Flink实战-页面广告分析,并实时检测恶意点击行为
2021-01-24 16:56
302 查看
网站一般都需要根据广告点击量来制定对应的定价策略和调整市场推广的方式,一般也会收集用户的一些偏好和其他信息,这里实现一个统计不同省份/或者市用户对不同广告的点击情况,有助于市场部对于广告的更精准投放,并且要防止有人恶意点击,不停的点同一个广告(当然同一个ip一直点不同的广告也是一样)
准备的日志文件ClickLog.csv:
543462,1715,beijing,beijing,1512652431 543461,1713,shanghai,shanghai,1512652433 543464,1715,shanxi,xian,1512652435 543464,1715,shanxi,weinan,1512652441 543464,1715,shanxi,weinan,1512652442 543464,1715,shanxi,weinan,1512652443 543464,1715,shanxi,weinan,1512652444 543464,1715,shanxi,weinan,1512652445 543464,1715,shanxi,weinan,1512652446 543464,1715,shanxi,weinan,1512652447 543464,1715,shanxi,weinan,1512652451 543464,1715,shanxi,weinan,1512652452 543464,1715,shanxi,weinan,1512652453 543464,1715,shanxi,weinan,1512652454 543464,1715,shanxi,weinan,1512652455 543464,1715,shanxi,weinan,1512652456 543464,1715,shanxi,weinan,1512652457 543464,1715,shanxi,hanzhong,1512652461 543464,1715,shanxi,yanan,1512652561
代码:
/*
*
* @author mafei
* @date 2021/1/10
*/
package com.mafei.market_analysis
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import java.sql.Timestamp
/**
* 定义输入的样例类
* 543464,1715,shanxi,weinan,1512652459
*/
case class AdClickLog(userId: Long,adId: Long,province: String, city: String,timestamp:Long)
/**
* 定义输出的样例类
* 统计每个省对每个广告的点击量
*/
case class AdClickCountByProvince(windowEnd: String,province: String, count: Long)
object AdClickAnalysis {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //指定事件时间为窗口和watermark的时间
env.setParallelism(1)
//从文件中读取数据
val resource = getClass.getResource("/ClickLog.csv")
val inputStream = env.readTextFile(resource.getPath)
// 转换成样例类,并提取时间戳watermark
val adLogStream = inputStream
.map(d=>{
val arr = d.split(",")
AdClickLog(arr(0).toLong,arr(1).toLong,arr(2),arr(3),arr(4).toLong)
})
.assignAscendingTimestamps(_.timestamp * 1000L)
// 定义窗口,聚合统计
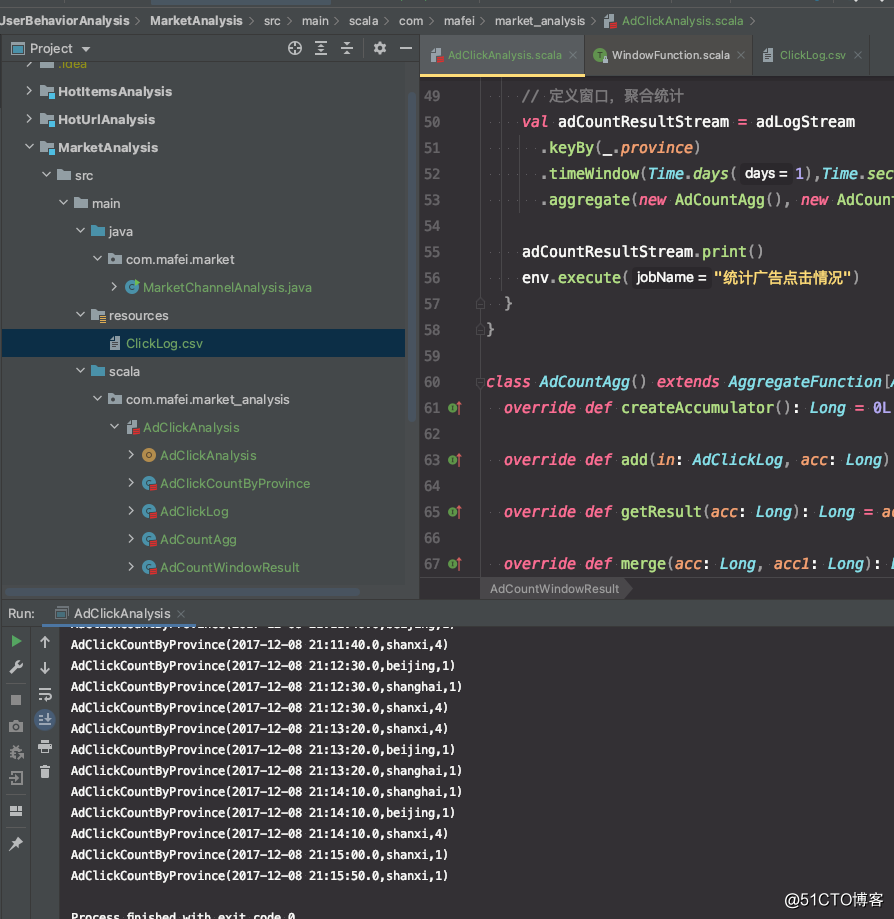
val adCountResultStream = adLogStream
.keyBy(_.province)
