数据分析小白入门篇,机器学习中必须要会用的模块
想要看更加舒服的排版、更加准时的推送
关注公众号“不太灵光的程序员”
每日八点有干货推送
公众号“不太灵光的程序员” 同时发布《机器学习中必须要会用的模块》
什么是序列化?
序列化:是对象从内存中的运行状态转化成可存储或传输状态的过程称之为序列化。
反序列化:是对象从存储或传输状态转化成可在内存中的运行状态的过程称之为反序列化。
序列化模块经常被使用,在许多场景中我们需要将当前程序运行的对象存储起来或者传输给别的程序,比如:
使用消息队列进行通信是需要将字典列表等容器对象序列化成字符串进行传输;
运行一个好事程序你需要中断它,下次从中断的地方继续执行,就需要对过程中的对象进行序列化,存储到磁盘中,这里听起来数据持久化。
python中常见的序列化模块
python中常见的序列化模块有 json 、 pickle 和 marshal。
marshal模块
marshal模块主要用于支持读取和编写.pyc文件的Python模块的“伪编译”代码。
marshal模块可以序列化大部分数据对象、函数、类,但是对于存在递归调用的函数、字典、列表、集合是不能被序列化的,这些对象可能导致无限循环。
json模块
json是一种文本序列化格式,易于人阅读和编写。
json模块只可以序列化python内置数据类型对象,不能序列化其他的函数和类。
pickle模块
pickle模块是python中推荐的序列化模块,可以序列化数据对象、函数、类。
pickle模块与marshal模块的区别:
marshal模块不能序列化递归对象,pickle模块可以,这是在pickle模块的实现中对同一对象的引用只序列化一次,marshal是都序列化。
marshal模块不能序列化用户定义的类及其实例。 pickle模块可以序列化和反序列化类和实例,但是类定义必须是可导入的,并且与对象存储时位于同一模块中。
marshal模块没有python版本兼容,pickle模块序列化后的数据是向后兼容的。
pickle模块与json模块的区别:
序列化对象范围不同,pickle模块可以序列化任意的类或函数,json模块只能序列化内置的类型类。
序列化后的数据格式不同,json模块是序列化成字符串存储,pickle是二进制序列化格式。
pickle是不安全的,反序列化不安全的二进制数据可能会造成危险,而json只序列化数据类型不会造成执行漏洞。
所以 pickle 模块是python中推荐的序列化模块。
测试代码
# coding=gbk
import pickle
import marshal
import json
def add(a, b):
return a+b
def fib_recur(n):
assert n >= 0, "n > 0"
if n <= 1:
return n
return fib_recur(n-1) + fib_recur(n-2)
data_dict = {"a": 1, "b": 2}
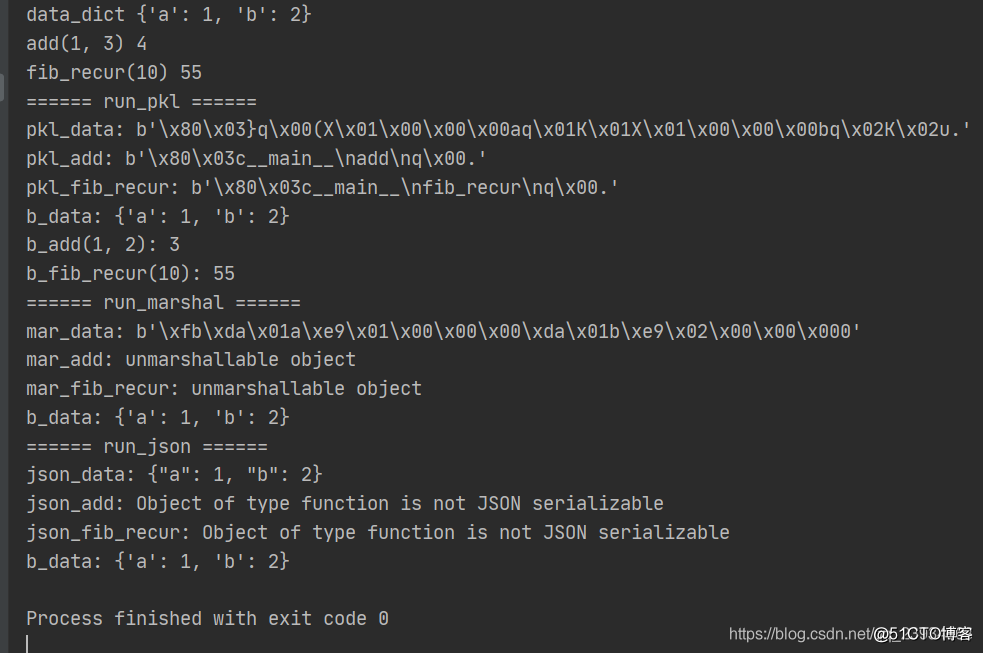
def run_pkl():
print("====== run_pkl ======")
pkl_data = pickle.dumps(data_dict)
pkl_add = pickle.dumps(add)
pkl_fib_recur = pickle.dumps(fib_recur)
print("pkl_data:", pkl_data)
print("pkl_add:", pkl_add)
print("pkl_fib_recur:", pkl_fib_recur)
b_data = pickle.loads(pkl_data)
b_add = pickle.loads(pkl_add)
