爬虫介绍、requests模块使用、get地址中携带参数、请求头、cookie、发送post请求模拟登陆、响应对象、编码问题、获取二进制数据、解析json、ssl认证、使用代理
2022-05-06 14:36
3507 查看
今日内容概要
- 爬虫介绍
- requests模块介绍,发送get请求
- get地址中携带参数
- 携带请求头
- 携带cookie
- 发送post请求模拟登陆
- 响应对象
- 编码问题(一般不会有问题)
- 获取二进制数据
- 解析json
- ssl认证
- 使用代理
内容详细
1、爬虫介绍
# 写后台--->前端展示数据---》浏览器发送http请求,从后端服务器获取的--》只能从浏览器中看---》看到好看的东西---》保存到本地---》存到我们自己库中----》爬虫 # 百度本质就是一个大爬虫(搜索),在输入框中输入搜索内容,实际是从百度的数据库搜索出来的 # 百度数据库的数据是从互联网爬下来的 百度这个爬虫一刻不停的在互联网爬数据--》爬完就存到它的库里(seo优化--》优化我们的网站能够被搜索引擎先搜到,排的很靠前)--->尽可能被百度爬虫,并且容易搜索到 seo(免费的)和sem(充钱,把你放前面)---百度快照---》当时爬虫爬取这个网页这一刻,网页的样子---》保留这个网页地址---》当你点击标题--》跳转到这个网页--》完成了你的搜索 伪静态 # 爬虫的本质 模拟发送http请求(浏览器携带什么,我们也要携带什么)---->服务器返回数据---》对数据进行清洗---》入库 后续操作是别的---》分析数据--》数据分析 # 爬虫协议:君子协议---》大家遵循这个协议,就不违法--》规定了我的网站,什么能爬,什么不能爬 https://www.baidu.com/robots.txt https://www.cnblogs.com/robots.txt # 爬虫本质跟用浏览器访问没什么区别
2、requests模块介绍,发送get请求
# 所有语言都可以做爬虫---》python简单一些---》只是python库多
# 模拟发送http请求的库,requests库----》大佬基于python内置库 urllib(麻烦) 封装--》requests
# 安装
pip install requests
# 模拟发送get请求
import requests
# 1 发送get请求
res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html')
print(res.text) # 响应体的内容打印出来了
3、get地址中携带参数
# 2 get 请求中携带参数
res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html',
params={'name': 'lqz', 'age': 18} # 会将 ?name=lqz&age=18 拼到路径后面
)
print(res.text) # 响应体的内容打印出来了
# url编码和解码
# https://www.baidu.com/baidu?wd=python%20url%E7%BC%96%E7%A0%81%E5%92%8C%E8%A7%A3%E7%A0%81
# (1)把字段中文编码后转成 name=%E5%88%98%E6%B8%85%E6%94%BF&age=18
from urllib.parse import urlencode
d = {'name': '刘清政', 'age': 18}
res = urlencode(d)
print(res) # name=%E5%88%98%E6%B8%85%E6%94%BF&age=18
# (2)只想单独对中文编码和解码
from urllib.parse import quote, unquote
# 编码
name = '刘清政'
res = quote(name)
print(res) # %E5%88%98%E6%B8%85%E6%94%BF
# 解码
s = 'python%20url%E7%BC%96%E7%A0%81%E5%92%8C%E8%A7%A3%E7%A0%81'
print(unquote(s)) # python url编码和解码
4、携带请求头
# 3 携带请求头
# 携带请求头-->重要的key:
# User-Agent:客户端浏览器的类型版本信息,操作系统版本---》django中如何取出请求头--》META---》中间件--》存到数据库--》饼形图--》统计你们网站近一个月客户端类型
# referer:图片防盗链 Referer: https://www.lagou.com/wn/zhaopin
# 记录的是上一个访问的地址---》反扒:如果上一个访问的地址不是自己的地址,认为不是正常请求就禁止
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36',
