进程线程协程补充、docker-compose一键部署项目、搭建代理池、requests超时设置、认证设置、异常处理、上传文件
2022-05-08 14:37
776 查看
今日内容概要
- 补充:进程,线程,协程
- docker-compose一键部署演示
- 搭建代理池
- requests超时设置
- requests认证设置
- requests异常处理
- requests上传文件
内容详细
1、进程,线程,协程
# 进程,线程,协程 # -进程是资源分配的最小单位 不是程序--》qq,迅雷程序---》运行一个程序,分配内存运行程序 一个py文件不一定是一个进程---》py运行在解释器之上---》一个解释器是一个进程 python中Process类开进程---》又拉起了一个解释器,再执行代码 只有在python上开进程用的多,其他语言一般不开多进程,只开多线程就够了 python有GIL锁的原因,同一个进程下多个线程实际上同一时刻,只有一个线程在执行 cpython解释器不能利用多核优势,只有开都进程才能利用多核优势,其他语言不存在这个问题 # 线程是cpu执行的最小单位 一个进程下可以开启多个线程 8核cpu电脑,充分利用起我这个8核,至少起8个线程,8条线程全是计算--->计算机cpu使用率是100% 如果不存在GIL锁,一个进程下,开启8个线程,它就能够充分利用cpu资源,跑满cpu cpython解释器中好多代码,模块都是基于GIL锁机制写起来的,改不了了---》我们不能有8个核,但我现在只能用1核,----》开启多进程---》每个进程下开启的线程,可以被多个cpu调度执行 cpython解释器:io密集型使用多线程,计算密集型使用多进程 io密集型,遇到io操作会切换cpu,假设你开了8个线程,8个线程都有io操作---》io操作不消耗cpu---》一段时间内看上去,其实8个线程都执行了 计算密集型,消耗cpu,如果开了8个线程,第一个线程会一直占着cpu,而不会调度到其他线程执行,其他7个线程根本没执行,所以我们开8个进程,每个进程有一个线程,8个进程下的线程会被8个cpu执行,从而效率高 由于进程是资源分配的最小单位,起了一个进程,定义了变量,这个变量在多个线程下是共享的 进程间通信---IPC:进程间数据隔离,所以需要通信---》Queue(进程queue)---》一般使用消息队列--》redis 同一个进程下多线程数据是共享的 多线程同时操作一个数据,数据错乱,并发安全问题--->加锁--》让原本并发的操作,变成串行,牺牲效率,保证安全---》通过线程queue也可以避免并发安全的问题,所有queue的本质就是锁 互斥锁 ---》效率高低 --》自旋锁 死锁问题:a线程拿了a锁,想要拿b锁,b线程拿了b锁,想拿a锁 递归锁(可重入锁):让一把锁可以重复被同一个线程拿到 a和b都是一个锁,a可重入锁 多进程下的不同线程要通信如何做 等同于进程间通信 # 协程是单线程下程序层面控制任务的切换实现并发 本身cpu遇到io会切换到另一条线程执行---》线程间切换要保存线程状态,后来再切回来执行,要恢复状态,操作系统层面操作,消耗资源 程序员想:程序层面自己切换,task1(),task2(),当task1执行中遇到io操作,程序层面切换到task2中执行,操作系统只看到一条线程在执行,都在执行计算操作,操作系统层面就不会切,看到效果,一个时间段内,执行了很多任务,但都是在同一条线程下执行的 协程也只是针对io密集型的操作才效率高,如果纯计算密集型,它就不切,效率就不高 