Linux内核--网络栈实现分析(四)--网络层之IP协议(上)
2012-04-28 13:06
525 查看
本文分析基于Linux Kernel 1.2.13
原创作品,转载请标明http://blog.csdn.net/yming0221/article/details/7514017
更多请看专栏,地址http://blog.csdn.net/column/details/linux-kernel-net.html
作者:闫明
注:标题中的”(上)“,”(下)“表示分析过程基于数据包的传递方向:”(上)“表示分析是从底层向上分析、”(下)“表示分析是从上向下分析。
简单分析了链路层之后,上升到网络层来分析,看看链路层是如何为其上层--网络层服务的。其实在驱动程序层和网络层直接还有一层是接口层,叫做驱动程序接口层,用来整合不同的网络设备。接口层的内容会在上下层中提及。这里我们分析网络IP协议的实现原理。
其实现的文件主要是net/inet/ip.c文件中
我们首先分析下ip_init()初始化函数
这个函数是如何被调用的呢?
下面是调用的过程:
首先是在系统启动过程main.c中调用了sock_init()函数
void sock_init(void)//网络栈初始化
{
int i;
printk("Swansea University Computer Society NET3.019\n");
/*
* Initialize all address (protocol) families.
*/
for (i = 0; i < NPROTO; ++i) pops[i] = NULL;
/*
* Initialize the protocols module.
*/
proto_init();
#ifdef CONFIG_NET
/*
* Initialize the DEV module.
*/
dev_init();
/*
* And the bottom half handler
*/
bh_base[NET_BH].routine= net_bh;//设置NET 下半部分的处理函数为net_bh
enable_bh(NET_BH);
#endif
}
然后调用了proto_init()函数
void proto_init(void)
{
extern struct net_proto protocols[]; /* Network protocols 全局变量,定义在protocols.c中*/
struct net_proto *pro;
/* Kick all configured protocols. */
pro = protocols;
while (pro->name != NULL) //对所有的定义的域进行初始化
{
(*pro->init_func)(pro);
pro++;
}
/* We're all done... */
}
而protocols全局变量协议向量表的定义中对INET域中协议的初始化函数设置为inet_proto_init()
/*
* Protocol Table
*/
struct net_proto protocols[] = {
#ifdef CONFIG_UNIX
{ "UNIX", unix_proto_init },
#endif
#if defined(CONFIG_IPX)||defined(CONFIG_ATALK)
{ "802.2", p8022_proto_init },
{ "SNAP", snap_proto_init },
#endif
#ifdef CONFIG_AX25
{ "AX.25", ax25_proto_init },
#endif
#ifdef CONFIG_INET
{ "INET", inet_proto_init },
#endif
#ifdef CONFIG_IPX
{ "IPX", ipx_proto_init },
#endif
#ifdef CONFIG_ATALK
{ "DDP", atalk_proto_init },
#endif
{ NULL, NULL }
};
看到在inet_proto_init()函数中调用了ip_init()对IP层进行了初始化。
void inet_proto_init(struct net_proto *pro)//INET域协议初始化函数
{
struct inet_protocol *p;
int i;
printk("Swansea University Computer Society TCP/IP for NET3.019\n");
/*
* Tell SOCKET that we are alive...
*/
(void) sock_register(inet_proto_ops.family, &inet_proto_ops);
...........................................
printk("IP Protocols: ");
for(p = inet_protocol_base; p != NULL;) //将inet_protocol_base指向的一个inet_protocol结构体加入数组inet_protos中
{
struct inet_protocol *tmp = (struct inet_protocol *) p->next;
inet_add_protocol(p);
printk("%s%s",p->name,tmp?", ":"\n");
p = tmp;
}
/*
* Set the ARP module up
*/
arp_init();//对地址解析层进行初始化
/*
* Set the IP module up
*/
ip_init();//对IP层进行初始化
}代码中inet_protocol_base指向的链表为&igmp_protocol-->&icmp_protocol-->&udp_protocol-->&tcp_protocol-->NULL(定义在protocol.c中)
分析ip_init()函数需要先要知道packet_type结构,这个结构体是网络层协议的结构体,网络层协议与该结构体一一对应。
/*该结构用于表示网络层协议,网络层协议与packt_type一一对应*/
struct packet_type {
unsigned short type; /* This is really htons(ether_type). ,对应的网络层协议编号*/
struct device * dev;
int (*func) (struct sk_buff *, struct device *,
struct packet_type *);
void *data;
struct packet_type *next;
};第一个字段的网络层协议编号定义在include/linux/if_ether.h中
/* These are the defined Ethernet Protocol ID's. */
#define ETH_P_LOOP 0x0060 /* Ethernet Loopback packet */
#define ETH_P_ECHO 0x0200 /* Ethernet Echo packet */
#define ETH_P_PUP 0x0400 /* Xerox PUP packet */
#define ETH_P_IP 0x0800 /* Internet Protocol packet */
#define ETH_P_ARP 0x0806 /* Address Resolution packet */
#define ETH_P_RARP 0x8035 /* Reverse Addr Res packet */
#define ETH_P_X25 0x0805 /* CCITT X.25 */
#define ETH_P_ATALK 0x809B /* Appletalk DDP */
#define ETH_P_IPX 0x8137 /* IPX over DIX */
#define ETH_P_802_3 0x0001 /* Dummy type for 802.3 frames */
#define ETH_P_AX25 0x0002 /* Dummy protocol id for AX.25 */
