Database | 浅谈Query Optimization (1)
综述
由于SQL是声明式语言(declarative),用户只告诉了DBMS想要获取什么,但没有指出如何计算。因此,DBMS需要将SQL语句转换成可执行的查询计划(Query Plan)。但是对同样的数据可以有多种查询方案,性能也差距很大,查询优化器(Query Optimizer)的任务就是从给定的查询中选择一个最优的方案。
最早的查询优化器实现是IBM在1970s设计的 System R,其中的概念和设计到现在依然有很多使用。对于查询优化通常有两种方案:
- 基于启发式规则:启发式优化将查询的部分与已知的模式进行匹配,以重组计划。这些规则对查询进行转换,消除低效率的部分,这种方式不需要检查数据本身。
- 基于代价的搜索:需要读取数据并估计执行计划的成本。然后从各个计划中选择成本最低的方案。
等价的关系代数(启发式规则)
如果两个关系代数表达式生成相同的元组集,则它们是等价的。DBMS 可以在没有成本模型的条件下生成更优的查询计划,即查询重写(Query Rewriting)
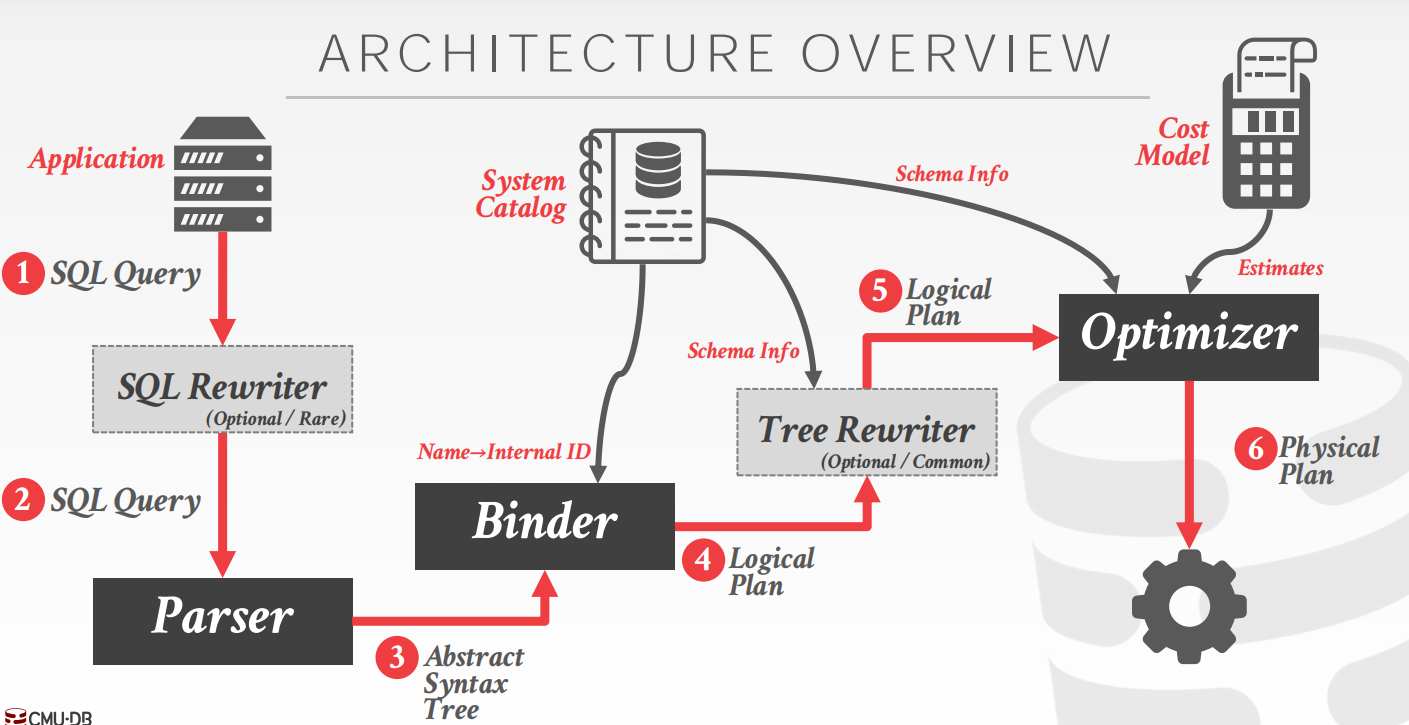
当应用程序向数据库发送SQL查询,DBMS首先要将SQL解析成语法树的标记,Binder 查询系统目录将语法树标记替换为内部标识符,生成逻辑查询计划,最后由查询优化器选择最高效的执行方案。
一种等价的关系代数是谓词下推,对于这样的SQL查询:
SELECT s.name, e.cid FROM student AS s, enrolled AS e WHERE s.sid = e.sid AND e.grade = 'A'
相比于先连接再过滤,应当更早地对数据进行过滤,以减少连接时的元素数量。

有关选择(selection)的优化:
- 尽早执行过滤
- 重排谓词,将最具选择性的谓词优先应用
- 分解复杂的谓词,将之往下推
有关投影(projection)的优化:(列存储无需进行这两条优化)
- 尽早进行投影以创建更小的元组并减少中间结果
- 只投影被需要的属性
有关连接(join)的优化:
-
R⋈S = S⋈R,因此可以重排多个表的连接顺序
-
但对于n个表,不同的连接顺序为卡特兰数(\(≈4^n\))

如果要对所有顺序穷举的话,当n较大时效率会非常低。连接顺序通常由cost based search选择最优/较优的方案。
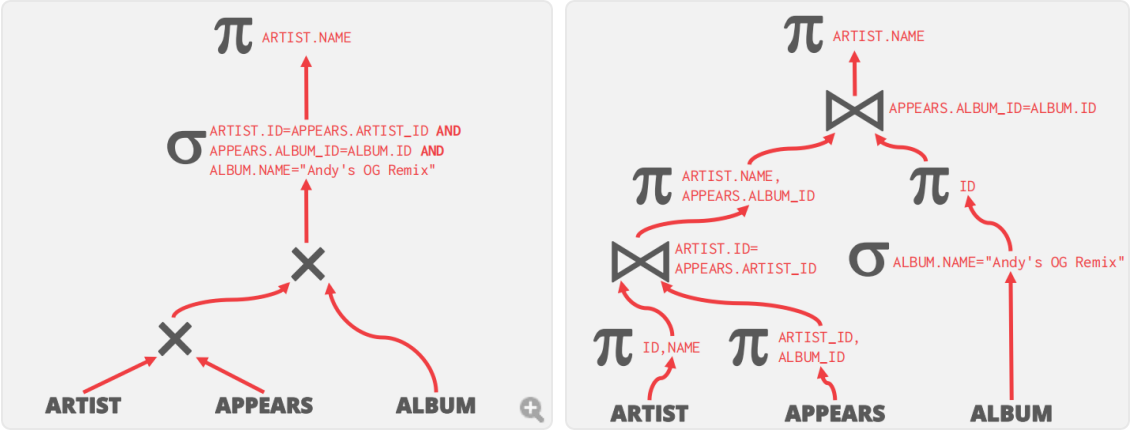
SELECT ARTIST.NAME FROM ARTIST, APPEARS, ALBUM WHERE ARTIST.ID=APPEARS.ARTIST_ID AND APPEARS.ALBUM_ID=ALBUM.ID AND ALBUM.NAME="Andy's OG Remix"
