中文金融领域情感词典构建
Python爬虫与文本分析工作坊 & 课题申报高级研修班
这篇文章是公众号关注者郝童鞋今早发给我的,在此谢谢郝童鞋。
文章基于简单算法和人工判断,使用多阶段剔除法,构建了 中文金融情感词典CFSD(ChineseFinancialSentimentDictionary), 这个词典能帮到那些想用文本分析研究会计金融领域的中文文档的研究者。CFSD词典有1489个负面词,1108个正面词。并且简单讨论了CFSD词典的应用领域。
本篇教程主要分为两部分:
-
这篇论文如何构建 中文金融情感词典
- 大邓将论文附录中的词典整理好给大家用
一、构建中文金融情感词典
情感分析目前有两大方式,情感词典法和机器学习法。基于情感词典的文本分析,必须要有好用的词典。但由于语言差异,英文的情感词典无法直接应用于中文的情感分析,而且目前中文的情感词典(如HOWNET、DLUTSD、NTUSD)都是通用性词典(大多是形容词副词),并不是专业领域词典。Loughran和 McDonald (2011)曾经指出研究商业领域问题的文本数据不应该使用非商业领域数据集构建出的词典。
因此本文作者使用HOWNET、DLUTSD、NTUSD三种词典作为初始词典,并搜集了在线路演纪要(online roadshow transcripts)、业绩说明电话会议纪要(earnings conference call transcripts)、IPO招股报告(IPO prospectus)及公司年报构建了基础语料库。基于算法和人工判断, 使用多阶段剔除法来构建 中文金融情感词典CFSD。具体步骤:
1. 合并HOWNET、DLUTSD、NTUSD三个情感词典,去除重复词
2. 收集了1411篇在线路演纪要、7138篇业绩说明电话会议纪要、2043IPO招股报告和29737公司年报。jieba被用于分割文档,构建 基础语料
3. 计算步骤1所有的词在 基础语料 中的词频,词频数为0的词语不予考虑,剔除掉。与金融不相关的词语也剔除掉,最终构建了 CFSD0.0版本中文金融情感词典。
4. 所有的CFSD0.0版本的词语都来自与三个通用情感词典(HOWNET、DLUTSD、NTUSD),但这三个词典并不包含金融领域常出现的正面词和负面词。我们人工向 CFSD0.0版情感词典加入了金融领域最常用的100个正面词100个负面词,构建出 CFSD0.1版中文金融情感词典.
5. Gensim是python中的一个文本分析库,在本步骤主要用来通过大量的语料训练处词向量。词向量可以使用余弦cos计算出相似性。在本步骤,计算出CFSD0.1版中每个词的词向量,进而从 基础语料 中发现每个词(CFSD0.1中的词)最相似的50个词。剔除掉与金融不关的词(包括相似词、同义词),构建出 CFSD0.2版的中文金融情感词典
6. 合并 CFSD0.0、CFSD0.1、CFSD0.2,剔除掉重复词,最终构建出 CFSD中文金融情感词典
构件好的CFSD词典有1489个负面词,1108个正面词。
二、词典整理到csv文件中
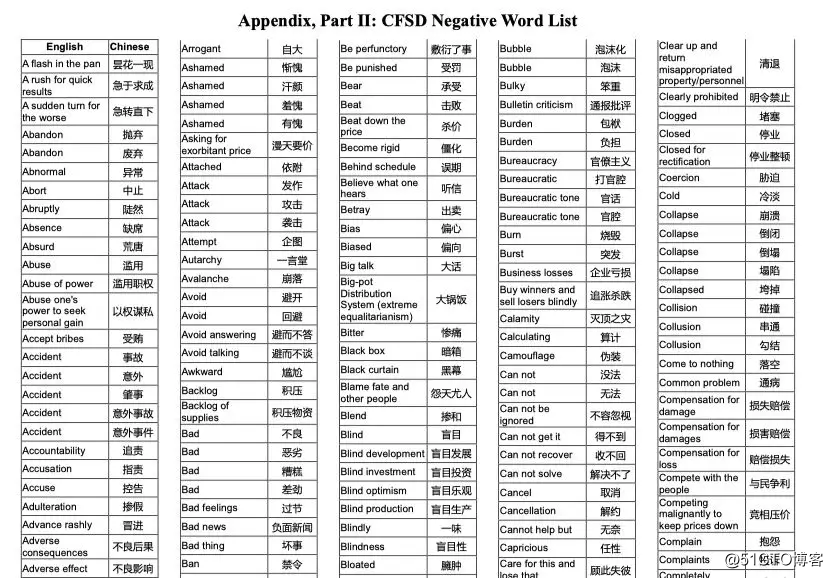
论文后面富有CFSD情感词典,如下
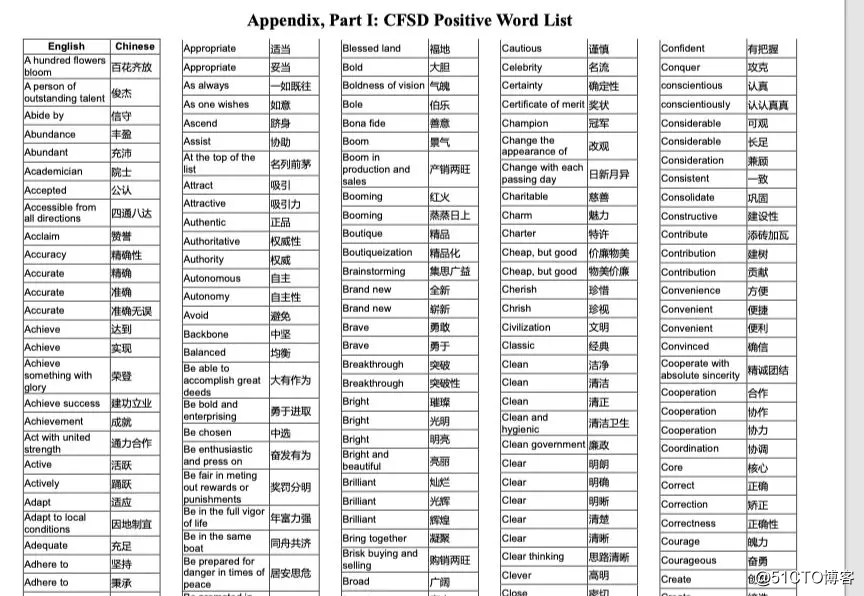
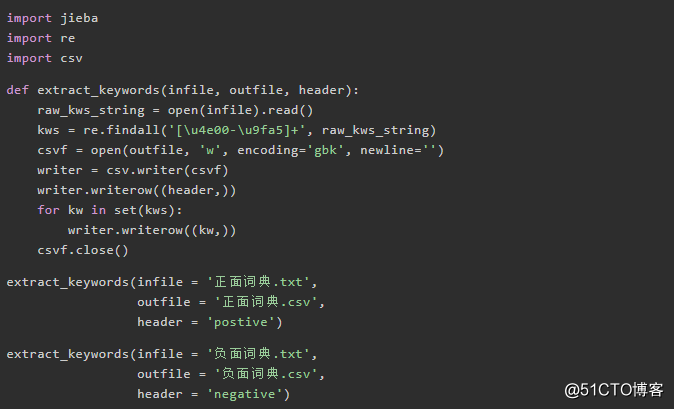
我想先将这些内容全部复制到txt中,正面词表复制粘贴到 正面词典.txt, 负面词表复制粘贴到 负面词典.txt。
通过中文正则表达式 [\u4e00-\u9fa5]+ 把txt文件里面所有的中文词抽取出来,存到csv文件中。开始~
现在我们的项目文件夹中出现了 正面词典.csv、负面词典.csv , 现在我们可以试着读取一下 正面词典.csv

