HDFS常用API
2021-09-22 18:11
1291 查看
在pom.xml中导入依赖包
<dependencies> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.6</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.6</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.6</version> </dependency> <!-- https://mvnrepository.com/artifact/junit/junit --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.3</version> </dependency> </dependencies>
hdfs连接Java
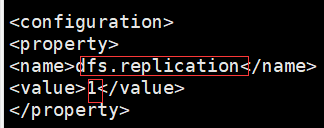
1.先获取配置文件(hdfs-site.xml)
Configuration cg = new Configuration(); 导入的是import org.apache.hadoop.conf.Configuration;
cg.set("dfs.replication","1"); 1是备份数量
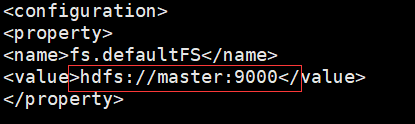
2.获取连接地址(core-site.xml)
URI uri = new URI("hdfs://master:9000");
3.创建(获取)hdfs文件管理系统的对象,同过对象操作hdfs
FileSystem fs = FileSystem.get(uri, cg);
常用HDFSAPI:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.Before;
import org.junit.Test;
import java.io.*;
import java.net.URI;
public class HdfsApi {
FileSystem fs;
@Before
public void main() throws Exception {
Configuration cg = new Configuration();
cg.set("dfs.replication", "1");
URI uri = new URI("hdfs://master:9000");
fs = FileSystem.get(uri, cg);
}
@Test
public void mk() throws IOException {
boolean mk = fs.mkdirs(new Path("/test"));
}
@Test
public void del() throws IOException {
//false表示不迭代删除也可以不加,true可以进行多目录迭代删除
boolean del = fs.delete(new Path("/test"),false);
System.out.println(del);
}
@Test
public void listStatus() throws IOException { //对比图在下
//查看目录下文件列表
FileStatus[] fileStatuses = fs.listStatus(new Path("/data/data"));
System.out.println(fileStatuses); //[Lorg.apache.hadoop.fs.FileStatus;@106cc338
System.out.println("-------------------------------");
for (FileStatus fileStatus : fileStatuses) {
System.out.println(fileStatus.getLen()); //文件大小 以B字节为单位
System.out.println(fileStatus.getReplication()); //副本个数
System.out.println(fileStatus.getPermission()); //读写状态
System.out.println(fileStatus.getBlockSize()); //固定的一个block大小128MB
System.out.println(fileStatus.getAccessTime()); //创建文件时的时间戳
System.out.println(fileStatus.getPath()); //文件路径
System.out.println("-----------------");
}
@Test
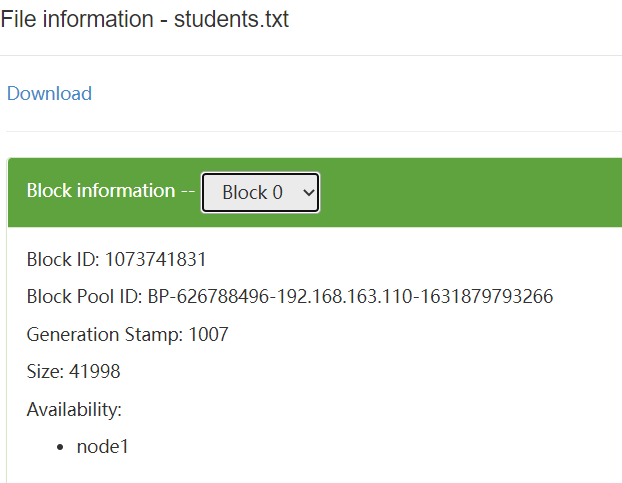
public void listBlockLocation() throws IOException { //对比图在下
BlockLocation[] fbl =
fs.getFileBlockLocations(
new Path("/data/data/students.txt"),0,1000000000);
for (BlockLocation bl : fbl) {
String[] hosts = bl.getHosts();
for (String host : hosts) {
System.out.println(host);
} //node1 表示文件存在node1,因为文件小于一个block,所以这里只存在一个节点
System.out.println(bl.getLength()); //41998 size大小
String[] names = bl.getNames();
for (String name : names) {
System.out.println(name);
} //192.168.163.120:50010 node1的地址
System.out.println(bl.getOffset()); //0 偏移量
String[] topologyPaths = bl.getTopologyPaths();
for (String topologyPath : topologyPaths) {
System.out.println(topologyPath);
} // /default-rack/192.168.163.120:50010
}
}
@Test
public void open() throws IOException {
FSDataInputStream open = fs.open(new Path("/data/data/students.txt"));
BufferedReader br = new BufferedReader(new InputStreamReader(open)); //因为文件中有中文,所以将字节流转为字符流来读取
String len;
while ((len=br.readLine())!=null){
System.out.println(len);
}
br.close();
}
@Test
public void create() throws IOException {
FSDataOutputStream fos = fs.create(new Path("/data/data/test.txt"));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(fos));
bw.write("你好");
bw.write("世界");
bw.newLine();
bw.write("我和我的祖国");
bw.flush();
bw.close();
}
}


相关文章推荐
- junit及HDFS API常用方法
- 4. HDFS 常用Java API 总结
- hdfs 常用java API---代码篇(二)
- HDFS_API入门demo(HDFS常用操作命令)
- HDFS常用的文件API操作
- 常用HDFS的API操作
- 常用HDFS的API操作
- hdfs常用API和putMerge功能实现
- 【HDFS】常用API
- hdfs常用API和putMerge功能实现
- 常用HDFS的API操作
- hadoop实战之HDFS常用JavaAPI
- HDFS常用的文件API操作
- hdfs常用api
- HDFS API 学习:几个常用的API
- 第二篇:Hadoop HDFS常用JAVA api操作程序
- Hadoop 第五课 几个文件搞定HDFS常用的Java Api
- HDFS常用API
- HDFS(三):常用客户端API及IO操作
- HDFS的常用的JavaAPI操作