现实中的路由规则,可能比你想象中复杂的多

文中聊的是数据路由,不是nginx之类的。
几乎每一个分布式系统,都会给用户提供自定义路由的功能。因为,仅通过range、mod、hash等方法,很大概率已经满足不了用户的需求。下面以一个实际场景为例,说一下数据路由的思路。
场景
某个大型toB的应用,使用MySQL存储,单表数据量已达数亿,在结构变更、数据查询方面,已表现出明显的瓶颈,需要进行分库分表。
实施步骤
找到切分键
第一步就是找到切分的纬度。比如业务是按照时间纬度进行查询的,那么就把创建时间作为切分键。
此业务的切分键,是商户id(类似于你在美团开店了,美团给你分配的唯一id)。由于历史原因,这个id是用的数据库主键id,而且是自增的。业务具有以下特点:
一、 业务操作是由某个商户发起的,每张表都有商户id字段
二、 商户的数据不均衡,有的商户有几千万,有的可能只有十几条
三、 存在部分vip商家,其数据量非常庞大
四、 存储大量统计需求,所以无法分表,只能分库
五、 存在遍历数据的可能,比如部分定时
切分需求一阶段
分库迫在眉睫。通过分析,部分vip商户,数据量巨大,把它单独转移到一个数据库中也不为过。
通过维护一个映射文件,来控制vip商户到数据存储流向。这时候,就需要自定义路由。
伪代码如下:
function viptable(id){
10 => "mysql-002"
101 => "mysql-003"
}
function router4vip(id){
aimDb = viptable(id)
if(aimDb) return aimDb
return "mysql-001"
}
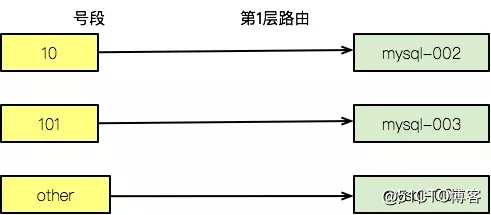
商户为10,数据将落向mysql-002;商户为101,将落向mysql-003;数据默认使用mysql-001存储。
另外,由于id是自动生成的自增字段,与路由存在一个先有鸡还是先有蛋的问题,所以将id字段修改为人工设值,延伸出另外一个配号系统,在此不多提。
切分需求二阶段
解决了vip商户的问题,接下来就需要解决mysql-001的问题。随着业务的发展,落在默认库上的数据越来越多,很快又遇到了瓶颈。
想到的方法是,对其一分为二。mysql-001的数据打散到两个库中。这个打散的规则,我们直接采用mod。
为什么不是一拆为三呢?主要是基于以下考虑,假设拆分后的db为:
mysql-001-1 mysql-001-2
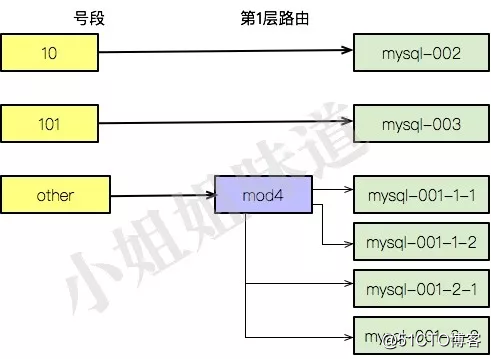
这种情况下mysql-001就变成了逻辑集群。当mysql-001-1和mysql-001-2也达到了瓶颈,那我们就可以对其继续进行拆分,依然是一拆为二,这时候,mod 4就可以了,不会涉及复杂的数据迁移。
拆分后的db为:
mysql-001-1-1 mysql-001-1-2 mysql-001-2-1 mysql-001-2-2
到现在为止,我们采用了vip分库,mod 4分库,伪代码如下:
...
function routertable(pivot){
0 => "mysql-001-1-1"
1 => "mysql-001-1-2"
2 => "mysql-001-2-1"
3 => "mysql-001-2-2"
}
function router4mod(id){
aimDb = router4vip(id)
if(aimDb) return aimDb
pivot = mod4(id)
return routertable(pivot)
}
到现在,我们已经分了六个库了。通过裂变的模式,有着较好的扩展性。
这样就可以高枕无忧了么?