#define ETH_P_ALL 0x0003 /* Every packet (be careful!!!) */
#define ETH_P_802_2 0x0004 /* 802.2 frames */
#define ETH_P_SNAP 0x0005 /* Internal only */
第二个字段表示处理包的网络接口设备,一般初始化为NULL。
第三个字段为相应网络协议的处理函数。
第四个字段是一个void指针。
第五个字段是next指针域,用于将该结构连接成链表。
下面是ip_init()函数
/*
* IP registers the packet type and then calls the subprotocol initialisers
*/
void ip_init(void)//该函数在af_inet.c文件中
{
ip_packet_type.type=htons(ETH_P_IP);
dev_add_pack(&ip_packet_type);//将网络协议插入IP协议链表,头插法
/* So we flush routes when a device is downed */
register_netdevice_notifier(&ip_rt_notifier);//将其插入通知链表
/* ip_raw_init();
ip_packet_init();
ip_tcp_init();
ip_udp_init();*/
}
这里需要说明的是系统采用主动通知的方式,其实现是有赖于notifier_block结构,其定义在notifier.h中
struct notifier_block
{
int (*notifier_call)(unsigned long, void *);
struct notifier_block *next;
int priority;
};对于网卡设备而言,网卡设备的启动和关闭是事件,内核需要得到通知从而采取相应的措施。其原理是:当事件发生时,事件通知者便利某个队列,对队列中感兴趣(符合条件)的被通知者调用被通知者注册是定义的通知处理函数,从而达到让内核做出相应的操作。
当硬件缓冲区数据填满后,会执行中断处理程序,以NE 8390网卡为例,由于在ne.c文件中注册中断时的中断处理函数设置如下:
request_irq (dev->irq, ei_interrupt, 0, wordlength==2 ? "ne2000":"ne1000");中断处理函数为ei_interrupt()。执行ei_interrupt()函数时会调用函数ei_recieve(),而ei_recieve()函数会调用netif_rx()函数将以skb_buf的形式发送给上层。
当然netif_rx()函数的特点前面分析过,即Bottom Half技术,使得中断处理过程有效的缩短,提高系统的效率。在下半段该函数会调用dev_transmit()函数,而它会调用函数dev_tint()函数,dev_tinit()会调用函数dev_queue_xmit(),这个函数会调用dev->hard_start_xmit函数,该函数指针在ethdev_init()函数中赋值了:
dev->hard_start_xmit = &ei_start_xmit;//设备的发送函数,定义在8390.c中最后调用ei_start_xmit()函数将数据包从硬件设备中读出放在skb中,即存放到内核空间中。
中断返回后系统会执行下半段,即执行net_bh()函数,该函数会扫描网络协议队列,调用相应的协议的接收函数,IP协议就会调用ip_rcv()
/*
* When we are called the queue is ready to grab, the interrupts are
* on and hardware can interrupt and queue to the receive queue a we
* run with no problems.
* This is run as a bottom half after an interrupt handler that does
* mark_bh(NET_BH);
*/
void net_bh(void *tmp)
{
...................................
while((skb=skb_dequeue(&backlog))!=NULL)//出队直到队列为空
{
...............................
/*
* Fetch the packet protocol ID. This is also quite ugly, as
* it depends on the protocol driver (the interface itself) to
* know what the type is, or where to get it from. The Ethernet
* interfaces fetch the ID from the two bytes in the Ethernet MAC
* header (the h_proto field in struct ethhdr), but other drivers
* may either use the ethernet ID's or extra ones that do not
* clash (eg ETH_P_AX25). We could set this before we queue the
* frame. In fact I may change this when I have time.
*/
type = skb->dev->type_trans(skb, skb->dev);//取出该数据包所属的协议类型
/*
* We got a packet ID. Now loop over the "known protocols"
* table (which is actually a linked list, but this will
* change soon if I get my way- FvK), and forward the packet
* to anyone who wants it.
*
* [FvK didn't get his way but he is right this ought to be
* hashed so we typically get a single hit. The speed cost
* here is minimal but no doubt adds up at the 4,000+ pkts/second
* rate we can hit flat out]
*/
pt_prev = NULL;
for (ptype = ptype_base; ptype != NULL; ptype = ptype->next) //遍历ptype_base所指向的网络协议队列
{
//判断协议号是否匹配
if ((ptype->type == type || ptype->type == htons(ETH_P_ALL)) && (!ptype->dev || ptype->dev==skb->dev))
{
/*
* We already have a match queued. Deliver
* to it and then remember the new match
*/
if(pt_prev)
{
struct sk_buff *skb2;
skb2=skb_clone(skb, GFP_ATOMIC);//复制数据包结构
/*
* Kick the protocol handler. This should be fast
* and efficient code.
*/
if(skb2)
pt_prev->func(skb2, skb->dev, pt_prev);//调用相应协议的处理函数,
//这里和网络协议的种类有关系
//如IP 协议的处理函数就是ip_rcv
}
/* Remember the current last to do */
pt_prev=ptype;
}
} /* End of protocol list loop */
...........................................