.timeWindow(Time.days(1),Time.seconds(50))
.aggregate(new AdCountAgg(), new AdCountWindowResult())
adCountResultStream.print()
env.execute("统计广告点击情况")
}
}
class AdCountAgg() extends AggregateFunction[AdClickLog, Long,Long]{
override def createAccumulator(): Long = 0L
override def add(in: AdClickLog, acc: Long): Long = acc+1
override def getResult(acc: Long): Long = acc
override def merge(acc: Long, acc1: Long): Long = acc + acc1
}
class AdCountWindowResult() extends WindowFunction[Long,AdClickCountByProvince,String,TimeWindow]{
override def apply(key: String, window: TimeWindow, input: Iterable[Long], out: Collector[AdClickCountByProvince]): Unit = {
out.collect(AdClickCountByProvince(windowEnd = new Timestamp(window.getEnd).toString, province = key, count = input.head))
}
}
代码结构及运行效果
黑名单刷单过滤
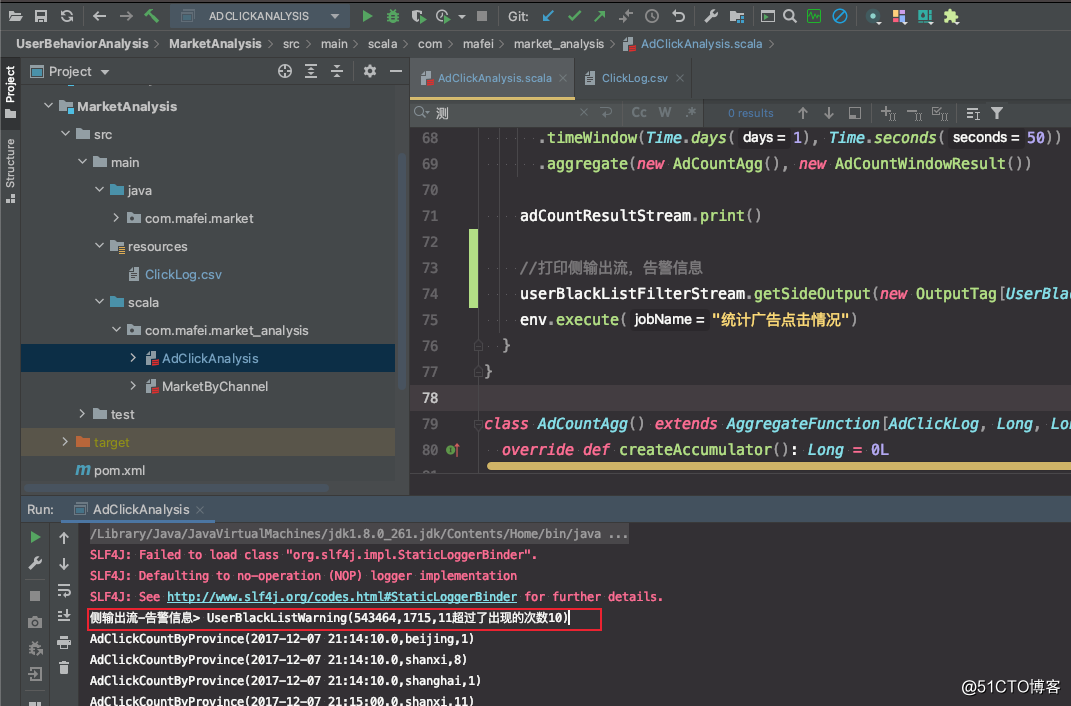
上面代码中,同一个用户的重复点击是会叠加计算的,在实际生产场景中,同一个用户可能会重复点开某一个广告,但是如果用户在一段时间内非常频繁的点击广告,这明显不是个正常行为了,在刷点击量,所以可以做个限制,比如同一个广告,同一个人每天最多点100次,超过了就把这个用户加到黑名单里头并告警,后边的点击行为就不再统计了
那来个改进的版本:
/*
*
* @author mafei
* @date 2021/1/10
*/
package com.mafei.market_analysis
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import java.sql.Timestamp
/**
* 定义输入的样例类
* 543464,1715,shanxi,weinan,1512652459
*/
case class AdClickLog(userId: Long, adId: Long, province: String, city: String, timestamp: Long)
/**
* 定义输出的样例类
* 统计每个省对每个广告的点击量
*/
case class AdClickCountByProvince(windowEnd: String, province: String, count: Long)
/**
* 黑名单预警输出的样例类
*/
case class UserBlackListWarning(userId: String, adId: String, msg: String)
object AdClickAnalysis {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //指定事件时间为窗口和watermark的时间
env.setParallelism(1)
//从文件中读取数据
val resource = getClass.getResource("/ClickLog.csv")
val inputStream = env.readTextFile(resource.getPath)
// 转换成样例类,并提取时间戳watermark
val adLogStream = inputStream
.map(d => {
val arr = d.split(",")
AdClickLog(arr(0).toLong, arr(1).toLong, arr(2), arr(3), arr(4).toLong)
