极大似然和最小平方误差等价关系
2013-10-04 16:12
435 查看
看了一下机器学习这一节,感觉有点乱,人生观乱了,原来如此。建议本文与贝叶斯一起看。
我们设想一个问题如下:学习器工作在X的实例空间和假设空间H,我们现在的任务就是根据实例空间X,然后在H空间中学习出h满足:y = h(x)。现在我们给出了训练样集D,但是D含有随机噪声,而且此噪声服从高斯分布。即满足:

根据贝叶斯理论,我们可以利用先验概率去估计后验概率p(h|d),就是利用观察的结果得到一些先验概率去估计h。假设H空间中含有(h1,h2,h3…..,hn),那么最大后验概率估计的思想,当hi满足p(hi|d)有最大的后验概率,我们就能得出hi就是我们估计的结果。下面推导一下:

【注】MAP最大后验概率的意思
上面这个公式的意思就是说p(hi|d)达到最大时等价于p(d|hi)达到最大,这就是最大似然估计(maximum likelihood)。对于连续的变量我们用概率密度来刻画。

由于误差服从正态分布,结合di = h(xi) + ei,那么有如下推导:

上面这个式子,m表示m个训练样例,这样我们对上面的公式取对数(常用),就可以得到:

等价于
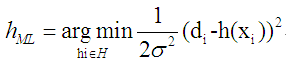
这正好就是说明,当hi-di的误差达到最小时,则hi就是我们学习到的结果。即最小平方误差的学习(梯度下降)就是最大似然估计,该结论成立的前提是di
= h(xi)+ei,ei一定是高斯误差。
最小平方误差用于神经网络权重学习,线性回归以及多项式拟合以及曲线逼近。
我们设想一个问题如下:学习器工作在X的实例空间和假设空间H,我们现在的任务就是根据实例空间X,然后在H空间中学习出h满足:y = h(x)。现在我们给出了训练样集D,但是D含有随机噪声,而且此噪声服从高斯分布。即满足:
根据贝叶斯理论,我们可以利用先验概率去估计后验概率p(h|d),就是利用观察的结果得到一些先验概率去估计h。假设H空间中含有(h1,h2,h3…..,hn),那么最大后验概率估计的思想,当hi满足p(hi|d)有最大的后验概率,我们就能得出hi就是我们估计的结果。下面推导一下:
【注】MAP最大后验概率的意思
上面这个公式的意思就是说p(hi|d)达到最大时等价于p(d|hi)达到最大,这就是最大似然估计(maximum likelihood)。对于连续的变量我们用概率密度来刻画。
由于误差服从正态分布,结合di = h(xi) + ei,那么有如下推导:
上面这个式子,m表示m个训练样例,这样我们对上面的公式取对数(常用),就可以得到:
等价于
这正好就是说明,当hi-di的误差达到最小时,则hi就是我们学习到的结果。即最小平方误差的学习(梯度下降)就是最大似然估计,该结论成立的前提是di
= h(xi)+ei,ei一定是高斯误差。
最小平方误差用于神经网络权重学习,线性回归以及多项式拟合以及曲线逼近。

相关文章推荐
- 极大似然与极小化经验误差的等价关系证明
- 逻辑回归、线性回归、最小二乘、极大似然、梯度下降
- 机器学习中的玻尔兹曼分布——最小代价和极大似然
- 最小二乘 极大似然 为什么最小二乘法对误差的估计要用平方
- 最小二乘、极大似然、梯度下降有何区别
- 最小二乘与最大似然估计之间的关系
- 最小二乘法的极大似然解释
- 最小二乘、极大似然、梯度下降法
- 极大似然的估计的理解
- 2013年通化邀请赛E题(GCD and LCM 最大公约数最小公倍数关系 )
- 主成分分析(PCA)最大方差解释最小平方误差解释
- C++编写二元关系等价及其商集
- 离散数学 03.03 谓词公式的等价关系和蕴涵关系
- 雅克比矩阵、海森矩阵与非线性最小二乘间的关系与在SFM和Pose Estimation中的应用
- 先验概率 后验概率 似然 极大似然估计 极大后验估计 共轭 概念
- 最小二乘的概率解释(最大似然)
- 最小割之二元关系 小结
- 雅克比矩阵、海森矩阵与非线性最小二乘间的关系与在SFM和Pose Estimation中的应用
- 问题:向量值极大函数的界与维数的关系
- 数据类型最大值与最小值之间的关系