}IP数据包类型的初始化设置在ip.c中
接下来分析ip_rcv()函数,这是IP层的接收函数,接收来自链路层的数据。
这里首先了解一下IP数据包的首部结构,结构示意图如下:
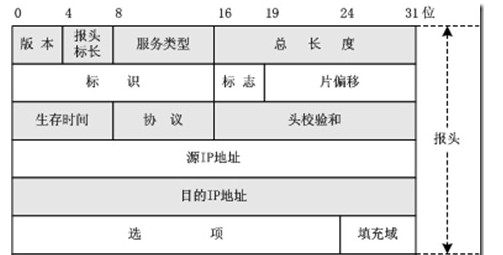
标志位三位,分别是:保留,DF(可以分片),MF(还有后续分片)。
内核中对应的结构体定义如下(include/linux/ip.h):
/*IP数据包首部结构体*/
struct iphdr {
#if defined(LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,
version:4;
#elif defined (BIG_ENDIAN_BITFIELD)
__u8 version:4,
ihl:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 tos;//服务类型
__u16 tot_len;//总长度
__u16 id;//标示
__u16 frag_off;//标志和片偏移
__u8 ttl;//生存时间
__u8 protocol;//协议
__u16 check;//头部校验和
__u32 saddr;//源地址
__u32 daddr;//目的地址
/*The options start here. */
};
内核中用于封装网络数据的最重要的数据结构sk_buff定义在include/linux/skbuff.h中:
struct sk_buff {
struct sk_buff * volatile next;//指针域,指向后继
struct sk_buff * volatile prev;//指针域,指向前驱
#if CONFIG_SKB_CHECK
int magic_debug_cookie;
#endif
struct sk_buff * volatile link3;//该指针域用于TCP协议,指向数据包重发队列
struct sock *sk;//该数据指向的套接字
volatile unsigned long when; /* used to compute rtt's 用于计算往返时间*/
struct timeval stamp;
struct device *dev;//标示发送或接收该数据包的接口设备
struct sk_buff *mem_addr;//指向该sk_buff结构指向的内存基地址,用于该数据结构的内存释放
union {//该联合结构用于实现通用
struct tcphdr *th;
struct ethhdr *eth;//链路层有效
struct iphdr *iph;//网络层有效
struct udphdr *uh;
unsigned char *raw;
unsigned long seq;//TCP协议有效,表示该数据包的ACK值
} h;
struct iphdr *ip_hdr; /* For IPPROTO_RAW ,指向IP首部指针,用于RAW套接字*/
unsigned long mem_len;//表示该结构的大小和数据帧的总大小
unsigned long len;//表示数据帧大小
unsigned long fraglen;//表示分片个数
struct sk_buff *fraglist; /* Fragment list ,分片数据包队列*/
unsigned long truesize;//==mem_len
unsigned long saddr;//源地址
unsigned long daddr;//目的地址
unsigned long raddr;//数据包的下一站地址
volatile char acked,//==1表示该数据包已经得到确认
used,//==1表示该数据包已经被数据包用完,可以释放
free,//==1表示该数据包用完后直接释放,不用缓存
arp;//==1表示MAC数据帧首部完成,否则表示MAC首部目的硬件地址尚不知晓,需使用ARP协议询问
unsigned char tries,//表示数据包已得到试发送
lock,//表示是否被其他程序使用
localroute,//表示是局域网路由还是广域网路由
pkt_type;//表示数据包的类型,分为,发往本机、广播、多播、发往其他主机
#define PACKET_HOST 0 /* To us */
#define PACKET_BROADCAST 1
#define PACKET_MULTICAST 2
#define PACKET_OTHERHOST 3 /* Unmatched promiscuous */
unsigned short users; /* User count - see datagram.c (and soon seqpacket.c/stream.c) 使用该数据包的程序数目*/
unsigned short pkt_class; /* For drivers that need to cache the packet type with the skbuff (new PPP) */
#ifdef CONFIG_SLAVE_BALANCING
unsigned short in_dev_queue;//表示数据包是否在设备缓冲队列
#endif
unsigned long padding[0];//填充
unsigned char data[0];//指向数据部分
};
ip_rcv()函数流程图:

/*
* This function receives all incoming IP datagrams.
*/
int ip_rcv(struct sk_buff *skb, struct device *dev, struct packet_type *pt)
{
struct iphdr *iph = skb->h.iph;
struct sock *raw_sk=NULL;
unsigned char hash;
unsigned char flag = 0;
unsigned char opts_p = 0; /* Set iff the packet has options. */
struct inet_protocol *ipprot;//每个传输层协议对应一个inet_protocol,用于调用传输层的服务函数
static struct options opt; /* since we don't use these yet, and they
take up stack space. */
int brd=IS_MYADDR;
int is_frag=0;
#ifdef CONFIG_IP_FIREWALL
int err;
#endif
ip_statistics.IpInReceives++;
/*
* Tag the ip header of this packet so we can find it
*/
skb->ip_hdr = iph;//设置IP首部指针
/*
* Is the datagram acceptable?
*
* 1. Length at least the size of an ip header
* 2. Version of 4
* 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums]
* (4. We ought to check for IP multicast addresses and undefined types.. does this matter ?)
*/
//IP数据包合法性检查
if (skb->len<sizeof(struct iphdr) || iph->ihl<5 || iph->version != 4 ||
skb->len<ntohs(iph->tot_len) || ip_fast_csum((unsigned char *)iph, iph->ihl) !=0)
{
ip_statistics.IpInHdrErrors++;
kfree_skb(skb, FREE_WRITE);
return(0);
}
/*
* See if the firewall wants to dispose of the packet.
*/
#ifdef CONFIG_IP_FIREWALL
//检查防火墙是否阻止该数据包,过滤数据包
if ((err=ip_fw_chk(iph,dev,ip_fw_blk_chain,ip_fw_blk_policy, 0))!=1)
{
if(err==-1)
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0, dev);
kfree_skb(skb, FREE_WRITE);
return 0;
}
#endif
/*
* Our transport medium may have padded the buffer out. Now we know it
* is IP we can trim to the true length of the frame.
*/
skb->len=ntohs(iph->tot_len);
/*
* Next analyse the packet for options. Studies show under one packet in
* a thousand have options....
*/
if (iph->ihl != 5)//IP数据报首部存在选项字段
{ /* Fast path for the typical optionless IP packet. */
memset((char *) &opt, 0, sizeof(opt));
if (do_options(iph, &opt) != 0)
return 0;
opts_p = 1;
}
/*
* Remember if the frame is fragmented.
*/
//看该数据包是否含有分片,MF和偏移同时为0,则表示无分片,否则是分片,此处有BUG
/*
分片的条件
第一个分片MF=1,offset=0
中间分片MF=1,offset!=0
最后分片MF=1,offset!=0
*/
if(iph->frag_off)
{
if (iph->frag_off & 0x0020)
is_frag|=1;
/*
* Last fragment ?
*/
if (ntohs(iph->frag_off) & 0x1fff)
is_frag|=2;
}
/*
* Do any IP forwarding required. chk_addr() is expensive -- avoid it someday.
*
* This is inefficient. While finding out if it is for us we could also compute
* the routing table entry. This is where the great unified cache theory comes
* in as and when someone implements it
*
* For most hosts over 99% of packets match the first conditional
* and don't go via ip_chk_addr. Note: brd is set to IS_MYADDR at
* function entry.
