抛开炒作看知识图谱,为什么现在才爆发?
知识图谱正在被大肆炒作,Gartner 的 2018 年新兴技术炒作周期中就包含了知识图谱。我们甚至不必等 Gartner 宣布 2018 年是“知识图谱年”,与活跃在这个领域的所有人一样,我们都看到了机会,但也看到了威胁:伴随炒作而来的是混乱。
知识图谱是真实的,它们至少已经存在了 20 年。知识图谱的原始定义是关于知识表示和推理,如受控词汇表、分类法、模式和本体之类的东西,它们都是建立在标准和实践的语义 Web 基础之上。
那么,有哪些东西发生了变化?为什么 Airbnb、亚马逊、谷歌、LinkedIn、Uber 和 Zalando 等公司的核心业务都应用了知识图谱?为什么亚马逊和微软加入了图数据库提供商的行列?你又能做些什么?
当知识图谱还没那么酷的时候
知识图谱听起来似乎很酷,但它们究竟是什么?问这样的问题似乎有点幼稚,但要构建知识图谱,首先要正确地定义它们。从分类法到本体论——本质上是不同复杂性的模式和规则,而这些就是人们多年来一直在做的事情。
用于编码这些模式的 RDF 标准就具有图的结构。因此,将基于图结构编码的知识称为“知识图谱”是件很自然的事情,而相应的数据建模者就被称为知识工程师或本体论者。
知识图谱有很多应用——从编目项目到数据集成和 Web 发布,再到复杂的推理。这个领域的一些佼佼者包括 schema.org、Airbnb、亚马逊、Diffbot、谷歌、LinkedIn、Uber 和 Zalando。这就是为什么经验丰富的知识图谱人士对炒作嗤之以鼻。
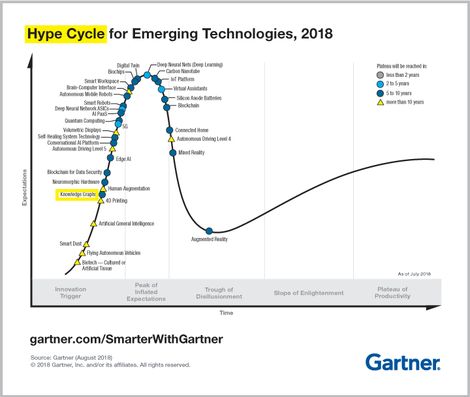
知识图谱现在已经出现在新兴技术的炒作周期中。对于拥有超过 20 年历史的技术来说,还算不错。
与其他数据建模一样,这是一项艰难而复杂的任务。它必须考虑到很多利益相关者和世界观、管理起源和模式漂移等。加上混合推理和 Web 规模,事情很容易失控,这就是为什么这种方法直到现在仍然没能成为最流行的方法。
另一方面,无模式却一直很流行。无模式可以让你快速入门,而且至少在某种程度上,它更简单、更灵活。但无模式可能带有欺骗性,因为不管是什么领域,都存在模式。读时模式(schema-on-read)?或许可以。那么完全无模式呢?
你可能不会事先对你的模式有充分的了解。它可能很复杂,而且会发生变化,但它一定存在。因此,忽略或淡化模式并不能解决任何问题,只会让事情变得更糟。问题将会潜伏起来,并花费你更多的时间和金钱,因为它们会给开发应用程序并获得对模糊数据洞察力的开发人员和分析人员带来阻力。
关键在于不是要抛弃模式,而是让它发挥作用,让它变得灵活和可互换。RDF 就很好,因为它也是数据交换标准化格式(如 JSON-LD)的基础。顺便说一下,RDF 还可以用于轻量级模式和无模式方法以及数据集成。
图谱的知识输入和输出
那么,这项 20 年的老技术为何出现在炒作周期的新兴技术中?炒作是真实存在的,而出现炒作也不是没有原因的。这与迅速崛起的人工智能炒作一样:并不是因为方法本身发生了变化,更多的是因为数据和算力的发展让它可以大规模运作。
此外,AI 本身也起到一定作用。或者,更确切地说,是如今被炒得火热的自下而上、基于机器学习的 AI。知识图谱本质上也是另外一种 AI,但不是那种被大肆宣传的 AI,而是那种象征性的、自上而下的、基于规则的、迄今为止仍然不是很流行的那种。
并不是说这种方法就没有局限性。对复杂的领域知识进行编码,并进行大规模推理是很困难的事情。因此,机器学习就像无模式方法一样才会变得流行起来,并且有充分的理由。
知识图谱起初可能很难,但不要放弃。实践是走向完美的铺路石。
随着大数据的大肆发展和 NoSQL 的崛起,开始出现其他的一些东西。有关非 RDF 图谱的工具和数据库开始出现在市场上。这些标签属性类型( Labeled Property Kind,LPG)的图谱更简单和简洁。与 RDF 相比,它们缺少模式或只提供了基本的模式功能。
它们通常在运营类应用、图算法或图分析方面表现得更好。最近,图也开始被应用于机器学习。这些都是非常有用的东西。
算法、分析和机器学习可以提供有关图的见解,一些常见的用例包括欺诈检测或推荐系统。因此,你可以说这些技术和应用程序从图谱中获取知识,是自下而上的。另一方面,RDF 图谱将知识引入图谱,这是自上而下的。
那么,自下而上的图谱也是知识图谱吗?