对于这样的SQL查询,最朴素的查询方案可能是左图所示,但通过:
- 分解复杂谓词并向下推
- 将笛卡尔积替换为连接
- 在连接前消除不必要的属性
可以优化为右图所示的方案
其他优化包括:
忽略不必要的join、projection
SELECT A1.* FROM A AS A1 JOIN A AS A2 ON A1.id = A2.id; //unnecessary SELECT * FR ad8 OM A AS A1 WHERE EXISTS(SELECT val FROM A AS A2 //unnecessary WHERE A1.id = A2.id);
合并谓词:
SELECT * FROM A WHERE val BETWEEN 1 AND 100 OR val BETWEEN 50 AND 150;
对于嵌套查询,有两种方案:
- 重写,将其转化为单次查询
- 先进行子查询,将结果储存在临时表中。得出最终结果后将临时表丢弃。
基于代价的搜索
这种优化方式分为两个步骤:
- 成本估计
- 方案选择
成本估计
首先要为特定的执行计划生成成本估算,而访问磁盘的消耗始终是查询中最主要的消耗,并且还要考虑顺序访问还是随机访问,这两者在性能上也有极大差异。
选择基数
DBMS 在目录中存储有关属性、索引的内部信息。对于每个关系R,DBMS维护以下信息:
- \(N_R\) :R中的元组数量
- \(V(A, R)\):R中在属性A上不同值的数目
则选择基数(selection cardinality SC(A,R))为给定属性的值的平均数量 \(SC(A, R) = N_R / V(A,R)\)
在计算cost的时候,需要考虑不同谓词选择的范围。谓词的选择性(selective)即是一个谓词限定的部分。
比如对SC(A,R)=2的关系R中,若A的数据为1-100的连续整数,则对于查询
SELECT * FROM R WHERE A >50
可以计算出\(sel(A>50) = 50/100 = 1/2\)
SELECT * FROM R WHERE A = 2 OR B LIKE 'A%'
\(sel(P1 ⋁ P2) = sel(P1) + sel(P2) – sel(P1⋀P2) = sel(P1) + sel(P2) – sel(P1) ∙ sel(P2)\)
也可以说,选择性就是指这个范围的数据出现的概率。
但以上的估计基于三个假设:
- 数据是均匀分布的
- 多个谓词之间相互独立,可以独立计算概率
- 内部关系中的key在外表中同样存在
因此得出的结果是一个估计值,并不精确。
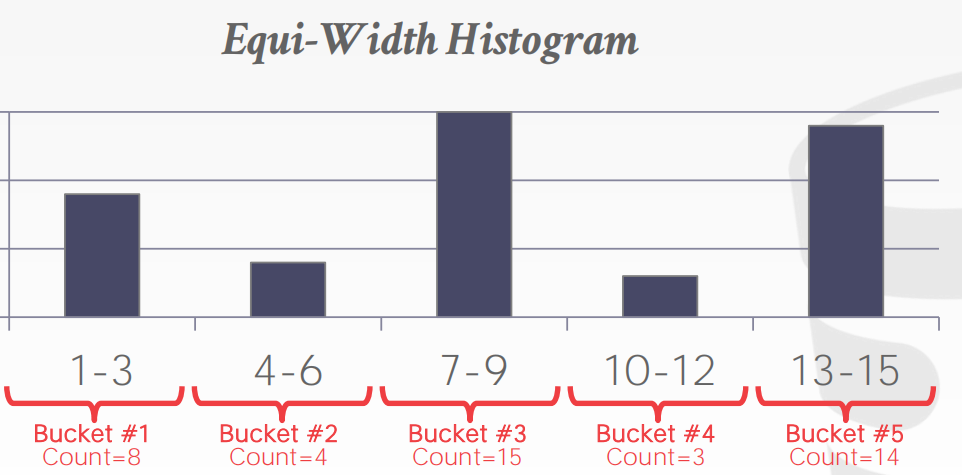
统计直方图
可以对第一个假设进行优化,在每个表中储存有关数据的直方图,将数据按范围进行统计,在计算sel时从直方图中计算相应的比例。