*/
if ( iph->daddr != skb->dev->pa_addr && (brd = ip_chk_addr(iph->daddr)) == 0)
{
/*
* Don't forward multicast or broadcast frames.广播的数据报不转发
*/
if(skb->pkt_type!=PACKET_HOST || brd==IS_BROADCAST)
{
kfree_skb(skb,FREE_WRITE);
return 0;
}
/*
* The packet is for another target. Forward the frame
*/
#ifdef CONFIG_IP_FORWARD
ip_forward(skb, dev, is_frag);//转发数据报
#else
/* printk("Machine %lx tried to use us as a forwarder to %lx but we have forwarding disabled!\n",
iph->saddr,iph->daddr);*/
ip_statistics.IpInAddrErrors++;
#endif
/*
* The forwarder is inefficient and copies the packet. We
* free the original now.
*/
kfree_skb(skb, FREE_WRITE);
return(0);
}
#ifdef CONFIG_IP_MULTICAST
//多播
if(brd==IS_MULTICAST && iph->daddr!=IGMP_ALL_HOSTS && !(dev->flags&IFF_LOOPBACK))
{
/*
* Check it is for one of our groups
*/
struct ip_mc_list *ip_mc=dev->ip_mc_list;
do
{
if(ip_mc==NULL)
{
kfree_skb(skb, FREE_WRITE);
return 0;
}
if(ip_mc->multiaddr==iph->daddr)
break;
ip_mc=ip_mc->next;
}
while(1);
}
#endif
/*
* Account for the packet
*/
#ifdef CONFIG_IP_ACCT
ip_acct_cnt(iph,dev, ip_acct_chain);
#endif
/*
* Reassemble IP fragments.
*/
if(is_frag)//该数据报是一个分片,进行合并
{
/* Defragment. Obtain the complete packet if there is one */
/*该函数的作用是梳理分片的数据报,如果接收当前分片后,所有分片均已到达
*该函数会调用ip_glue()函数进行IP数据报的重组,否则将该IP数据报放到ipq中fragment
*字段指向的队列中
*
*/
skb=ip_defrag(iph,skb,dev);
if(skb==NULL)
return 0;
skb->dev = dev;
iph=skb->h.iph;
}
/*
* Point into the IP datagram, just past the header.
*/
skb->ip_hdr = iph;
skb->h.raw += iph->ihl*4;//sk_buff中union类型的h字段永远指向当前正在处理的协议的首部,这里使其指向传输层的首部,用于传输层的处理
/*
* Deliver to raw sockets. This is fun as to avoid copies we want to make no surplus copies.
*/
hash = iph->protocol & (SOCK_ARRAY_SIZE-1);
/* If there maybe a raw socket we must check - if not we don't care less */
//处理RAW类型的套接字
if((raw_sk=raw_prot.sock_array[hash])!=NULL)
{
struct sock *sknext=NULL;
struct sk_buff *skb1;
raw_sk=get_sock_raw(raw_sk, hash, iph->saddr, iph->daddr);
if(raw_sk) /* Any raw sockets */
{
do
{
/* Find the next */
sknext=get_sock_raw(raw_sk->next, hash, iph->saddr, iph->daddr);
if(sknext)
skb1=skb_clone(skb, GFP_ATOMIC);
else
break; /* One pending raw socket left */
if(skb1)
raw_rcv(raw_sk, skb1, dev, iph->saddr,iph->daddr);//RAW类型套接字的接收函数
raw_sk=sknext;
}
while(raw_sk!=NULL);
/* Here either raw_sk is the last raw socket, or NULL if none */
/* We deliver to the last raw socket AFTER the protocol checks as it avoids a surplus copy */
}
}
/*
* skb->h.raw now points at the protocol beyond the IP header.
*/
hash = iph->protocol & (MAX_INET_PROTOS -1);
//对所有使用IP协议的上层协议套接字处理
for (ipprot = (struct inet_protocol *)inet_protos[hash];ipprot != NULL;ipprot=(struct inet_protocol *)ipprot->next)
{
struct sk_buff *skb2;
if (ipprot->protocol != iph->protocol)
continue;
/*
* See if we need to make a copy of it. This will
* only be set if more than one protocol wants it.
* and then not for the last one. If there is a pending
* raw delivery wait for that
*/
if (ipprot->copy || raw_sk)
{
skb2 = skb_clone(skb, GFP_ATOMIC);
if(skb2==NULL)
continue;
}
else
{
skb2 = skb;
}
flag = 1;
/*
* Pass on the datagram to each protocol that wants it,
* based on the datagram protocol. We should really
* check the protocol handler's return values here...
*/
ipprot->handler(skb2, dev, opts_p ? &opt : 0, iph->daddr,
(ntohs(iph->tot_len) - (iph->ihl * 4)),
iph->saddr, 0, ipprot);
}
/*
* All protocols checked.
* If this packet was a broadcast, we may *not* reply to it, since that
* causes (proven, grin) ARP storms and a leakage of memory (i.e. all
* ICMP reply messages get queued up for transmission...)
*/
if(raw_sk!=NULL) /* Shift to last raw user */
raw_rcv(raw_sk, skb, dev, iph->saddr, iph->daddr);
else if (!flag) /* Free and report errors */
{
if (brd != IS_BROADCAST && brd!=IS_MULTICAST)
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PROT_UNREACH, 0, dev);
kfree_skb(skb, FREE_WRITE);
}
return(0);
}
这里会进一步调用raw_rcv()或者相应协议的ipprot->handler来调用传输层服务函数。下篇会进行简单分析。
原创作品,转载请标明http://blog.csdn.net/yming0221/article/details/7514017
更多请看专栏,地址http://blog.csdn.net/column/details/linux-kernel-net.html
作者:闫明
注:标题中的”(上)“,”(下)“表示分析过程基于数据包的传递方向:”(上)“表示分析是从底层向上分析、”(下)“表示分析是从上向下分析。
简单分析了链路层之后,上升到网络层来分析,看看链路层是如何为其上层--网络层服务的。其实在驱动程序层和网络层直接还有一层是接口层,叫做驱动程序接口层,用来整合不同的网络设备。接口层的内容会在上下层中提及。这里我们分析网络IP协议的实现原理。
其实现的文件主要是net/inet/ip.c文件中
我们首先分析下ip_init()初始化函数
这个函数是如何被调用的呢?