})
.assignAscendingTimestamps(_.timestamp * 1000L)
// 插入一步操作,把有刷单行为的用户信息输出到黑名单(侧输出流中)并做过滤
val userBlackListFilterStream: DataStream[AdClickLog] = adLogStream
.keyBy(data => {
(data.userId, data.adId)
})
.process(new FilterUserBlackListResult(10L))
// 定义窗口,聚合统计
val adCountResultStream = userBlackListFilterStream
.keyBy(_.province)
.timeWindow(Time.days(1), Time.seconds(50))
.aggregate(new AdCountAgg(), new AdCountWindowResult())
adCountResultStream.print()
//打印测输出流
userBlackListFilterStream.getSideOutput(new OutputTag[UserBlackListWarning]("warning")).print("测输出流")
env.execute("统计广告点击情况")
}
}
class AdCountAgg() extends AggregateFunction[AdClickLog, Long, Long] {
override def createAccumulator(): Long = 0L
override def add(in: AdClickLog, acc: Long): Long = acc + 1
override def getResult(acc: Long): Long = acc
override def merge(acc: Long, acc1: Long): Long = acc + acc1
}
class AdCountWindowResult() extends WindowFunction[Long, AdClickCountByProvince, String, TimeWindow] {
override def apply(key: String, window: TimeWindow, input: Iterable[Long], out: Collector[AdClickCountByProvince]): Unit = {
out.collect(AdClickCountByProvince(windowEnd = new Timestamp(window.getEnd).toString, province = key, count = input.head))
}
}
/**
* key是上面定义的二元组
* 输入和输出不变,只是做过滤
*/
class FilterUserBlackListResult(macCount: Long) extends KeyedProcessFunction[(Long, Long), AdClickLog, AdClickLog] {
/**
* 定义状态,保存每一个用户对每个广告的点击量
*/
lazy val countState: ValueState[Long] = getRuntimeContext.getState(new ValueStateDescriptor[Long]("count", classOf[Long]))
/**
* 定义每天0点定时清空状态的时间戳
*/
lazy val resetTimeTsState: ValueState[Long] = getRuntimeContext.getState(new ValueStateDescriptor[Long]("resetTs", classOf[Long]))
/**
* 定义用户有没有进入黑名单
*/
lazy val isBlackList: ValueState[Boolean] = getRuntimeContext.getState(new ValueStateDescriptor[Boolean]("isBlackList", classOf[Boolean]))