# 'Accept-Encoding': 'gzip, deflate, br',
}
res = requests.get('https://dig.chouti.com/', headers=header)
with open('chouti.html', 'wb') as f:
f.write(res.content) # 将爬取的页面数据写入chouti.html文件
print(res.text)
5、携带cookie
# 4 携带cookie
# 本身cookie是请求头中的值,那么就可以执行放在请求头中,但是cookie经常用,也可以单独是一个参数
# 模拟点赞
header = {
# 请求头
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36',
# 携带cookie方式一:
# 'Cookie': "_9755xjdesxxd_=32; YD00000980905869%3AWM_TID=l96GLAwE45lAEUFERRI7FydL3O2PRnm8; deviceId=web.eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiIxN2NjOTI3Yy01ZTk5LTQ4ZTItYjcxYy1jNGYzZjRlNzQ0YWUiLCJleHBpcmUiOiIxNjI0MDMzMzQ4MzU3In0.A_zoDMD9dl-DWTHQHvqaqfETjWrtTOIaaTbSEsMXmWA; __snaker__id=Q5EBZZDnY6PYW8XM; Hm_lvt_03b2668f8e8699e91d479d62bc7630f1=1650937205,1651805845; gdxidpyhxdE=lPBeo3vIhlgODippQ8rLyp1mN9%2F9dN0Bh%2Fd1YAHHmqKPAL7eIo5dGhT%5C6Bs%2BbdeDj0Bmm%2Fsu5rmAKC%5CqZc2Ru3J%2FyswELA5l6drG8SDCc4gLZ1vkkaE%2Fh0nA%5CJUhy2apWM%2Bnez3%2BaQNLB0hbmTGhvU%2Fq7mkRxpWk7fT7uj4KquGOeyjA%3A1651808005585; YD00000980905869%3AWM_NI=7ath5ozFgWjeycGOnrWcCCFiL3SFzKPqqqXWXjLZ95ZUSG8bIOdcrbZIeG9opeqMKc46feYlaXfMiJdxu91sxSZqIKyhLJU6CQN4cX9p2eqP7rYpiszlQM%2BU61%2BcofTaejE%3D; YD00000980905869%3AWM_NIKE=9ca17ae2e6ffcda170e2e6eeacd23cafae8e94b374abb88ba3c44b868f8fadd54f9a96e583d54f9095ad92dc2af0fea7c3b92af5bfbc89b865ba9aa9b8e96fbbbd89b0ed7a95bd8da4c56390ed9da7f94194afbf92db5d9cb684bbbc3f9a8b9da8bb6a8b91ac84f16a9a97aba8bc65b4bbbfaeca69f8eaaa86dc68a388aaaeec42a8a8bbdab479bc8d9692cc41bbb884abd83e818f82d5e254fbb0fe86f45cf5ae9791ec79bab49faeaa5ff6efe584ee6e98bfab8bc837e2a3; token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiJjZHVfNTMyMDcwNzg0NjAiLCJleHBpcmUiOiIxNjU0Mzk5MjE5NTgzIn0.ReQWb6UHc3ldnj13w5rSAWdbSrPORHQtNSyc0yKk2Ac; Hm_lpvt_03b2668f8e8699e91d479d62bc7630f1=1651807221"
}
data = {
'linkId': '34934736'
}
# res = requests.post('https://dig.chouti.com/link/vote',data=data,headers=header)
# 携带cookie方式二:
res = requests.post('https://dig.chouti.com/link/vote', data=data, headers=header, cookies={'key': 'value'})
print(res.text)
6、发送post请求模拟登陆