下面是调用的过程:
首先是在系统启动过程main.c中调用了sock_init()函数
void sock_init(void)//网络栈初始化
{
int i;
printk("Swansea University Computer Society NET3.019\n");
/*
* Initialize all address (protocol) families.
*/
for (i = 0; i < NPROTO; ++i) pops[i] = NULL;
/*
* Initialize the protocols module.
*/
proto_init();
#ifdef CONFIG_NET
/*
* Initialize the DEV module.
*/
dev_init();
/*
* And the bottom half handler
*/
bh_base[NET_BH].routine= net_bh;//设置NET 下半部分的处理函数为net_bh
enable_bh(NET_BH);
#endif
}
然后调用了proto_init()函数
void proto_init(void)
{
extern struct net_proto protocols[]; /* Network protocols 全局变量,定义在protocols.c中*/
struct net_proto *pro;
/* Kick all configured protocols. */
pro = protocols;
while (pro->name != NULL) //对所有的定义的域进行初始化
{
(*pro->init_func)(pro);
pro++;
}
/* We're all done... */
}
而protocols全局变量协议向量表的定义中对INET域中协议的初始化函数设置为inet_proto_init()
/*
* Protocol Table
*/
struct net_proto protocols[] = {
#ifdef CONFIG_UNIX
{ "UNIX", unix_proto_init },
#endif
#if defined(CONFIG_IPX)||defined(CONFIG_ATALK)
{ "802.2", p8022_proto_init },
{ "SNAP", snap_proto_init },
#endif
#ifdef CONFIG_AX25
{ "AX.25", ax25_proto_init },
#endif
#ifdef CONFIG_INET
{ "INET", inet_proto_init },
#endif
#ifdef CONFIG_IPX
{ "IPX", ipx_proto_init },
#endif
#ifdef CONFIG_ATALK
{ "DDP", atalk_proto_init },
#endif
{ NULL, NULL }
};
看到在inet_proto_init()函数中调用了ip_init()对IP层进行了初始化。
void inet_proto_init(struct net_proto *pro)//INET域协议初始化函数
{
struct inet_protocol *p;
int i;
printk("Swansea University Computer Society TCP/IP for NET3.019\n");
/*
* Tell SOCKET that we are alive...
*/
(void) sock_register(inet_proto_ops.family, &inet_proto_ops);
...........................................
printk("IP Protocols: ");
for(p = inet_protocol_base; p != NULL;) //将inet_protocol_base指向的一个inet_protocol结构体加入数组inet_protos中
{
struct inet_protocol *tmp = (struct inet_protocol *) p->next;
inet_add_protocol(p);
printk("%s%s",p->name,tmp?", ":"\n");
p = tmp;
}
/*
* Set the ARP module up
*/
arp_init();//对地址解析层进行初始化
/*
* Set the IP module up
*/
ip_init();//对IP层进行初始化
}代码中inet_protocol_base指向的链表为&igmp_protocol-->&icmp_protocol-->&udp_protocol-->&tcp_protocol-->NULL(定义在protocol.c中)
分析ip_init()函数需要先要知道packet_type结构,这个结构体是网络层协议的结构体,网络层协议与该结构体一一对应。
/*该结构用于表示网络层协议,网络层协议与packt_type一一对应*/
struct packet_type {
unsigned short type; /* This is really htons(ether_type). ,对应的网络层协议编号*/
struct device * dev;
int (*func) (struct sk_buff *, struct device *,
struct packet_type *);
void *data;
struct packet_type *next;
};第一个字段的网络层协议编号定义在include/linux/if_ether.h中
/* These are the defined Ethernet Protocol ID's. */
#define ETH_P_LOOP 0x0060 /* Ethernet Loopback packet */
#define ETH_P_ECHO 0x0200 /* Ethernet Echo packet */
#define ETH_P_PUP 0x0400 /* Xerox PUP packet */
#define ETH_P_IP 0x0800 /* Internet Protocol packet */
#define ETH_P_ARP 0x0806 /* Address Resolution packet */
#define ETH_P_RARP 0x8035 /* Reverse Addr Res packet */
#define ETH_P_X25 0x0805 /* CCITT X.25 */
#define ETH_P_ATALK 0x809B /* Appletalk DDP */
#define ETH_P_IPX 0x8137 /* IPX over DIX */
#define ETH_P_802_3 0x0001 /* Dummy type for 802.3 frames */
#define ETH_P_AX25 0x0002 /* Dummy protocol id for AX.25 */
#define ETH_P_ALL 0x0003 /* Every packet (be careful!!!) */
#define ETH_P_802_2 0x0004 /* 802.2 frames */
#define ETH_P_SNAP 0x0005 /* Internal only */
第二个字段表示处理包的网络接口设备,一般初始化为NULL。
第三个字段为相应网络协议的处理函数。
第四个字段是一个void指针。
第五个字段是next指针域,用于将该结构连接成链表。
下面是ip_init()函数
/*
* IP registers the packet type and then calls the subprotocol initialisers
*/
void ip_init(void)//该函数在af_inet.c文件中
{
ip_packet_type.type=htons(ETH_P_IP);
dev_add_pack(&ip_packet_type);//将网络协议插入IP协议链表,头插法
/* So we flush routes when a device is downed */
register_netdevice_notifier(&ip_rt_notifier);//将其插入通知链表
/* ip_raw_init();
ip_packet_init();
ip_tcp_init();
ip_udp_init();*/
}
这里需要说明的是系统采用主动通知的方式,其实现是有赖于notifier_block结构,其定义在notifier.h中
struct notifier_block
{
int (*notifier_call)(unsigned long, void *);
struct notifier_block *next;
int priority;
};对于网卡设备而言,网卡设备的启动和关闭是事件,内核需要得到通知从而采取相应的措施。其原理是:当事件发生时,事件通知者便利某个队列,对队列中感兴趣(符合条件)的被通知者调用被通知者注册是定义的通知处理函数,从而达到让内核做出相应的操作。
当硬件缓冲区数据填满后,会执行中断处理程序,以NE 8390网卡为例,由于在ne.c文件中注册中断时的中断处理函数设置如下:
request_irq (dev->irq, ei_interrupt, 0, wordlength==2 ? "ne2000":"ne1000");中断处理函数为ei_interrupt()。执行ei_interrupt()函数时会调用函数ei_recieve(),而ei_recieve()函数会调用netif_rx()函数将以skb_buf的形式发送给上层。
当然netif_rx()函数的特点前面分析过,即Bottom Half技术,使得中断处理过程有效的缩短,提高系统的效率。在下半段该函数会调用dev_transmit()函数,而它会调用函数dev_tint()函数,dev_tinit()会调用函数dev_queue_xmit(),这个函数会调用dev->hard_start_xmit函数,该函数指针在ethdev_init()函数中赋值了:
dev->hard_start_xmit = &ei_start_xmit;//设备的发送函数,定义在8390.c中最后调用ei_start_xmit()函数将数据包从硬件设备中读出放在skb中,即存放到内核空间中。
中断返回后系统会执行下半段,即执行net_bh()函数,该函数会扫描网络协议队列,调用相应的协议的接收函数,IP协议就会调用ip_rcv()
/*
* When we are called the queue is ready to grab, the interrupts are
* on and hardware can interrupt and queue to the receive queue a we
* run with no problems.