b_fib_recur = pickle.loads(pkl_fib_recur)
print("b_data:", b_data)
print("b_add(1, 2):", b_add(1, 2))
print("b_fib_recur(10):", b_fib_recur(10))
def run_marshal():
print("====== run_marshal ======")
mar_data = marshal.dumps(data_dict)
print("mar_data:", mar_data)
try:
mar_add = marshal.dumps(add)
except Exception as e:
print("mar_add:", e)
try:
mar_fib_recur = marshal.dumps(fib_recur)
except Exception as e:
print("mar_fib_recur:", e)
b_data = marshal.loads(mar_data)
print("b_data:", b_data)
def run_json():
print("====== run_json ======")
json_data = json.dumps(data_dict)
print("json_data:", json_data)
try:
json_add = json.dumps(add)
except Exception as e:
print("json_add:", e)
try:
json_fib_recur = json.dumps(fib_recur)
except Exception as e:
print("json_fib_recur:", e)
b_data = json.loads(json_data)
print("b_data:", b_data)
if __name__ == "__main__":
print("data_dict", data_dict)
print("add(1, 3)", add(1, 3))
print("fib_recur(10)", fib_recur(10))
run_pkl()
run_marshal()
run_json()
推荐阅读:


- 普通码农入门机器学习,必须掌握这些数据技能
- pyhton中pandas数据分析模块快速入门(非常容易懂)
- (4篇长图带你机器学习入门)数据分析入门_PART4统计基础_CH011 一元多元线性回归
- (4篇长图带你机器学习入门)数据分析入门_PART4统计基础_CH012 KNN最邻近分类
- (4篇长图带你机器学习入门)数据分析入门_PART4统计基础_CH014蒙特卡罗模拟
- 做运营,你必须要掌握的数据分析入门知识
- 小白的Pyhon数据分析之路03——Pandas模块学习(二)
- 小白的Pyhon数据分析之路05——Pandas模块学习(四)
- 普通码农入门机器学习,必须掌握这些数据技能
- 入门机器学习,必须掌握这些数据技能
- 机器学习-实战-入门-iris数据分析
- 数据分析、数据挖掘、机器学习、神经网络、深度学习和人工智能概念区别(入门级别)
- 数据分析与机器学习入门
- 视频教程-数据分析小白入门指南-Python
- 数据分析入门-机器学习部分
- 小白的Pyhon数据分析之路04——Pandas模块学习(三)
- 新手小白的第一篇博客——机器学习入门
- 数据分析 NO.10 《Python从入门到实践》2-7章(含练习题)
- 小白学数据分析----->付费渗透率再研究
- 数据分析(入门篇)-第一章-高效处理千万数据-Part1(Microsoft Access数据库)