使用协程,遇到io就会切换---》task1(),task2(),当task1执行中遇到io操作,程序层面切换到task2中执行但是task2的io还没结束,不停来回切换空耗cpu # GIL:cpython解释器好多都是基于GIL锁机制写起来的,改不了了 全局解释器锁:最早,都是单核cpu,python是解释型语言,有垃圾回收机制---》开了多线程,多个线程引用了这个变量---》要做垃圾回收(垃圾回收线程)---》检索引用计数是不是0,必须要保证在垃圾回收线程在执行的时候,其它线程不能执行的,才能顺利做垃圾回收---》当时又是单核cpu,不存在多核的情况,最简单的方法,搞一把大锁,在同一个时刻,只要拿到gil锁,线程才能执行---》随着多核cpu的出现--->没办法了,作者写了开启多进程的方案来解决 cpu不能充分利用的问题 # 了解一下 go语言代码使用c调用 https://zhuanlan.zhihu.com/p/355538331 # 有了GIL锁,为什么还要互斥锁 同一时刻只有一个线程在执行,还会出并发安全的问题吗? 已经变成串行了,怎么还会有并发安全问题? 比如两个线程要把a=a+1,a一开始等于0 第一个线程取到了a,计算完了 a现在是1 ,还没赋值回顾 第二个线程取到了a,计算问了,a现在是1,线程切换回第一条线程,a变成了1 # 你用web框架写东西,用过多线程或者多进程吗? 可能用celery使用过多进程 如何保证项目的并发量?--》前面的web服务器干的---》wsgiref---》uwsgi使用c写的,c开启进程,线程,在c进程中执行django,执行python的代码 uwsgi是进程+线程模型 uwsgi+gevent 是进程+线程模型+协程模型
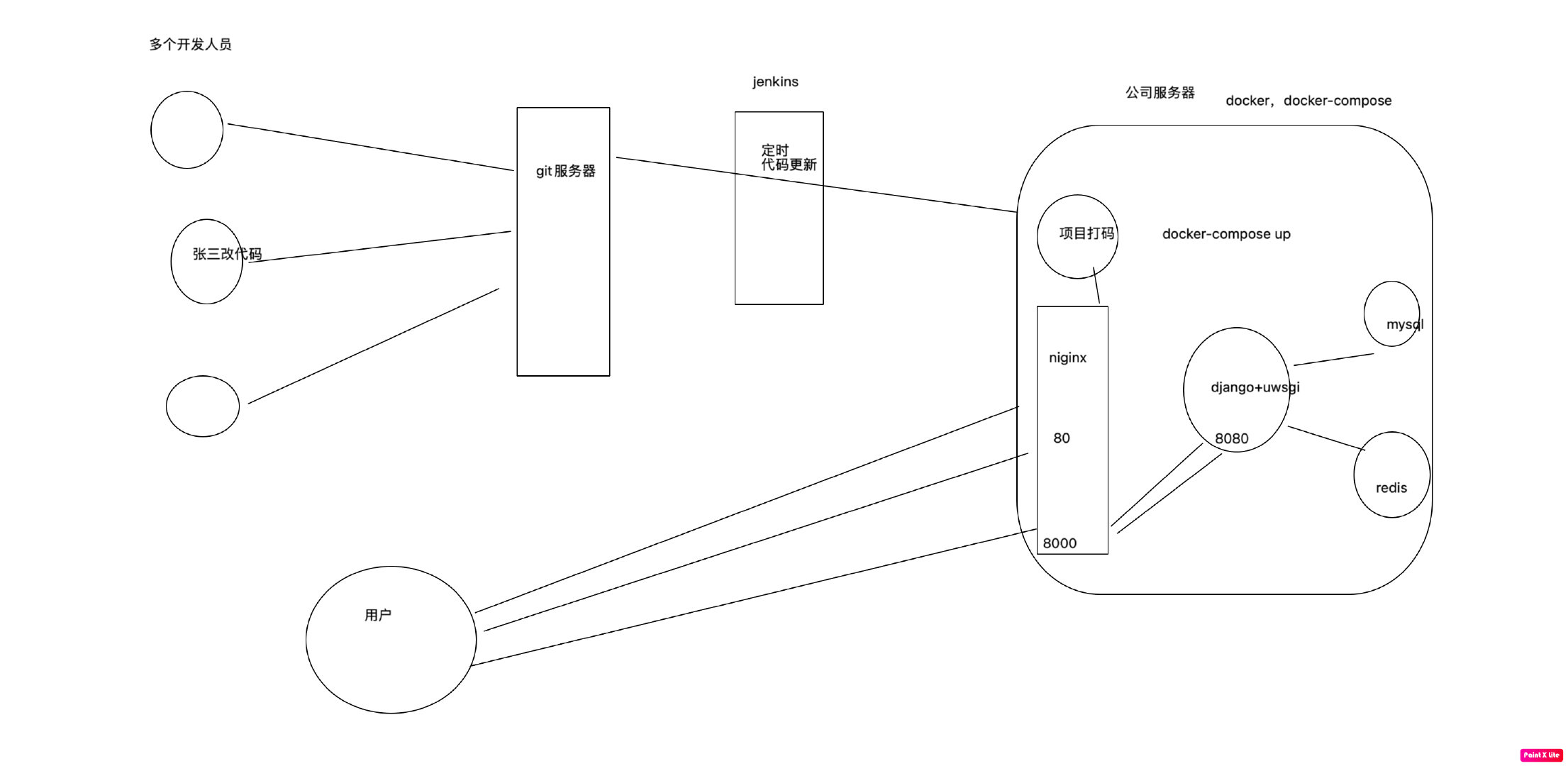
2、docker-compose一键部署演示
### 1 新的centos机器,安装docker和docker-compost
# 安装依赖
yum install -y yum-utils device-mapper-persistent-data lvm2
# 设置yum源
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# 安装docker
yum install -y docker-ce
# 设置开机启动
systemctl enable docker
# 启动 Docker
systemctl start docker
# 查看版本
docker version
## 安装docker-compose
# 下载
curl -L https://get.daocloud.io/docker/compose/releases/download/v2.5.0/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
# 赋予执行权限
chmod +x /usr/local/bin/docker-compose
# 查看版本
docker-compose --version
### 2 下载代码并启动
# 下载git
yum install git -y
# 下载代码
git clone https://gitee.com/deity-jgx/luffy.git
# 进入目录
cd luffy
# 运行
docker-compose up
"""
https://gitee.com/liuqingzheng/luffy
### 修改 luffycity/src/assets/js/settings.js:
export default {