* This is run as a bottom half after an interrupt handler that does
* mark_bh(NET_BH);
*/
void net_bh(void *tmp)
{
...................................
while((skb=skb_dequeue(&backlog))!=NULL)//出队直到队列为空
{
...............................
/*
* Fetch the packet protocol ID. This is also quite ugly, as
* it depends on the protocol driver (the interface itself) to
* know what the type is, or where to get it from. The Ethernet
* interfaces fetch the ID from the two bytes in the Ethernet MAC
* header (the h_proto field in struct ethhdr), but other drivers
* may either use the ethernet ID's or extra ones that do not
* clash (eg ETH_P_AX25). We could set this before we queue the
* frame. In fact I may change this when I have time.
*/
type = skb->dev->type_trans(skb, skb->dev);//取出该数据包所属的协议类型
/*
* We got a packet ID. Now loop over the "known protocols"
* table (which is actually a linked list, but this will
* change soon if I get my way- FvK), and forward the packet
* to anyone who wants it.
*
* [FvK didn't get his way but he is right this ought to be
* hashed so we typically get a single hit. The speed cost
* here is minimal but no doubt adds up at the 4,000+ pkts/second
* rate we can hit flat out]
*/
pt_prev = NULL;
for (ptype = ptype_base; ptype != NULL; ptype = ptype->next) //遍历ptype_base所指向的网络协议队列
{
//判断协议号是否匹配
if ((ptype->type == type || ptype->type == htons(ETH_P_ALL)) && (!ptype->dev || ptype->dev==skb->dev))
{
/*
* We already have a match queued. Deliver
* to it and then remember the new match
*/
if(pt_prev)
{
struct sk_buff *skb2;
skb2=skb_clone(skb, GFP_ATOMIC);//复制数据包结构
/*
* Kick the protocol handler. This should be fast
* and efficient code.
*/
if(skb2)
pt_prev->func(skb2, skb->dev, pt_prev);//调用相应协议的处理函数,
//这里和网络协议的种类有关系
//如IP 协议的处理函数就是ip_rcv
}
/* Remember the current last to do */
pt_prev=ptype;
}
} /* End of protocol list loop */
...........................................
}IP数据包类型的初始化设置在ip.c中
/*
* IP protocol layer initialiser
*/
static struct packet_type ip_packet_type =
{
0, /* MUTTER ntohs(ETH_P_IP),*/
NULL, /* All devices */
ip_rcv,
NULL,
NULL,
};接下来分析ip_rcv()函数,这是IP层的接收函数,接收来自链路层的数据。
这里首先了解一下IP数据包的首部结构,结构示意图如下:
标志位三位,分别是:保留,DF(可以分片),MF(还有后续分片)。
内核中对应的结构体定义如下(include/linux/ip.h):
/*IP数据包首部结构体*/
struct iphdr {
#if defined(LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,
version:4;
#elif defined (BIG_ENDIAN_BITFIELD)
__u8 version:4,
ihl:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 tos;//服务类型
__u16 tot_len;//总长度
__u16 id;//标示
__u16 frag_off;//标志和片偏移
__u8 ttl;//生存时间
__u8 protocol;//协议
__u16 check;//头部校验和
__u32 saddr;//源地址
__u32 daddr;//目的地址
/*The options start here. */
};
内核中用于封装网络数据的最重要的数据结构sk_buff定义在include/linux/skbuff.h中:
struct sk_buff {
struct sk_buff * volatile next;//指针域,指向后继
struct sk_buff * volatile prev;//指针域,指向前驱
#if CONFIG_SKB_CHECK
int magic_debug_cookie;
#endif
struct sk_buff * volatile link3;//该指针域用于TCP协议,指向数据包重发队列
struct sock *sk;//该数据指向的套接字
volatile unsigned long when; /* used to compute rtt's 用于计算往返时间*/
struct timeval stamp;
struct device *dev;//标示发送或接收该数据包的接口设备
struct sk_buff *mem_addr;//指向该sk_buff结构指向的内存基地址,用于该数据结构的内存释放
union {//该联合结构用于实现通用
struct tcphdr *th;
struct ethhdr *eth;//链路层有效
struct iphdr *iph;//网络层有效
struct udphdr *uh;
unsigned char *raw;
unsigned long seq;//TCP协议有效,表示该数据包的ACK值
} h;
struct iphdr *ip_hdr; /* For IPPROTO_RAW ,指向IP首部指针,用于RAW套接字*/
unsigned long mem_len;//表示该结构的大小和数据帧的总大小
unsigned long len;//表示数据帧大小
unsigned long fraglen;//表示分片个数
struct sk_buff *fraglist; /* Fragment list ,分片数据包队列*/
unsigned long truesize;//==mem_len
unsigned long saddr;//源地址
unsigned long daddr;//目的地址
unsigned long raddr;//数据包的下一站地址
volatile char acked,//==1表示该数据包已经得到确认
used,//==1表示该数据包已经被数据包用完,可以释放
free,//==1表示该数据包用完后直接释放,不用缓存
arp;//==1表示MAC数据帧首部完成,否则表示MAC首部目的硬件地址尚不知晓,需使用ARP协议询问
unsigned char tries,//表示数据包已得到试发送
lock,//表示是否被其他程序使用
localroute,//表示是局域网路由还是广域网路由
pkt_type;//表示数据包的类型,分为,发往本机、广播、多播、发往其他主机
#define PACKET_HOST 0 /* To us */
#define PACKET_BROADCAST 1
#define PACKET_MULTICAST 2
#define PACKET_OTHERHOST 3 /* Unmatched promiscuous */
unsigned short users; /* User count - see datagram.c (and soon seqpacket.c/stream.c) 使用该数据包的程序数目*/
unsigned short pkt_class; /* For drivers that need to cache the packet type with the skbuff (new PPP) */
#ifdef CONFIG_SLAVE_BALANCING
unsigned short in_dev_queue;//表示数据包是否在设备缓冲队列
#endif
unsigned long padding[0];//填充
unsigned char data[0];//指向数据部分
};
ip_rcv()函数流程图:
/*
* This function receives all incoming IP datagrams.
