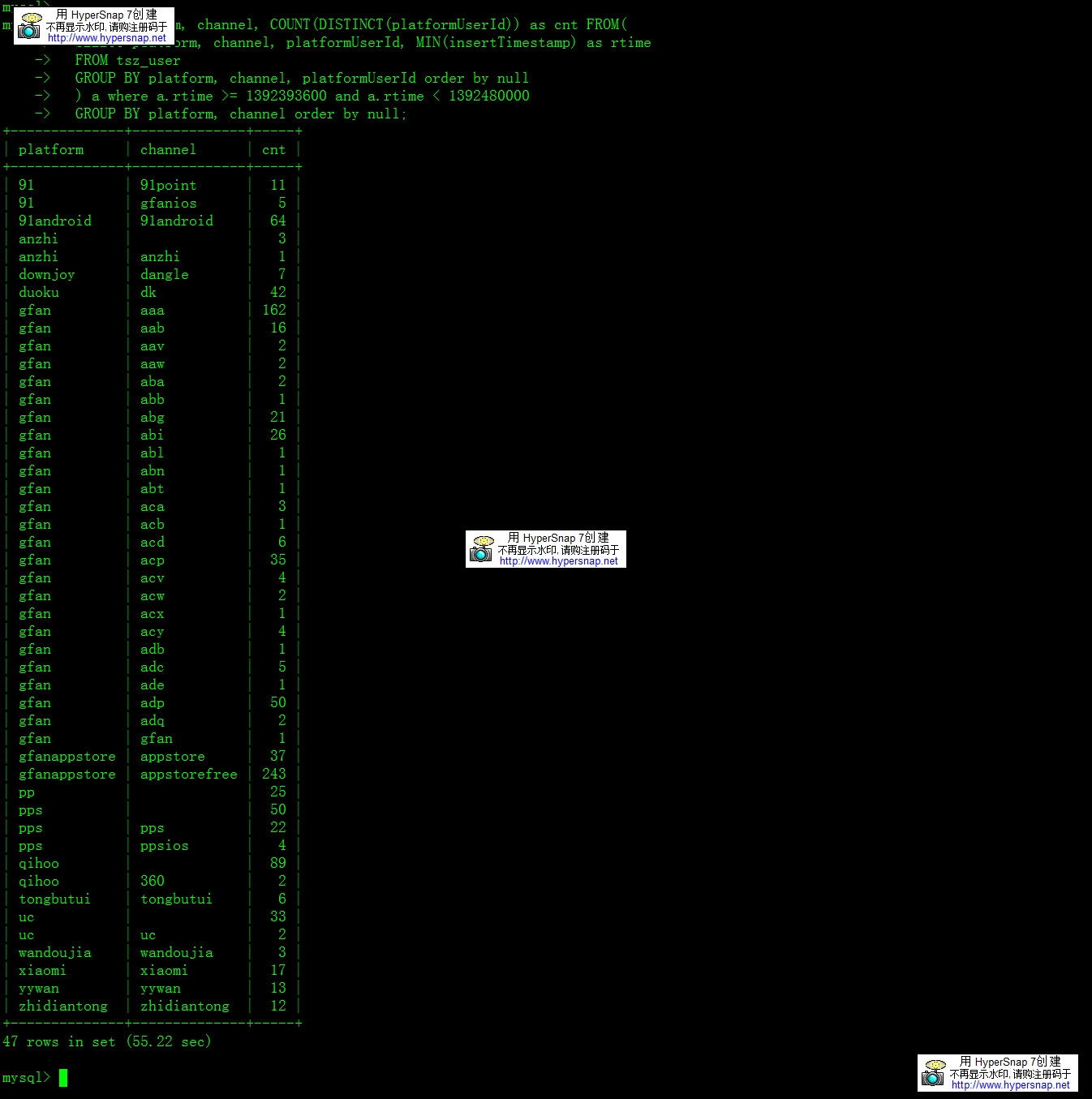
耗时55.22秒
执行计划:
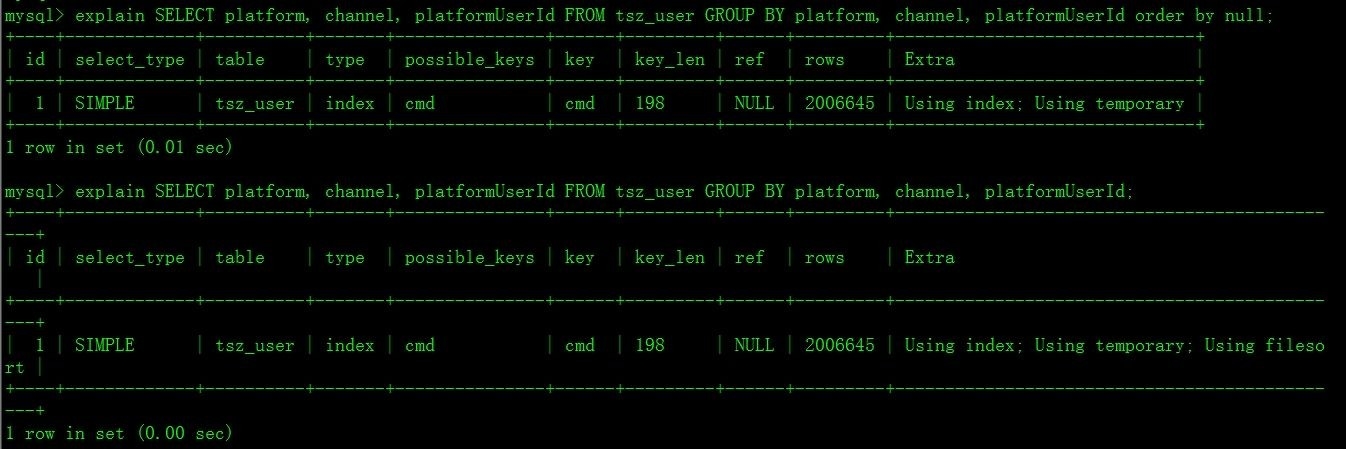
结论:默认情况下,MySQL对所有GROUP BY col1,col2...的字段进行排序。如果查询包括GROUP BY,想要避免排序结果的消耗,则可以指定ORDER By NULL禁止排序。
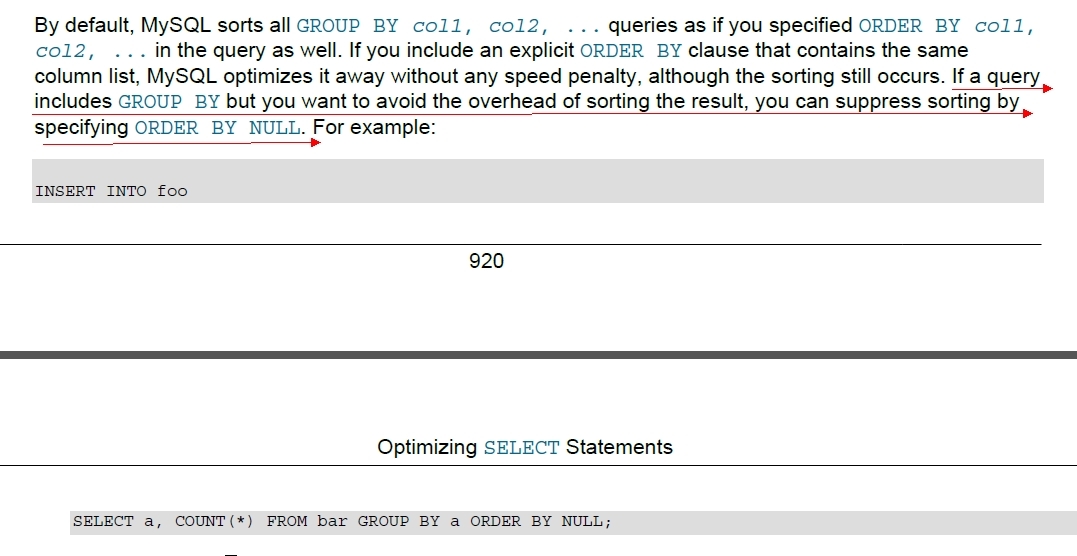
参考手册:
本文出自 “贺春旸的技术专栏” 博客,请务必保留此出处http://hcymysql.blog.51cto.com/5223301/1359738
原SQL
| SELECT platform, channel, COUNT(DISTINCT(platformUserId)) as cnt FROM( SELECT platform, channel, platformUserId, MIN(insertTimestamp) as rtime FROM tsz_user GROUP BY platform, channel, platformUserId ) a where a.rtime >= 1392393600 and a.rtime < 1392480000 GROUP BY platform, channel; |
耗时2分33秒
优化后SQL
| SELECT platform, channel, COUNT(DISTINCT(platformUserId)) as cnt FROM( SELECT platform, channel, platformUserId, MIN(insertTimestamp) as rtime FROM tsz_user GROUP BY