假如你是微博架构师,你会如何设计微博架构?
这个10月真是不消停啊,先是网上流传着《因不写注释,码农杀了4位同事,一人情况危急》刷屏,然后是《重磅!使用了23年的Java不再免费!》。再然后,微博,推特,youtube,github等都轮流着挂了,程序员成了背锅侠!
微博曾经流传着“可支撑8位明星同时出轨”,可是微博却支撑不了一个明星结婚。一个“官宣”微博就又挂了,于是微博CEO改口了“从没承诺再也不宕机”。
作为程序员,我们都又一个设计师的梦,那么如果你是微博的架构师,你该如何设计微博的架构呢?下面我们一起来看看微博的现状吧!
在开始之前,我先偷偷的给你透露一下,微博是php写的!
据说微博现在的日活跃用户1.6亿+,每日访问量达百亿级。
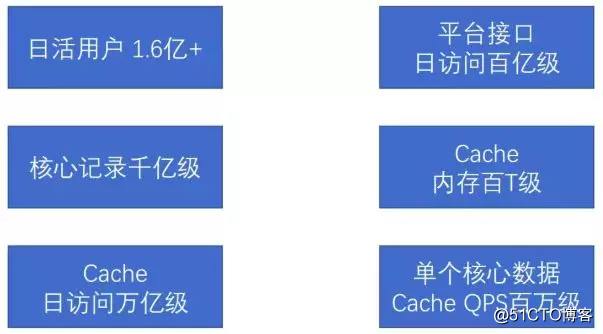
看到了吧,微博的设计挑战还是存在的!
再给大家透露一下,大家日常刷微博的时候,比如在主站或客户端点一下刷新,最新获得了十到十五条微博,这是怎么构建出来的呢?
刷新之后,首先会获得用户的关注关系。比如他有一千个关注,会把这一千个ID拿到,再根据这一千个UID,拿到每个用户发表的一些微博。同时会获取这个用户的Inbox,就是他收到的特殊的一些消息,比如分组的一些微博、群的微博、下面的关注关系、关注人的微博列表。
拿到这一系列微博列表之后进行集合、排序,拿到所需要的那些ID,再对这些ID去取每一条微博ID对应的微博内容。如果这些微博是转发过来的,它还有一个原微博,会进一步取原微博内容。通过原微博取用户信息,进一步根据用户的过滤词对这些微博进行过滤,过滤掉用户不想看到的微博。
根据以上步骤留下的微博,会再进一步来看,用户对这些微博有没有收藏、点赞,做一些flag设置,还会对这些微博各种计数,转发、评论、赞数进行组装,最后才把这十几条微博返回给用户的各种端。
这样看来,用户一次请求得到的十几条记录,后端服务器大概要对几百甚至几千条数据进行实时组装,再返回给用户,整个过程对Cache体系强度依赖,所以Cache架构设计优劣会直接影响到微博体系表现的好坏。
我问了一下号称高级开发的工程师,他们说这又什么难的?淘宝主要把库存控制好,微博主要把缓存控制好就行了。然后就扯一些读写分离,数据库集群,分表分库,消息队列,高并发高可用。
我说你这是瞎扯淡!没有实战经验的高并发都是纸上谈兵!
对于像微博这样的热点新闻,高访问的事件,一定要设计好缓存!如果缓存没设计好,都去查DB的话肯定DB支持不住。只要缓存命中率高,DB端风险就会下降!