*/
int ip_rcv(struct sk_buff *skb, struct device *dev, struct packet_type *pt)
{
struct iphdr *iph = skb->h.iph;
struct sock *raw_sk=NULL;
unsigned char hash;
unsigned char flag = 0;
unsigned char opts_p = 0; /* Set iff the packet has options. */
struct inet_protocol *ipprot;//每个传输层协议对应一个inet_protocol,用于调用传输层的服务函数
static struct options opt; /* since we don't use these yet, and they
take up stack space. */
int brd=IS_MYADDR;
int is_frag=0;
#ifdef CONFIG_IP_FIREWALL
int err;
#endif
ip_statistics.IpInReceives++;
/*
* Tag the ip header of this packet so we can find it
*/
skb->ip_hdr = iph;//设置IP首部指针
/*
* Is the datagram acceptable?
*
* 1. Length at least the size of an ip header
* 2. Version of 4
* 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums]
* (4. We ought to check for IP multicast addresses and undefined types.. does this matter ?)
*/
//IP数据包合法性检查
if (skb->len<sizeof(struct iphdr) || iph->ihl<5 || iph->version != 4 ||
skb->len<ntohs(iph->tot_len) || ip_fast_csum((unsigned char *)iph, iph->ihl) !=0)
{
ip_statistics.IpInHdrErrors++;
kfree_skb(skb, FREE_WRITE);
return(0);
}
/*
* See if the firewall wants to dispose of the packet.
*/
#ifdef CONFIG_IP_FIREWALL
//检查防火墙是否阻止该数据包,过滤数据包
if ((err=ip_fw_chk(iph,dev,ip_fw_blk_chain,ip_fw_blk_policy, 0))!=1)
{
if(err==-1)
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0, dev);
kfree_skb(skb, FREE_WRITE);
return 0;
}
#endif
/*
* Our transport medium may have padded the buffer out. Now we know it
* is IP we can trim to the true length of the frame.
*/
skb->len=ntohs(iph->tot_len);
/*
* Next analyse the packet for options. Studies show under one packet in
* a thousand have options....
*/
if (iph->ihl != 5)//IP数据报首部存在选项字段
{ /* Fast path for the typical optionless IP packet. */
memset((char *) &opt, 0, sizeof(opt));
if (do_options(iph, &opt) != 0)
return 0;
opts_p = 1;
}
/*
* Remember if the frame is fragmented.
*/
//看该数据包是否含有分片,MF和偏移同时为0,则表示无分片,否则是分片,此处有BUG
/*
分片的条件
第一个分片MF=1,offset=0
中间分片MF=1,offset!=0
最后分片MF=1,offset!=0
*/
if(iph->frag_off)
{
if (iph->frag_off & 0x0020)
is_frag|=1;
/*
* Last fragment ?
*/
if (ntohs(iph->frag_off) & 0x1fff)
is_frag|=2;
}
/*
* Do any IP forwarding required. chk_addr() is expensive -- avoid it someday.
*
* This is inefficient. While finding out if it is for us we could also compute
* the routing table entry. This is where the great unified cache theory comes
* in as and when someone implements it
*
* For most hosts over 99% of packets match the first conditional
* and don't go via ip_chk_addr. Note: brd is set to IS_MYADDR at
* function entry.
*/
if ( iph->daddr != skb->dev->pa_addr && (brd = ip_chk_addr(iph->daddr)) == 0)
{
/*
* Don't forward multicast or broadcast frames.广播的数据报不转发
*/
if(skb->pkt_type!=PACKET_HOST || brd==IS_BROADCAST)
{
kfree_skb(skb,FREE_WRITE);
return 0;
}
/*
* The packet is for another target. Forward the frame
*/
#ifdef CONFIG_IP_FORWARD
ip_forward(skb, dev, is_frag);//转发数据报
#else
/* printk("Machine %lx tried to use us as a forwarder to %lx but we have forwarding disabled!\n",
iph->saddr,iph->daddr);*/
ip_statistics.IpInAddrErrors++;
#endif
/*
* The forwarder is inefficient and copies the packet. We
* free the original now.
