PyQuery: 爬虫界最简洁优雅的库
简洁的PyQuery库
pyquery库是jQuery的Python实现,能够以jQuery的语法来操作解析 HTML 文档,易用性和解析速度都很好。特别适合进行访问和解析网页数据。
PyQuery库官方文档 https://pythonhosted.org/pyquery/index.html
本文章节:
-
初始化为PyQuery对象
-
常用的CCS选择器
-
伪类选择器
-
查找标签
-
获取标签信息
- 高级方法
一、初始化为PyQuery对象
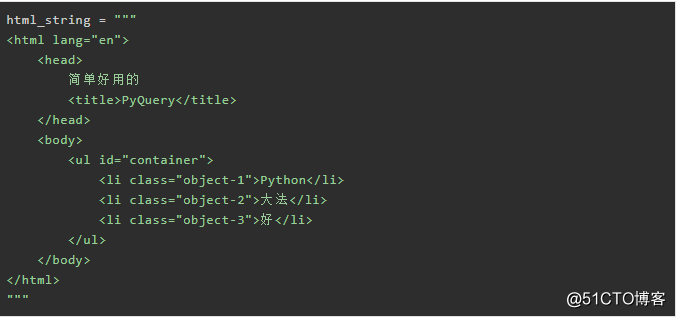
相当于BeautifulSoup库的初识化方法,将html转化为BeautifulSoup对象。
bsObj = BeautifulSoup(html, 'html.parser')
PyQuery库也要有自己的初始化。
1.1 将字符串初始化

Run
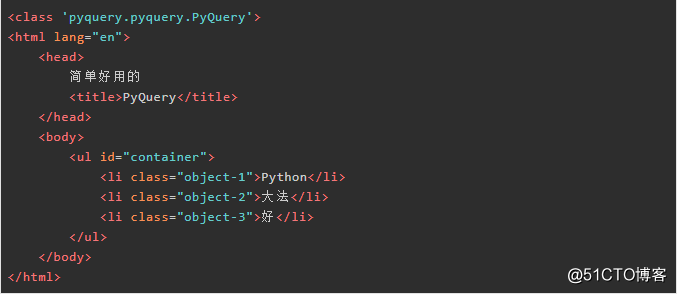
1.2 将html文件初始化

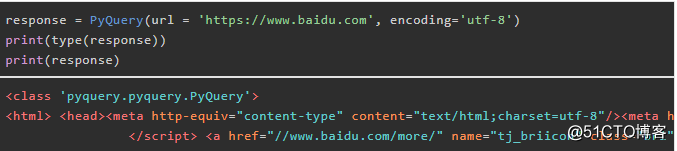
1.3 对网站访问并初始化

Run

上面的字符串出现乱码,所以需要设置使用encoding参数
二、常用的CCS选择器
从这一节开始,我们就要对PyQuery对象进行操作,获得我们想要的各种数据。你会看到解析网页,不论什么苦,基本原理实际上是没有区别的,学会了一种解析库。再看其他解析库文档,是很容易理解的。
在 CSS 中,选择器是一种模式,用于选择需要添加样式的元素。
常用的css选择器
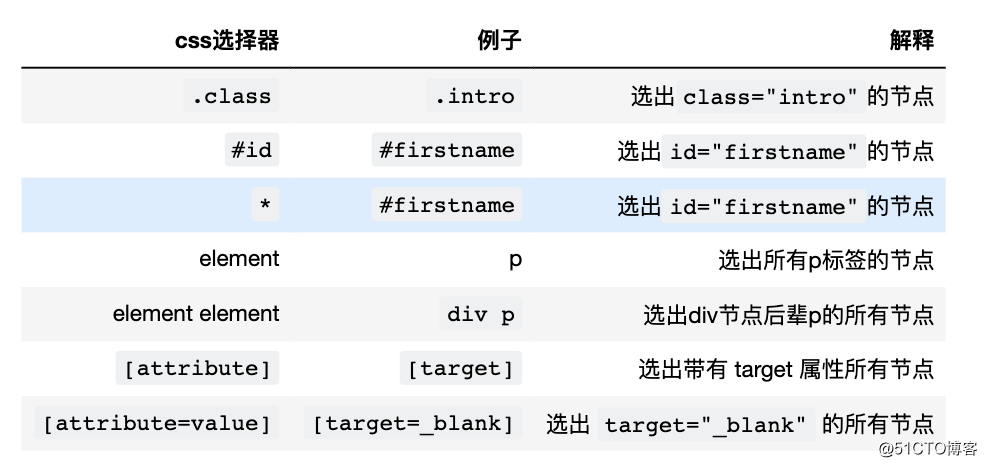
本文只讲clas id 和element最常见的css选择器。对css不太懂了,也没关系,可以去w3c官网的css选择器,查看下文档
#使用上文的doc
print ( doc )
Run
2.1 打印id为container的标签
print ( doc ( '#container' )) print ( type ( doc ( '#container' )))
Run
2.2 打印class为object-1的标签
print ( doc ( '.object-1' ))
Run
<li class = "object-1" > Python </li>
打印标签名为body的标签
print ( doc ( 'body' ))
Run
2.3 多种css选择器使用
选出ul节点,有很多种表达方式。比如ul节点(该ul节点中的属性键值对为id=container)
print ( doc ( "ul[id=container]" ))
Run