样本估算
现代DBMS从表中选择 ad8 一定的样本估算sel,当底层表发生显著变化时更新样本。
方案选择
对于简单的单表查询(OLTP),通过启发式规则,利用索引和二分搜索足以获取良好的性能。
但是对于OLAP中的多表查询,不同的连接顺序会对性能造成很大影响。而由于关系的增加会导致可选择方案指数增长(\(4^n\)),因此需要约束可选择的空间。
System R 中只考虑左深连接树(Left Deep Join),将选择空间缩小到 \(n!\),但现代DBMS中不再总做出这样的假设。
左深连接树即连接的右表一定为一个基本表,通过流水线连接,中间结果不写入临时文件。

对于连接,需要考虑连接的顺序,不同表之间连接的方式(Hash join, Sort-Merge join),获取数据的方式。通过动态规划对方案进行剪枝。
除了通过动态规划剪枝之外,当连接表过多时,会选择一些局部最优解的方式:
-
greedy join enumeration algorithm
在每次循环中,选择使总代价最低的方案
-
多项式时间算法,但结果不一定最优
-
Randomized algorithm
随机重写查询方案,利用模拟退火等算法进行优化
-
Genetic algorithm(遗传算法)
通过连接方案(结合子代)和随机突变进行优化
至于为什么是左深连接树,而不是右深连接树?动态规划的执行优化又是如何实现的?留待后面分析

- 浅谈QTP的数据库检查点Database checkpoint使用流程
- SQLiteDatabase浅谈
- 实用浅谈HTML5 Web SqlDatabase
- 浅谈EF框架(二)--DataBaseFirst
- 浅谈人脸检测之Haar分类器方法
- 浅谈顺序、折半查找
- 深入体验JavaWeb开发内幕——浅谈面向对象的设计模式
- 技术总监和CTO的区别 浅谈CTO的作用----软件公司如何开源节流(一)[转]
- 浅谈SOA
- 浅谈Hibernate的flush机制
- 浅谈容器监控和网易云计算基础服务实践
- 浅谈maven
- 浅谈javascript的调试
- 由基于qml,c++的串口调试工具浅谈qml与c++混合编程
- The EXECUTE permission was denied on the object 'uf_date', database 'AA', schema 'dbo'.
- CKEditor与CKFinder学习--浅谈CKFinder源码修改自定义上传文件名
- 浅谈框架zend framework和模板引擎smarty的区别【转载】
- Using Sphinx to index CNS database
- 浅谈Linq To Sql集成数据库语言的优劣
- sudo用法浅谈