利用Python发现60%以上女孩的罩杯是B,但A穿衣却是百搭且很高级
2022-01-14 13:48
1236 查看
最近常听到说女生的
A罩杯,穿衣百搭且很高级!
今天,我们就爬取京东商城某文胸品牌不同
size的大致销售情况,来看看当前什么尺码才是主流吧!
目录

1. 需求梳理
本文比较简单,单纯对京东评论数最多的某文胸品牌不同
size的商品评论数进行采集,然后统计出不同
size的占比。
由于京东没有类似销量(或多少人付款)等数据,我们这里仅用评论数做对比维度。关于评论数的获取,我们这里就不展开介绍了。
通过在京东进行商品类型选择
内衣-文胸-适用人群 青年,再按照评论数排序,我们可以得到排名靠前的商品列表。由于前2个都是均码无尺寸的,第3个是文胸洗衣袋(也是均码无尺寸),故而我们选择了第4个商品。

寻找目标品牌
然后,我们直接点击进入到第4个商品的详情页面,发现存在很多7种颜色和10种尺寸,这组合有点多啊。
为了更好的获取每件商品的评论数据,我们这里需要先获取每个商品的
productId。于是,我们
F12进入到开发者模式,在元素页搜索其中一个商品id最终发现了存放全部商品id的地方如下:(可以通过正则解析出来)
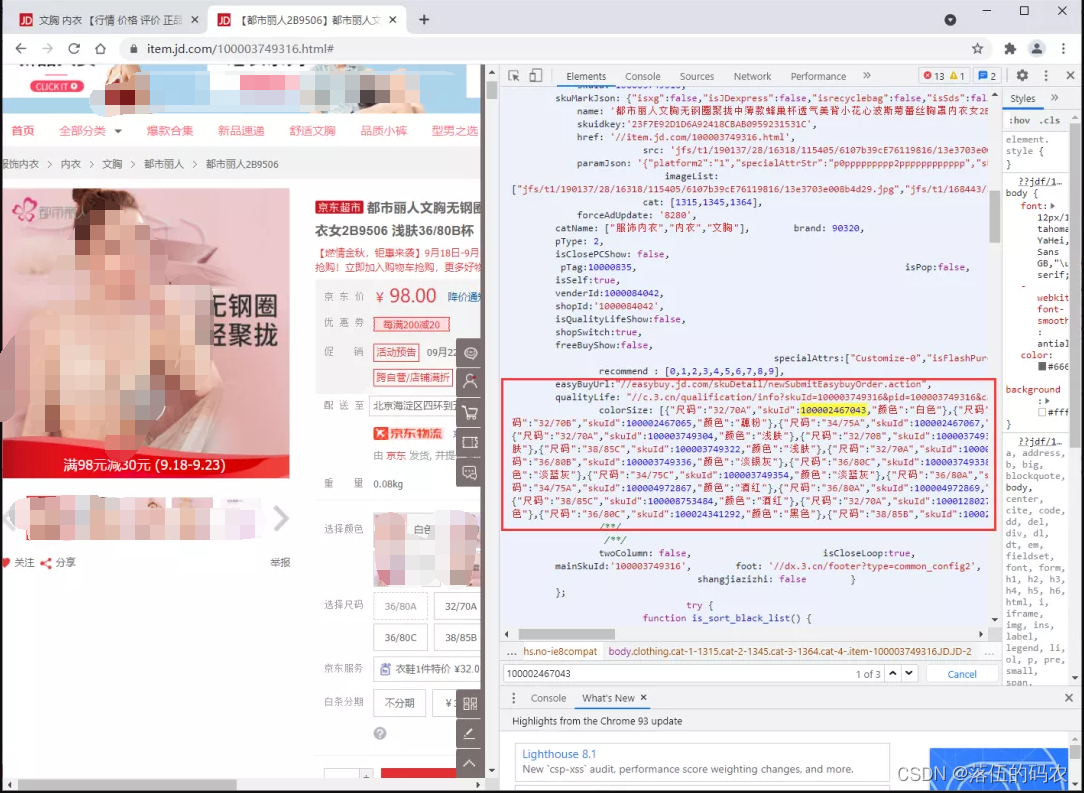
color&size
既然可以获取全部的
商品id,那么通过
商品id即可调用
评论接口获取对应商品的评论数据了,我们就编码走起!