有人说,直接上Redis。但你应该知道Redis工作机制是单线程模式,如果它加某一个UV,关注2000个用户,可能扩展到两万个UID,两万个UID塞回去基本上Redis就卡住了,没办法提供其他服务。
在这方面,我们可以参考一下推特Twitter的设计方案。
Twitter 整体存储架构有如下四套系统:
NoSql,主要包括用户信息、比较小的数字;当时大约有三万多节点。
大文件系统,主要是存储图片、video 等大数据文件。与 NoSql 同样,也有三万多个节点。
Hadoop 系统,主要用于后台数据处理、分析;最多的时候有九千个节点左右。
MySQL,简单、比较复杂的关系性数据查询
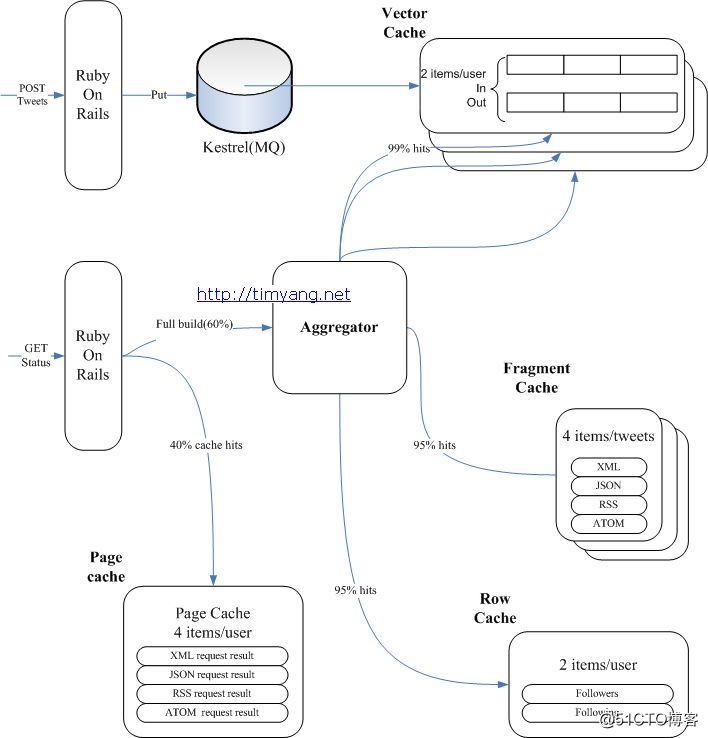
上图是网上找的一篇关于Twitter的缓存方面的架构设计!仅供参考,实际可能并不是这个样子!
其他的我就不细说了,因为我并没有参与过微博和Twitter的架构设计,说的再多都是纸上谈兵!最后给大家看看群里一部分网友的讨论:
不细说了,洪峰扛不住时,只能加机器。
机器哪里来?租云计算平台公司的设备。
当然,设备只需要在洪峰时租用,省钱呀(@58沈剑 疑问:twitter怎么知道什么时候是洪峰?)。
如果你对微博架构又想法,请留言评论!
最后,想要学习高并发的同学,可以扫描下方微信二维码,关注“业余草”微信公众号,回复“秒杀”给你一套价值超过千元的高并发秒杀系统设计的视频教程!

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加QQ1群:135430763(2000人群已满),QQ2群:454796847,QQ3群:187424846。QQ群进群密码:xttblog,想加微信群的朋友,可以微信搜索:xmtxtt,备注:“xttblog”,添加助理微信拉你进群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作可添加助理微信进行沟通!

- 如果是你铁道部12306网站架构师,如何设计网站的软件架构和硬件系统架构
- 架构师如何才能够设计一个安全的架构
- 架构师:如何设计高吞吐量系统架构
- [转载]如果你是12306网站架构师,你会如何设计网站的软件架构和硬件系统架构?
- 如果你是12306网站架构师,你会如何设计网站的软件架构和硬件系统架构?
- 聊聊架构设计做些什么来谈如何成为架构师
- 【JAVA进阶架构师指南】之一:如何进行架构设计
- 架构师必看:谈软件架构师如何做好架构设计(上)
- 架构师:如何设计高吞吐量系统架构
- 如何进行软件架构设计3--如何成为架构师
- 编程设计-如何写可维护的程序. 通往架构思维之路
- 专访架构师周爱民:谈企业软件架构设计
- 林仕鼎谈架构设计与架构师
- (转载)如何设计一款优秀的软件架构
- 如何设计架构
- 架构,如何进行容量设计?
- 如何设计架构?
- 【架构设计】软件架构师应该知道的97件事
- Kafka如何通过精妙的架构设计优化JVM GC问题
- 关于如何设计一个基于事件驱动架构的思考