Run
1109
负面词典.csv中有1488个词
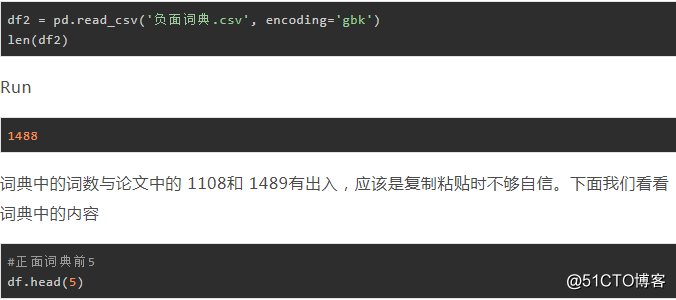

负面词典前5 df2.head(5)


- wildfly 21的配置文件和资源管理
- 理解实例方法、类方法、静态方法
- PyQuery: 爬虫界最简洁优雅的库
- 微信公众号图文素材编辑器图片载入失败
- 【Azure Application Insights】在Azure Function中启用Application Insights后,如何配置不输出某些日志到AI 的Trace中
- spring: 我是如何解决循环依赖的?
- 国务院政府工作报告(1954—2017)文本挖掘及社会变迁研究
- 计算社会经济学
- 使用torchtext导入NLP数据集
- 介绍一个可以离线查询 IP 来源和 ISP 信息的终端利器
- 界面酷炫,功能强大!这款 Linux 性能实时监控工具超好用!老斯机搞它!
- 仅需一步!直接在 Windows 下使用 Linux
- 如何用pandas对excel中的文本数据进行操作
- 如何用pandas对excel中的文本数据进行操作
- Flask-认识response对象
- 超赞!墙裂推荐这款开源、轻量无 Agent 自动化运维平台
- VADER:社交网络文本情感分析库
- Nginx配置中一个不起眼字符"/"的巨大作用,失之毫厘谬以千里
- 龙芯LS1C101单片机实验(1)--UART
- 要写码,又要做年终总结PPT?高效神器保住你的发际线