platform, channel, platformUserId order by null ) a where a.rtime >= 1392393600 and a.rtime < 1392480000 GROUP BY platform, channel order by null; |
耗时55.22秒
执行计划:
结论:默认情况下,MySQL对所有GROUP BY col1,col2...的字段进行排序。如果查询包括GROUP BY,想要避免排序结果的消耗,则可以指定ORDER By NULL禁止排序。
参考手册:
本文出自 “贺春旸的技术专栏” 博客,请务必保留此出处http://hcymysql.blog.51cto.com/5223301/1359738

相关文章推荐
- dede:arclist 标签排序具体实现
- Ubuntu下VIM设置高亮、行号、缩进
- js 取当前时间的整数
- 互联网创业公司融资、产品、运营快速迭代和人才模式总结
- mutex 和 spinlock 对比
- 头部下拉/底部上拉 自动刷新、自定义ListView组件
- C函数可变参数
- iOS开发中TableView的嵌套使用
- spring 需要导入的jar
- PowerDesigner版本控制 留着
- android面试题及答案(三)
- 产品快速迭代的五大要点
- 获取通讯录
- easyui 组件的适应
- Spring Security 3 (二) 初识SS3
- 对于UIToolbar,UINavigationBar,UITabBar,UIBarButtonItem,UITabBarItem这几种控件的自定义
- vector<int> 转换为 int*
- 友盟开发者中心
- hdu 1171 Big Event in HDU
- CCControlButton的用法