base_url: "http://139.224.254.58:8000(改为自己的服务器公网IP )/api/v1/"
}
"""
### 3 导入测试数据
# 把luffy下luffy_api下的luffy.sql导入luffy库
3、搭建代理池
# https://github.com/jhao104/proxy_pool python的爬虫+flask写的 本质使用爬虫技术爬取免费的代理,验证--》requests模块验证---》存到redis中 起一个web服务器,只要访问一个地址,他就随机给你一个ip地址 # 步骤: 第一步:git clone git@github.com:jhao104/proxy_pool.git 第二步:安装依赖:pip install -r requirements.txt 第三步: 修改代码,修改配置 # setting.py 为项目配置文件 # 配置API服务 HOST = "0.0.0.0" # IP PORT = 5000 # 监听端口 # 配置数据库 DB_CONN = 'redis://:pwd@127.0.0.1:8888/0' # 配置 ProxyFetcher PROXY_FETCHER = [ "freeProxy01", # 这里是启用的代理抓取方法名,所有fetch方法位于fetcher/proxyFetcher.py "freeProxy02", # .... ] 第四步:启动爬虫 python3 proxyPool.py schedule 第五步:启动服务 # 启动webApi服务 python proxyPool.py server
### 代理使用测试
import requests
# http://127.0.0.1:5010/get/
ip = "http://" + requests.get('http://139.155.237.73:5010/get/').json()['proxy']
print(ip)
proxies = {
'http': ip,
}
res = requests.get('http://47.104.165.24:8001/check/', proxies=proxies)
print(res.text)
4、requests超时设置
import requests
# http://127.0.0.1:5010/get/
ip = "http://" + requests.get('http://139.155.237.73:5010/get/').json()['proxy']
print(ip)
proxies = {
'http': ip,
}
res = requests.get('http://47.104.165.24:8001/check/', proxies=proxies, timeout=1)
print(res.text)
5、requests认证设置
# 这种很少见,极个别公司内部可能还用这种
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('xxx', auth=HTTPBasicAuth('user', 'password'))
print(r.status_code)
# HTTPBasicAuth可以简写为如下格式
import requests
r = requests.get('xxx', auth=('user', 'password'))
print(r.status_code)
6、requests异常处理
from requests.exceptions import * # 可以查看requests.exceptions获取异常类型