切分需求三阶段
可惜的是,我们每次扩容,都是指数级别的。下一次,就是mod 8;而下下次,就是mod 16。每次扩容,都会动一半的数据,wtf。
最后,决定在商户id的范围上做文章。
首先,做一个定长的商户id,比现有系统中的任何一个都长,主要考虑新的规则不会影响旧的路由规则。
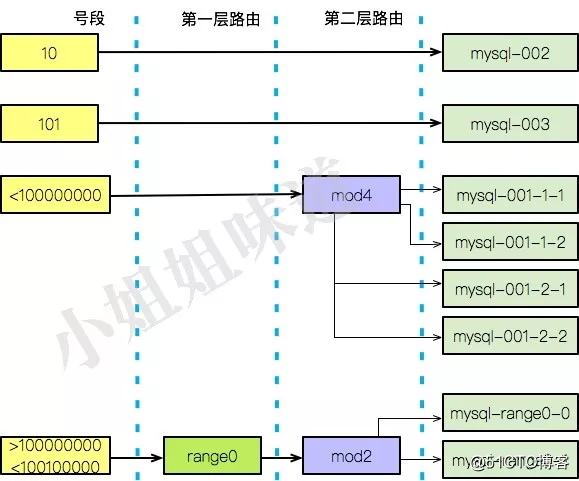
然后,首先根据商户id的范围划分第一层虚拟集群,然后再根据mod划分第二层虚拟集群。我们的路由,现在是双层路由。
比如,我们把商户号定9位(java中int是10位),并做如下路由表:
100 000000 - 100 100000=> 虚拟集群1 100 100000 - 100 200000=> 虚拟集群2 ...
前三位,用来分第一层虚拟集群,支持899个;后6位,代表范围,最大10万。每个范围下面,都会有自己的路由规则,有的可能mod 2,有的可能 mod3,有的可能再次range。
好,我们加入新的集群:
mysql-range0-0 代表号段在范围1中的偶数id mysql-range0-1
伪代码如下:
...
function router4range(id){
if(id < 100000000){
return router4mod(id)
}else if
(id in [100000000-100100000]){
return
"mysql-range0-"+mod2(id)
}
}
到此为止,我们一共有8个库,其中两个是给vip用的,四个是遗留的路由算法,还有两个是给新的分库规则使用。
通过三次改进,我们的路由满足:
一、 当我们发现,当商户id增长到100 056400,就达到瓶颈了,那么就可以新增一个新的范围,只需要改动一下路由表逻辑就ok了
二、 当某个范围内某个商户成长为vip,那我们就可以单独将其提取出来,增加新的vip库
三、 某个范围内数据热点严重,那么就可以mod 4进行扩容,并不影响范围外的数据
四、 商户id同时也有时间纬度的概念,可以针对某些旧商户进行归档清理
切分需求四阶段
系统想要预留另外一部分号段,用来提供一些测试账号,供客户试用。经历过前三轮的改造,我们可以很容易的对其进行规划。
End
为什么觉得redis-cluster的slot设计是个鸡肋呢,因为它把路由规则给定死了,要我去设计我肯定要放在驱动层。
某些架构师潇洒的来,潇洒的走,留下了不可磨灭的痕迹。为了兼容这些遗留系统的路由代码,分支会更加复杂,每一个公司都有一堆故事,无非是骂娘和被骂。稳定性重如山,路由代码可能是最重要的没技术含量的if else。一动,都得死。
就问你怕不怕?

- 现实中的路由规则,可能比你想象中复杂的多
- DevExpress DXTREME的路由规则声明方法
- 并没有想象的高兴,可能是欣慰吧
- Spring Cloud GateWay 路由转发规则介绍详解
- NET:工作流中如何动态解析路由规则 之 T4 + 动态编译
- AS3 对复杂对象的排序规则[DEMO]
- 如何建立索引,提高查询速度。 ---- 人们在使用SQL时往往会陷入一个误区,即太关注于所得的结果是否正确,而忽略了不同的实现方法之间可能存在的 性能差异,这种性能差异在大型的或是复杂的数据库环境中
- MVC之路由规则 (自定义,约束,debug)
- 机器学习问题的可解性的变化,不可能的事情正在慢慢变成现实
- 【TP3.2】路由匹配和规则
- dubbo服务的集群扩展、目录服务、路由规则、负载均衡
- MVC路由规则以及前后台获取Action、Controller、ID名方法
- python的web框架webpy【路由规则】(三)
- 职场中年危机,可能只是你放水太多又不接受现实而已
- 爱情总是想象比现实美丽
- 在做一些复杂的类型转换之前(比如将一个数据转换成一个属性的类型,属性可能为可空类型)先判断该类型是否为可空类型,否则会报如下错误:
- 用规则引擎来实现复杂业务逻辑判断之drools
- ASP.NET的路由系统:根据路由规则生成URL
- 第二十二章 Spring cloud Zuul使用正则表达式指定路由规则
- 路由规则