# 5 模拟登陆某网站
# data = {
# 'username': '616564099@qq.com',
# 'password': 'lqz123',
# 'captcha': 'kyca',
# 'remember': 1,
# 'ref': 'http://www.aa7a.cn/',
# 'act': 'act_login',
# }
# res = requests.post('http://www.aa7a.cn/user.php', data=data)
# print(res.text)
# print(res.cookies) # 登陆成功返回的cookie,这个cookie是登陆过后的,以后拿着这个cookie就可以模拟登陆后操作
#
# res2 = requests.get('http://www.aa7a.cn/', cookies=res.cookies)
# print('616564099@qq.com' in res2.text) # True
# # 每次都要手动携带cookie,麻烦,使用requests提供的session 方法
session = requests.session()
# 以后需所有请求都用session对象发送,不需要手动处理cookie
data = {
'username': '616564099@qq.com',
'password': 'lqz123',
'captcha': 'kyca',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login',
}
res = session.post('http://www.aa7a.cn/user.php', data=data)
print(res.text)
print(res.cookies) # 登陆成功返回的cookie,这个cookie是登陆过后的,以后拿着这个cookie就可以模拟登陆后操作
res2 = session.get('http://www.aa7a.cn/')
print('616564099@qq.com' in res2.text) # True
7、响应对象
# 6 响应对象
import requests
respone = requests.get('http://www.jianshu.com')
# respone属性
print(respone.text) # 返回响应体的文本内容
print(respone.content) # 返回响应体的二进制内容
print(respone.status_code) # 响应状态码
print(respone.headers) # 响应头
print(respone.cookies) # 响应的cookie
print(respone.cookies.get_dict()) # 响应的cookie转成字典
print(respone.cookies.items())
print(respone.url) # 请求地址
print(respone.history) # 了解---》如果有重定向,列表,放着重定向之前的地址
print(respone.encoding) # 页面的编码方式:utf-8 gbk
# response.iter_content() # content迭代取出content二进制内容,一般用它存文件
8、编码问题(一般不会有问题)
# 请求回来的数据,res.text 打印的时候乱码 ,因为没有指定编码,默认用utf-8 编码 # 解决 response.encoding='gbk'
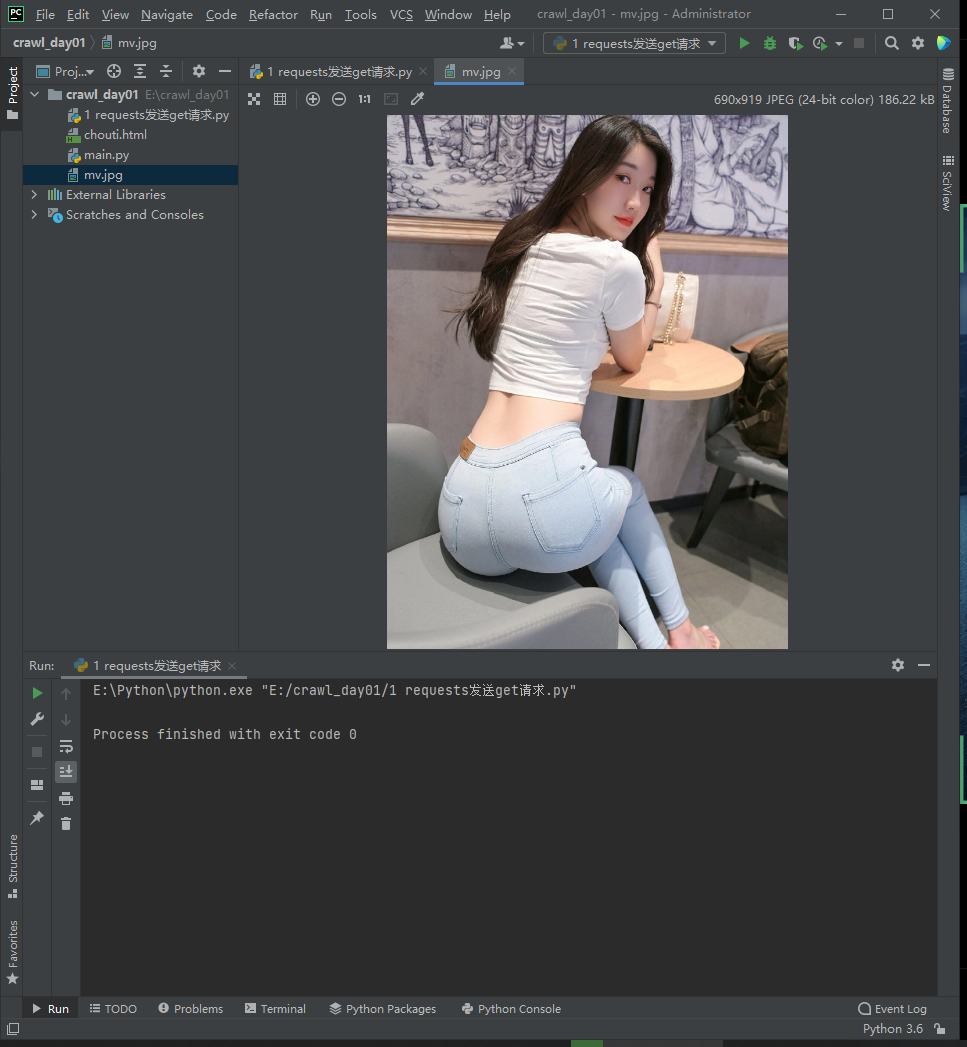
9、获取二进制数据
# 7 下载二进制
header = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36'
}
res = requests.get('https://tva1.sinaimg.cn/mw2000/9d52c073gy1h1v6lmny8nj20j60pjtdh.jpg', headers=header)
with open('mv.jpg', 'wb') as f:
# f.write(res.content) 小文件情况可以
for line in res.iter_content(100):
f.write(line) # 大文件情况 节省内存
10、解析json格式数据
# 8 json格式解析
# 爬取的地址 返回的数据是json格式
import json
data = {
'cname': '',
'pid': '',
'keyword': '上海',
'pageIndex': 1,
'pageSize': 10,
}
# res = requests.post('http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword', data=data)
# j = json.loads(res.text)
# print(j['Table'][0]['rowcount']) # 返回值是列表套字典 索引取值
res = requests.post('http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword', data=data).json()