try:
r = requests.get('http://www.baidu.com', timeout=0.00001)
except ReadTimeout:
print('===:')
# except ConnectionError: #网络不通
# print('-----')
# except Timeout:
# print('aaaaa')
except Exception:
print('Error')
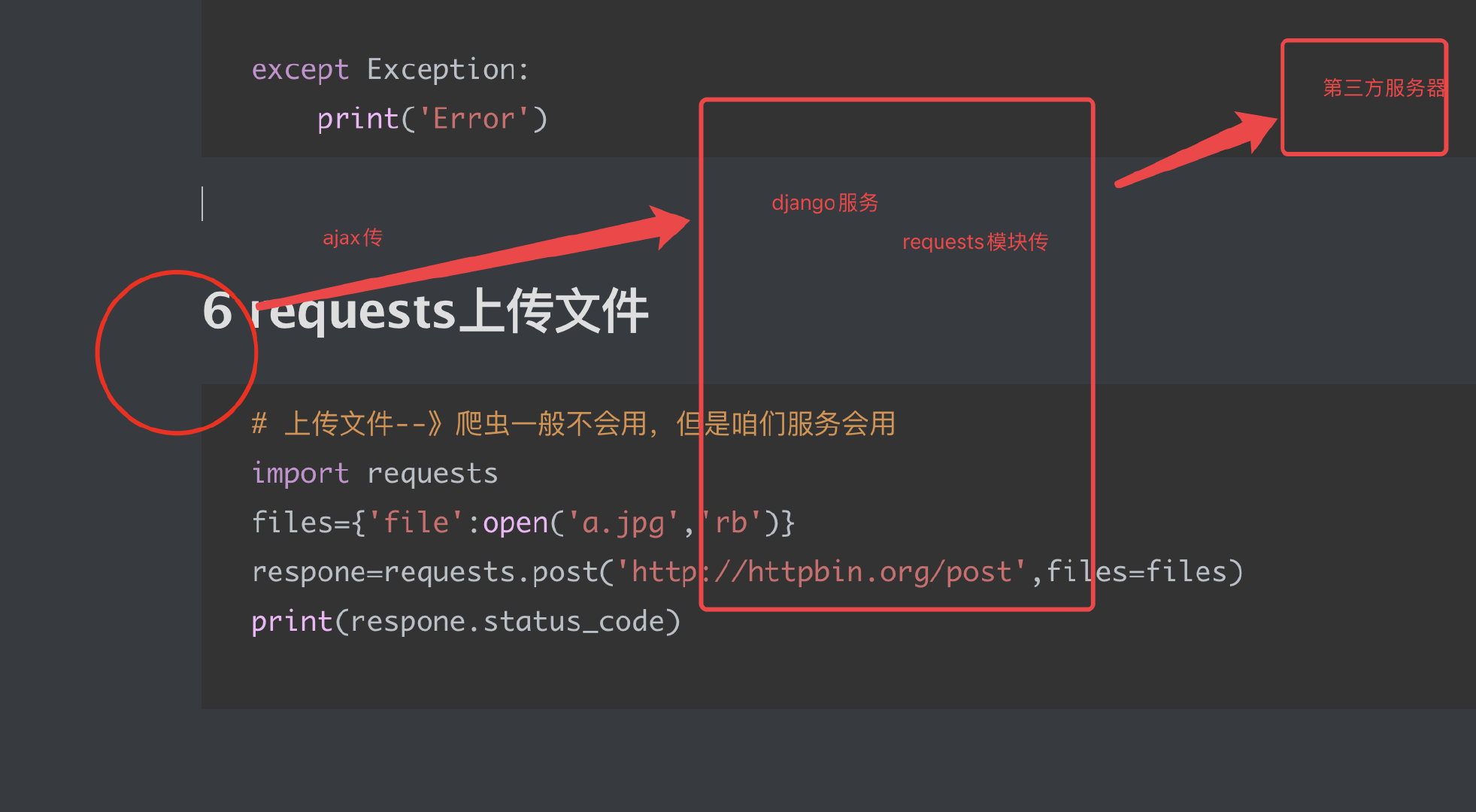
7、requests上传文件
# 上传文件--》爬虫一般不会用,但是咱们服务会用
import requests
files = {'file': open('a.jpg', 'rb')}
respone = requests.post('http://httpbin.org/post', files=files)
print(respone.status_code)
# 咱们django项目
你们公司项目,使用了第三方服务,第三放服务提供了api接口,没提供sdk
就要使用request发送请求,获取数据
# 前端提交一个长链地址 www.cnblogs.com/liuqingzheng/p/233.html--->转成短链--》x.com/asdf--->存到自己数据库中
# 专门服务,处理长连转短链(go,java)---》接口--》post,带着地址---》返回json,短链地址

相关文章推荐
- 通过docker-compose一键搭建Nginx带动的FDFS服务 分布式文件上传系统
- 基于maven学习SpringMVC笔记包含环境搭建、springMVC特有的方式收参,流程跳转、参数传递、注解开发、文件上传下载、拦截器、全局异常处理
- Python基础学习(5)网络编程socket、文件上传、粘包问题、socketserver、IO多路复用、线程与进程、进程池、线程池、上下文管理、协程
- Nginx部署rails项目要点,大文件上传设置(413)
- 20.springboot项目部署到linux服务器文件上传临时路径处理问题
- 后台上传大文件超时处理
- DIOCP开源项目-利用队列+0MQ+多进程逻辑处理,搭建稳定,高效,分布式的服务端
- jenkins设置插件升级代理后构建项目上传文件到artifactory时遇到的413错误
- 在可以调用 OLE 之前,必须将当前线程设置为单线程单元(STA)模式。请确保您的 Main 函数带有 STAThreadAttribute 标记。 只有将调试器附加到该进程才会引发此异常
- springmvc 异常处理、文件上传以及拦截器相关知识
- 学习使用Docker、Docker-Compose和Rancher搭建部署Pipeline(一)
- java项目部署异常解析及处理方案
- 借助webview实现apk文件转换之环境部署与项目搭建
- (原创)项目部署-Tomcat设置默认访问项目及项目重复加载问题处理
- 进程(process)和线程(thread)及其在项目中的应用 协程
- 基于docker环境,搭建 jetty环境, 部署java项目
- Android Studio 配置git目录上传项目到Github并设置忽略文件
- Docker 使用docker-compose部署项目
- 如何使用Docker、Docker-Compose和Rancher搭建部署Pipeline(三)
- 设置Windows下的Core文件输出(监控异常进程)