2. 数据采集
数据采集部分,先用正则获取全部的商品id,然后通过商品id获取全部商品id对应的评论数据,那么需要的数据就齐活了。
获取全部商品id
import requests
import re
import pandas as pd
headers = {
# "Accept-Encoding": "Gzip", # 使用gzip压缩传输数据让访问更快
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36",
# "Cookie": cookie,
"Referer": "https://item.jd.com/"
}
url= r'https://item.jd.com/100003749316.html'
r = requests.get(url, headers=headers, timeout=6)
text = re.sub(r'\s','',r.text)
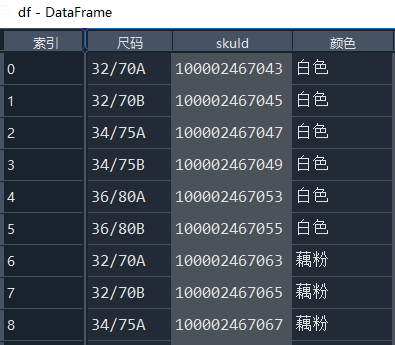
colorSize = eval(re.findall(r'colorSize:(\[.*?\])', text)[0])
df = pd.DataFrame(colorSize)
获取商品id对应评论数据
# 获取评论信息
def get_comment(productId, proxies=None):
# time.sleep(0.5)
url = 'https://club.jd.com/comment/skuProductPageComments.action?'
params = {
'callback': 'fetchJSON_comment98',
'productId': productId,
'score': 0,
'sortType': 6,
'page': 0,
'pageSize': 10,
'isShadowSku': 0,
'fold': 1,
}
# print(proxies)
r = requests.get(url, headers=headers, params=params,
proxies=proxies,
timeout=6)
comment_data = re.findall(r'fetchJSON_comment98\((.*)\)', r.text)[0]
comment_data = json.loads(comment_data)
comment_summary = comment_data['productCommentSummary']
return sum([comment_summary[f'score{i}Count'] for i in range(1,6)])
df_commentCount = pd.DataFrame(columns=['skuId','commentCount'])
proxies = get_proxies()
for productId in df.skuId[44:]:
df_commentCount = df_commentCount.append({
"skuId": productId,
"commentCount": get_comment(productId, proxies),
},
ignore_index=True
)
df = df.merge(df_commentCount,how='left')
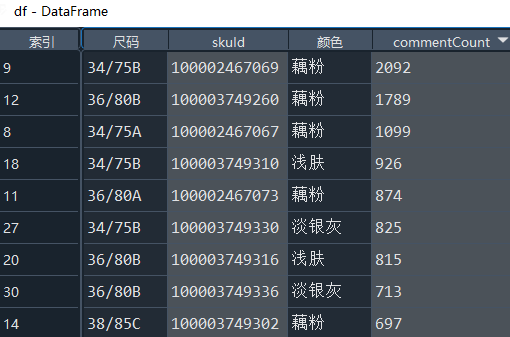

3. 统计展示
我们先将尺码中的
ABC..罩杯部分单独成列
df['cup'] = df['尺码'].str[-1]
开始我们的简单统计展示吧
先看数据信息概况
>>> df.info() <class 'pandas.core.frame.DataFrame'> Int64Index: 64 entries, 0 to 63 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 尺码 64 non-null object 1 skuId 64 non-null object 2 颜色 64 non-null object 3 commentCount 64 non-null object 4 cup 64 non-null object dtypes: object(5) memory usage: 3.0+ KB
3.1. cup分布
不过我们采集的数据中只划分了A-B-C三种cup。。
cupNum = df.groupby('cup')['commentCount'].sum().to_frame('数量')
cupNum
| cup | 数量 |
|---|---|
| A | 6049 |
| B | 11618 |
| C | 4076 |
import matplotlib.pyplot as plt
from matplotlib import font_manager as fm
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
labels = cupNum.index
sizes = cupNum['数量']
explode = (0, 0.1, 0)
fig1, ax1 = plt.subplots(figsize=(6,5))
patches, texts, autotexts = ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True, startangle=90)
ax1.axis('equal')
# 重新设置字体大小
proptease = fm.FontProperties()
proptease.set_size('large')
plt.setp(autotexts, fontproperties=proptease)
plt.setp(texts, fontproperties=proptease)
ax1.set_title('cup 分布')
plt.show()
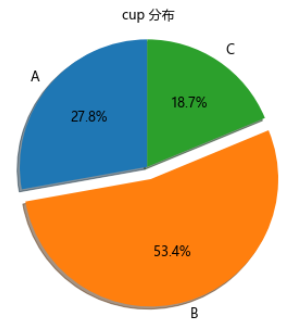
cup分布
我们可以看到,高达
53.4%的买家是
B-cup,其次才是
A-cup占比
27.8%。
3.2. color分布
colorNum = df.groupby('颜色')['commentCount'].sum().to_frame('数量')
colorNum
| 颜色 | 数量 |
|---|---|
| 浅肤 | 3627 |
| 淡蓝灰 | 3058 |
| 淡银灰 | 3837 |
| 白色 | 1439 |
| 藕粉 | 8286 |
| 酒红 | 1429 |
| 黑色 | 67 |
我们可以看到,藕粉色最多而且遥遥领先,其次是淡银灰、浅肤和淡蓝色。
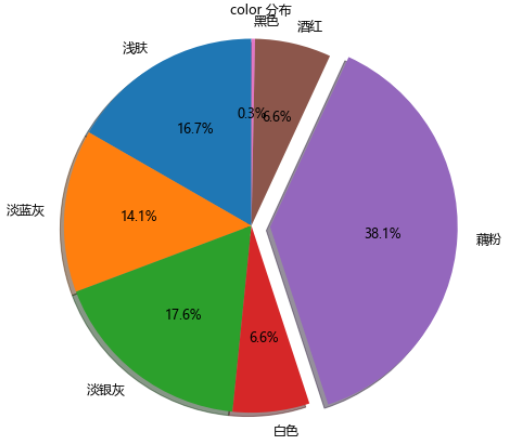
color分布
以下是占比最高高达
38.1%的藕粉色