print(res['Table'][0]['rowcount']) # 结果一样 代码更简洁
11、ssl认证
# 之前网站,有些没有认证过的ssl证书,我们访问需要手动携带证书
# 跳过证书直接访问
import requests
respone=requests.get('https://www.12306.cn',verify=False) #不验证证书,报警告,返回200
print(respone.status_code)
# 手动携带
import requests
respone=requests.get('https://www.12306.cn',
cert=('/path/server.crt',
'/path/key'))
print(respone.status_code)
12、使用代理
# 爬虫,速度很快,超过频率限制---》使用代理,切换ip---》封ip封的也是代理的ip,我的ip没问题
# 9 使用代理
# 收费的(花钱),免费的(不稳定)
# 也自己搭建代理池---》爬一堆免费代理,放到你的本地,每次随机出一个代理用
# 透明和高匿--》透明是否能够看到哪个ip地址使用了代理
proxies = {
'http': '39.103.217.44:59886', # http或https代理
}
respone = requests.get('https://www.baidu.com', proxies=proxies)
print(respone.status_code) # 200 返回200 代表代理成功
# 作业:网上有一个python开源的代理池---》自己搭建起来https://github.com/jhao104/proxy_pool
# 作业:写个django,用户访问就返回用户的ip地址--》放到公网上,用manage.py跑起来---》访问
# 客户端使用request加代理访问你的django,验证代理是否使用成功

相关文章推荐
- 使用xutils发送POST请求,携带json和图片二进制文件数据获取服务器端返回json数据
- PHP使用Http Post请求发送Json对象数据代码解析
- lua发送带http post 带多个参数请求并解析后台响应json数据
- SpringMVC中使用Ajax POST请求以json格式传递参数服务端通过request.getParameter("name")无法获取参数值问题分析
- SpringMVC中使用Ajax POST请求以json格式传递参数服务端通过request.getParameter("name")无法获取参数值问题分析
- js_html_input中autocomplete="off"在chrom中失效的解决办法 使用JS模拟锚点跳转 js如何获取url参数 C#模拟httpwebrequest请求_向服务器模拟cookie发送 实习期学到的技术(一) LinqPad的变量比较功能 ASP.NET EF 使用LinqPad 快速学习Linq
- javaweb使用get与post请求json数据并解析
- HttpClient模拟get,post请求并发送请求参数(json等)
- Android使用HttpClient以Post、Get请求服务器发送数据的方式(普通和json)
- HttpClient模拟get,post请求并发送请求参数(json等)
- 使用RestTemplate发送get请求,获取不到参数的问题
- 在线聊天项目1.4版 使用Gson方法解析Json字符串以便重构request和response的各种请求和响应 解决聊天不畅问题 Gson包下载地址
- [置顶] 针对 android端模拟教务系统登陆,主要针对抓包过程,post,get请求,和解析网页和cookie(一)
- HttpClient模拟get,post请求并发送请求参数(json等)
- [置顶] 针对 android端模拟教务系统登陆,主要针对抓包过程,post,get请求,和解析网页和cookie(二)
- 腾讯云图片鉴黄集成到C# SQL Server 怎么在分页获取数据的同时获取到总记录数 sqlserver 操作数据表语句模板 .NET MVC后台发送post请求 百度api查询多个地址的经纬度的问题 try{}里有一个 return 语句,那么紧跟在这个 try 后的 finally {}里的 code 会 不会被执行,什么时候被执行,在 return 前还是后? js获取某个日期
- 浅谈使用Fiddler工具发送post请求(带有json数据)以及get请求(Header方式传参)
- 模拟表单发送POST,GET请求获取数据
- PHP 使用curl库来发送GET,POST请求,处理json格式数据
- 速战速决 (6) - PHP: 获取 http 请求数据, 获取 get 数据 和 post 数据, json 字符串与对象之间的相互转换