*/
kfree_skb(skb, FREE_WRITE);
return(0);
}
#ifdef CONFIG_IP_MULTICAST
//多播
if(brd==IS_MULTICAST && iph->daddr!=IGMP_ALL_HOSTS && !(dev->flags&IFF_LOOPBACK))
{
/*
* Check it is for one of our groups
*/
struct ip_mc_list *ip_mc=dev->ip_mc_list;
do
{
if(ip_mc==NULL)
{
kfree_skb(skb, FREE_WRITE);
return 0;
}
if(ip_mc->multiaddr==iph->daddr)
break;
ip_mc=ip_mc->next;
}
while(1);
}
#endif
/*
* Account for the packet
*/
#ifdef CONFIG_IP_ACCT
ip_acct_cnt(iph,dev, ip_acct_chain);
#endif
/*
* Reassemble IP fragments.
*/
if(is_frag)//该数据报是一个分片,进行合并
{
/* Defragment. Obtain the complete packet if there is one */
/*该函数的作用是梳理分片的数据报,如果接收当前分片后,所有分片均已到达
*该函数会调用ip_glue()函数进行IP数据报的重组,否则将该IP数据报放到ipq中fragment
*字段指向的队列中
*
*/
skb=ip_defrag(iph,skb,dev);
if(skb==NULL)
return 0;
skb->dev = dev;
iph=skb->h.iph;
}
/*
* Point into the IP datagram, just past the header.
*/
skb->ip_hdr = iph;
skb->h.raw += iph->ihl*4;//sk_buff中union类型的h字段永远指向当前正在处理的协议的首部,这里使其指向传输层的首部,用于传输层的处理
/*
* Deliver to raw sockets. This is fun as to avoid copies we want to make no surplus copies.
*/
hash = iph->protocol & (SOCK_ARRAY_SIZE-1);
/* If there maybe a raw socket we must check - if not we don't care less */
//处理RAW类型的套接字
if((raw_sk=raw_prot.sock_array[hash])!=NULL)
{
struct sock *sknext=NULL;
struct sk_buff *skb1;
raw_sk=get_sock_raw(raw_sk, hash, iph->saddr, iph->daddr);
if(raw_sk) /* Any raw sockets */
{
do
{
/* Find the next */
sknext=get_sock_raw(raw_sk->next, hash, iph->saddr, iph->daddr);
if(sknext)
skb1=skb_clone(skb, GFP_ATOMIC);
else
break; /* One pending raw socket left */
if(skb1)
raw_rcv(raw_sk, skb1, dev, iph->saddr,iph->daddr);//RAW类型套接字的接收函数
raw_sk=sknext;
}
while(raw_sk!=NULL);
/* Here either raw_sk is the last raw socket, or NULL if none */
/* We deliver to the last raw socket AFTER the protocol checks as it avoids a surplus copy */
}
}
/*
* skb->h.raw now points at the protocol beyond the IP header.
*/
hash = iph->protocol & (MAX_INET_PROTOS -1);
//对所有使用IP协议的上层协议套接字处理
for (ipprot = (struct inet_protocol *)inet_protos[hash];ipprot != NULL;ipprot=(struct inet_protocol *)ipprot->next)
{
struct sk_buff *skb2;
if (ipprot->protocol != iph->protocol)
continue;
/*
* See if we need to make a copy of it. This will
* only be set if more than one protocol wants it.
* and then not for the last one. If there is a pending
* raw delivery wait for that
*/
if (ipprot->copy || raw_sk)
{
skb2 = skb_clone(skb, GFP_ATOMIC);
if(skb2==NULL)
continue;
}
else
{
skb2 = skb;
}
flag = 1;
/*
* Pass on the datagram to each protocol that wants it,
* based on the datagram protocol. We should really
* check the protocol handler's return values here...
*/
ipprot->handler(skb2, dev, opts_p ? &opt : 0, iph->daddr,
(ntohs(iph->tot_len) - (iph->ihl * 4)),
iph->saddr, 0, ipprot);
}
/*
* All protocols checked.
* If this packet was a broadcast, we may *not* reply to it, since that
* causes (proven, grin) ARP storms and a leakage of memory (i.e. all
* ICMP reply messages get queued up for transmission...)
*/
if(raw_sk!=NULL) /* Shift to last raw user */
raw_rcv(raw_sk, skb, dev, iph->saddr, iph->daddr);
else if (!flag) /* Free and report errors */
{
if (brd != IS_BROADCAST && brd!=IS_MULTICAST)
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PROT_UNREACH, 0, dev);
kfree_skb(skb, FREE_WRITE);
}
return(0);
}
这里会进一步调用raw_rcv()或者相应协议的ipprot->handler来调用传输层服务函数。下篇会进行简单分析。

相关文章推荐
- Linux内核--网络栈实现分析(四)--网络层之IP协议(上)
- Linux内核--网络栈实现分析(四)--网络层之IP协议(上)
- Linux内核--网络栈实现分析(四)--网络层之IP协议(上)
- Linux内核--网络栈实现分析(四)--网络层之IP协议(上)
- Linux内核--网络栈实现分析(十)--网络层之IP协议(下)
- Linux内核--网络栈实现分析(一)--网络栈初始化
- Linux内核--网络栈实现分析(十)--网络层之IP协议(下)
- Linux内核--网络栈实现分析(一)--网络栈初始化--转
- Linux内核--网络栈实现分析(一)--网络栈初始化
- Linux内核--网络栈实现分析(一)--网络栈初始化
- Linux内核--网络栈实现分析(一)--网络栈初始化
- Linux内核--网络栈实现分析(一)--网络栈初始化
- Linux内核--网络栈实现分析(一)--网络栈初始化
- Linux内核--网络栈实现分析(十)--网络层之IP协议(下)
- Linux内核--网络栈实现分析(十)--网络层之IP协议(下)
- Linux内核--网络栈实现分析(一)--网络栈初始化
- Linux内核--网络栈实现分析(一)--网络栈初始化
- Linux内核--网络栈实现分析(十)--网络层之IP协议(下)
- Linux内核--网络栈实现分析(一)--网络栈初始化
- Linux内核--网络栈实现分析(十)--网络层之IP协议(下)