藕粉色:来自京东

4. 就这样吧
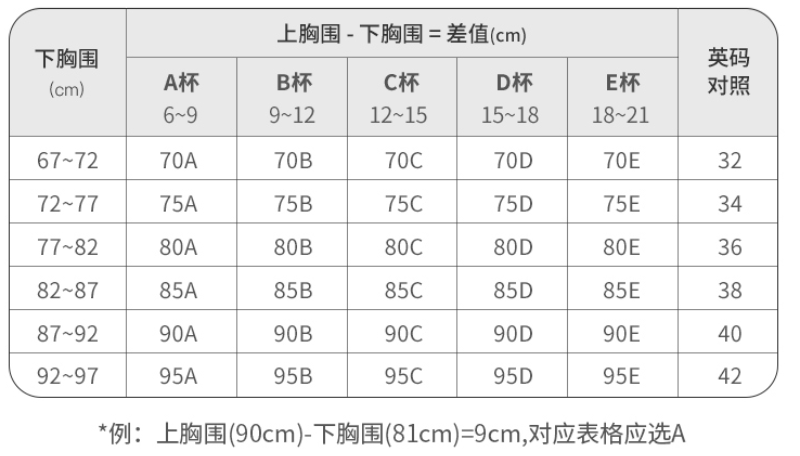
我们看到最多的
34/75B,
34就是英码对照,
75可以理解为下胸围长(其实这里的34和75可以理解为一样的含义),
B则是
cup。
关于
cup和胸围对照表,参考:
以上就是本次全部内容,样本量较小,不做考究,仅供娱乐哈!
5.学习资源

相关文章推荐
- 利用Python实现智能五子棋,实现之后发现我玩不赢它
- Effective TensorFlow Chapter 9: TensorFlow模型原型的设计和利用python ops的高级可视化
- 利用Python爬取500万以上的国产自拍小电影哦!
- 一键获取隐藏Wi-Fi SSID:利用Python和Scapy发现隐藏无线热点
- 利用python进行数据分析-NumPy高级应用
- Python中利用列表推导式实现矩阵置换时发现的"问题"
- 利用Python处理Excel数据(个人平时用的时候总结的,以后发现新的方法会继续添加)
- Python高级特性:利用类构造及析构原理实现单实例模式
- Python利用Zabbix API定时报告存在报警的机器 推荐
- Python高级阶段测试
- 智能客服 利用python运行java代码
- Python爬虫入门四之Urllib库的高级用法
- 【Python】[面向对象高级编程] 多成继承,定制类,使用枚举
- 前女友发来加密的 “520快乐.pdf“,我用python破解开之后,却发现。。。
- caffe 利用python绘制loss曲线以及accuracy曲线
- python高级特性 - 迭代
- zabbix利用python脚本发送报警邮件的方法
- 利用Python进行文章特征提取(一)
- 利用python爬取什么值得买上面的爆料信息
- 利用python实现Jenkins自动化部署代码