override def processElement(i: AdClickLog, context: KeyedProcessFunction[(Long, Long), AdClickLog, AdClickLog]#Context, collector: Collector[AdClickLog]): Unit = {
val curCount = countState.value()
//初始状态
if(curCount == 0){
/**
* 获取明天0点的时间戳,用来注册定时器,明天0点把状态全部置空
*
*
* 获取明天的天数: context.timerService().currentProcessingTime()/(1000*60*60*24)+1
* * (24*60*60*1000) 是转换成明天0点的时间戳
* - 8*60*60*1000 是从伦敦时间转为东8区
*
*/
val ts = (context.timerService().currentProcessingTime()/(1000*60*60*24)+1) * (24*60*60*1000) - 8*60*60*1000
context.timerService().registerProcessingTimeTimer(ts)
resetTimeTsState.update(ts) //定义重置的时间点
}
//判断次数是不是超过了定义的阈值,如果超过了那就输出到侧输出流
if(curCount > macCount){
// println("超出阈值了,curCount:"+curCount + " isBlackList:"+isBlackList.value())
//判断下,是不是在黑名单里头,没有的话才输出到侧输出流,否则就会重复输出
if(!isBlackList.value()){
isBlackList.update(true)
context.output(new OutputTag[UserBlackListWarning]("warning"),UserBlackListWarning(i.userId.toString,i.adId.toString,curCount+"超过了出现的次数"+macCount))
}
return
}
//正常情况,每次都计数加1,然后把数据原样输出,毕竟这里只是为了裹一层
countState.update(curCount +1)
collector.collect(i)
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[(Long, Long), AdClickLog, AdClickLog]#OnTimerContext, out: Collector[AdClickLog]): Unit = {
if(timestamp == resetTimeTsState.value()){
isBlackList.clear()
countState.clear()
}
}
}
代码结构及运行效果

相关文章推荐
- Flink实战-恶意登录行为检测-CEP
- spark全场景项目实战,用户行为实时分析,实时流量监控系统,实时电影推荐系统
- Spark日志分析项目Demo(8)--SparkStream,广告点击流量实时统计
- 从Google Analytics分析AdSense的广告点击行为
- 用户在线广告点击行为预测的深度学习模型
- 恶意代码分析实战 第三章课后实验
- 《Spark商业案例与性能调优实战100课》第6课:商业案例之通过Spark SQL实现大数据电影用户行为分析
- 第98讲 使用Spark Streaming实战对论坛网站动态行为的多维度分析(上)
- 深入浅出Spark机器学习实战(用户行为分析)
- 恶意代码分析实战 第九章课后实验Lab09-02
- 视频教程-大数据Flink从入门到原理到电商数据分析实战项目-大数据
- Spark项目之电商用户行为分析大数据平台之(五)实时数据采集
- 恶意代码分析实战 Lab 7-1 习题笔记
- 从flink-example分析flink组件(3)WordCount 流式实战及源码分析
- 【Android病毒分析报告】 - AppPortal “恶意行为云端无限扩展”
- 如何避免百度竞价广告的恶意点击?
- 实战智能推荐系统(6)-- 用户行为分析
- 数据挖掘的广告作弊行为分析
- 上网页面被强制广告——简单分析
- MapReduce实战--分析apatch日志访问页面大小