Classification Probability Models and Conditional Random Fields(1)--Naive Bayes
2011-12-06 09:31
411 查看
目前正在学习自然语言处理相关的概率模型,在一篇名为《Classification Probability Models and Conditional Random Fields》论文中讲述了常用的几个经典的概率模型,并分析了他们之间的关系和区别,深入浅出,讲的非常的好。
在很多任务中,面临的问题都是对给定的输入X,对输入赋予一个恰当的分类标签Y。在自然语言处理中,如文本分类、词性标注、分词等等,均可表示为以上形式。在常用的概率模型中,主要分为两类,一类是生成模型(generative model),这类模型计算X与Y的联合概率(joint probability)P(X,Y),常见的有朴树贝叶斯模型,隐马尔科夫模型等。另一类称为判别模型(discriminative model),这类模型计算X与Y的条件概率(conditional
probability) P(Y|X),常见的有最大熵模型、条件随机场模型等。
这四个模型的关系可用图表示如下:

在这些概率模型中,最基本的就是朴树贝叶斯模型。贝叶斯模型是一个分类模型,对于输入赋予一个标签。在朴树贝叶斯模型中,对于给定的输入向量X,对其赋予一个类别标识,其概率可以表示为:

[align=left] 因为我们求的只是相对概率,所以可以将分母去掉,只计算分子即可。在上面的公式中,如果直接进行计算将会有较高的复杂度,所以使用一个链式规则对计算进行分解,得到新的计算公式:
[/align]

在实际应用中,常常假设输入向量X的各维是条件独立的(朴树贝叶斯假设) 即p(x i |y, x j ) = p(x i |y) 。这样上面的计算公式可转换为:
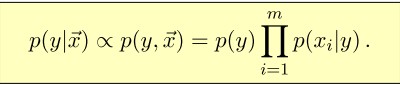
[align=left]这就是朴树贝叶斯分类规则。
[/align]
在很多任务中,面临的问题都是对给定的输入X,对输入赋予一个恰当的分类标签Y。在自然语言处理中,如文本分类、词性标注、分词等等,均可表示为以上形式。在常用的概率模型中,主要分为两类,一类是生成模型(generative model),这类模型计算X与Y的联合概率(joint probability)P(X,Y),常见的有朴树贝叶斯模型,隐马尔科夫模型等。另一类称为判别模型(discriminative model),这类模型计算X与Y的条件概率(conditional
probability) P(Y|X),常见的有最大熵模型、条件随机场模型等。
这四个模型的关系可用图表示如下:
在这些概率模型中,最基本的就是朴树贝叶斯模型。贝叶斯模型是一个分类模型,对于输入赋予一个标签。在朴树贝叶斯模型中,对于给定的输入向量X,对其赋予一个类别标识,其概率可以表示为:
[align=left] 因为我们求的只是相对概率,所以可以将分母去掉,只计算分子即可。在上面的公式中,如果直接进行计算将会有较高的复杂度,所以使用一个链式规则对计算进行分解,得到新的计算公式:
[/align]
在实际应用中,常常假设输入向量X的各维是条件独立的(朴树贝叶斯假设) 即p(x i |y, x j ) = p(x i |y) 。这样上面的计算公式可转换为:
[align=left]这就是朴树贝叶斯分类规则。
[/align]

相关文章推荐
- Classification Probability Models and Conditional Random Fields(2)--HMM
- Classification Probability Models and Conditional Random Fields(3)
- 论文读书笔记-Action unit classification using active appearance models and conditional random fields
- (转)Image Segmentation with Tensorflow using CNNs and Conditional Random Fields
- 20140616——Hidden Conditional Random Fields for Phone Classification
- Conditional Random Fields(CRF)
- conditional random fields
- Generalized linear models and linear classification
- TRAINING ALGORITHMS FOR HIDDEN CONDITIONAL RANDOM FIELDS
- An Introduction to Conditional Random Fields[条件随机场介绍]
- 条件随机场 (conditional random fields )模型
- 条件随机场(Conditional random fields)
- 论文翻译:Conditional Random Fields as Recurrent Neural Networks
- The Idea of Combining Random Matrix and Graphical Models in Machine Learning
- Conditional Random Fields as Recurrent Neural Networks
- 译Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis
- Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps 中文翻译
- 利用pytorch实现Visualising Image Classification Models and Saliency Maps
- Conditional Random Fields as Recurrent Neural Networks
- Notes on Probability Essentials - 2 - Conditional Probability and Independence