知识工程师可能会说,这是一个语义问题。我们很容易陷入知识图谱炒作中。但最终,可能会因为缺乏清晰度而无法发挥太大作用。图算法、图分析和基于图的机器学习和见解,这些都很好,它们也不与“传统”的知识图谱相互排斥。
我们之前提到的这个领域的佼佼者都使用了多种方法的组合。例如,使用机器学习来计算知识图谱有助于构建最大的知识图谱——至少在实例方面。这也是像 DeepMind 这样的 AI 先驱正在研究的东西。
有些旧东西,有些新东西,有些借来的东西
通常,使用何种图谱方法和工具取决于你的实际用例。对于图数据库来说也是一样的,我们一直在密切关注它的发展,一路看着新的提供商和功能的加入。
在不久前的 Strata 大会上,获得最具颠覆性创业奖的获奖者和亚军都是图数据库:TigerGraph 和 Memgraph。如果你想要这个领域快速进展的证据,那么这就是。顺便说一句,这两家创业公司都很年轻。
对于在 2017 年 9 月低调现身的 TigerGraph 来说,这是非常活跃的一年。TigerGraph 刚刚宣布推出了新版本。它包含了一些旧东西,一些新东西,一些借来的东西。
自上而下还是自下而上?
新东西很少。他们都在解决 TigerGraph 现有的痛点。TigerGraph 增加了与流行数据库和数据存储系统的集成,包括:RDBMS、Kafka、Amazon S3、HDFS 和 Spark(即将推出)。TigerGraph 表示,他们将会推出开源的数据库连接器,并托管在 GitHub 上。
当然,如果没有社区,Github 存储库也不会有太大作用。TigerGraph 正在努力,并发布了新的开发者门户和电子书。这个版本还带来了更多部署选项,添加了对微软 Azure 的支持。为了跟上容器化趋势,还增加了对 Docker 和 Kubernetes 的支持。
我们之前提到了图算法,这可能是这个版本最有趣的方面。TigerGraph 增加了对图算法的支持,例如 PageRank、Shortest Path、Connected Components 和 Community Detection。有趣的是,这些是通过 TigerJraph 自己的查询语言 GSQL 来提供支持的。
我们已经提到了查询语言对图数据库的重要性。最近,领先的图数据库提供商 Neo4j 提出了为 LPG 图数据库创建标准查询语言的建议。与自带 SPARQL 的 RDF 不同,这在 LPG 世界中尚不存在。
最开始,TigerGraph 回应了 Neo4j 的提议,但现在情况正在发生变化。TigerGraph 刚刚发布了一个 Neo4j Migration Toolkit,主要用于将 Cypher(Neo4j 的查询语言)翻译成 GSQL。
TigerGraph 这样做是有道理的,因为一直要迁移现有的 Cypher 查询体系将会成为他们发展的障碍。TigerGraph 的实现方式很有趣,他们提供了一次性的批量翻译过程,而不是进行交互式的迁移。
这是一种战略选择。TigerGraph 希望人们切换到 GSQL,而不是在 TigerGraph 之上使用 Cypher。一般来说,开发人员一直不愿意学习新的查询语言。TigerGraph 可以尝试去说服他们,但能不能奏效完全取决于每个人。
旧东西是指 TigerGraph 发布公告包含的基准测试。这些基准测试实际上是新的,但 TigerGraph 在刚推出时就已经提供了基准测试。对于一款声称比其他任何解决方案都要快的产品,这样做是无可厚非的。基准测试将 TigerGraph 与 Neo4j、亚马逊 Neptune、JanusGraph 和 ArangoDB 进行了对比,并且不出意料的是,它比其他产品都要快。
那么哪些东西是借来的?当然是知识图谱。TigerGraph 的员工也证实了客户对此表现出极大的兴趣,例如知识图谱相关活动在中国吸引了 1000 多人参与。哪个知识图谱?现在你应该知道了。

- 技术人,为什么需要构建知识图谱 (转载)
- 为什么需要知识图谱?什么是知识图谱?——KG的前世今生
- 技术人,为什么需要构建知识图谱
- 开发者,为什么需要构建知识图谱
- 抛开双11不谈,为什么我现在购物对京东和天猫成两极态度?
- 为什么有人现在知识更新的速度不快?
- 技术人,为什么需要构建知识图谱
- 百度引领下一代搜索引擎 知识图谱成网络版“十万个为什么”
- 技术人,为什么需要构建知识图谱
- 技术人,为什么需要构建知识图谱
- BetterExplained]为什么你应该(从现在开始就)写博客
- 前端知识结构图谱
- 专题解读 |「知识图谱」领域近期值得读的 6 篇顶会论文
- 一.PHP知识图谱——CSDN
- 分布式核心技术知识图谱,带走不谢
- 网络知识结构图谱
- 为什么你应该(从现在开始就)写博客
- 95后的封闭文化圈子:为什么你不理解现在的年轻人?
- (转)什么是区块链,一文看懂区块链架构设计(附知识图谱)
- 知识图谱在大数据中的应用