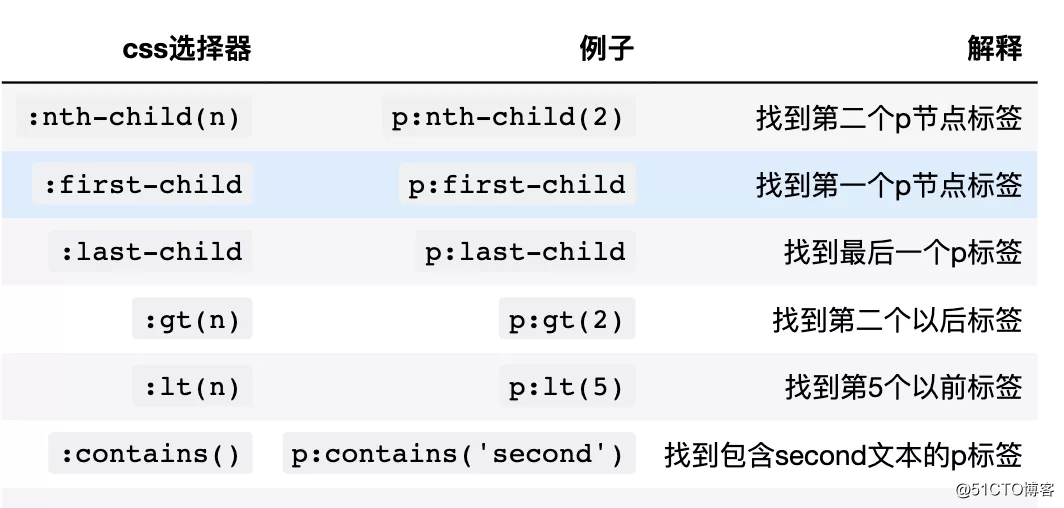
三、伪类选择器
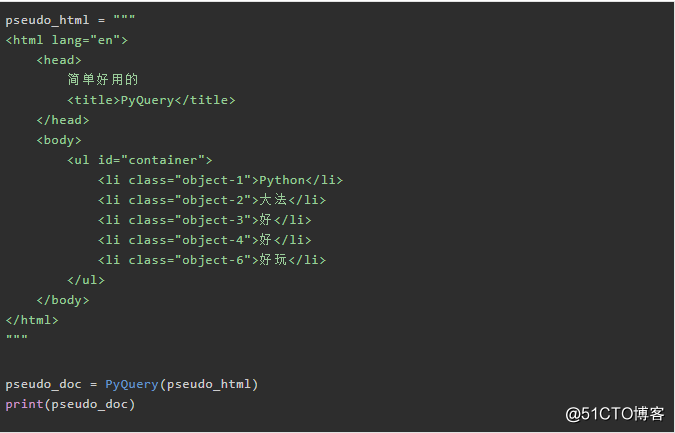
Run
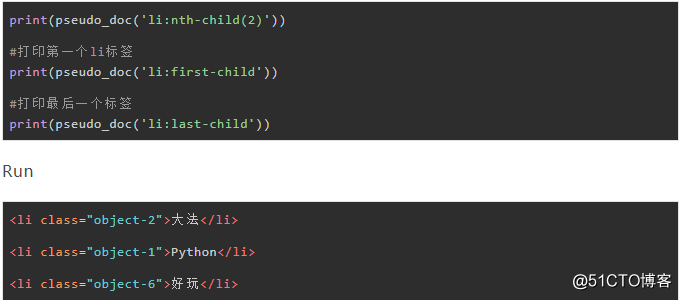
3.1 伪类nth
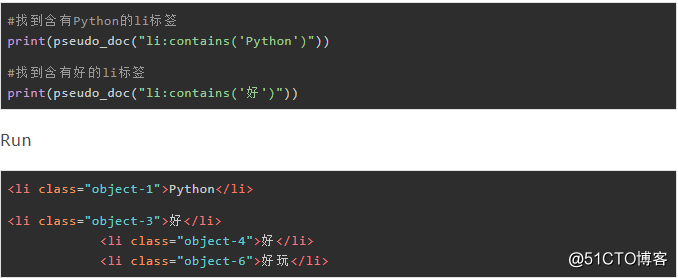
3.2 contains
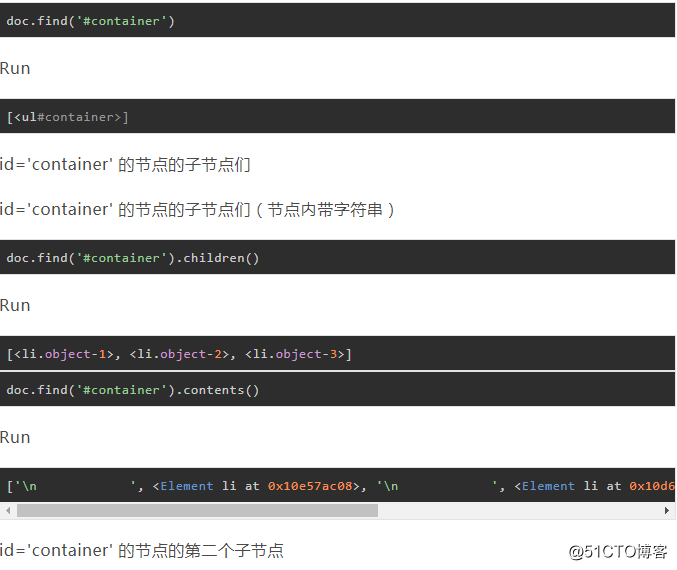
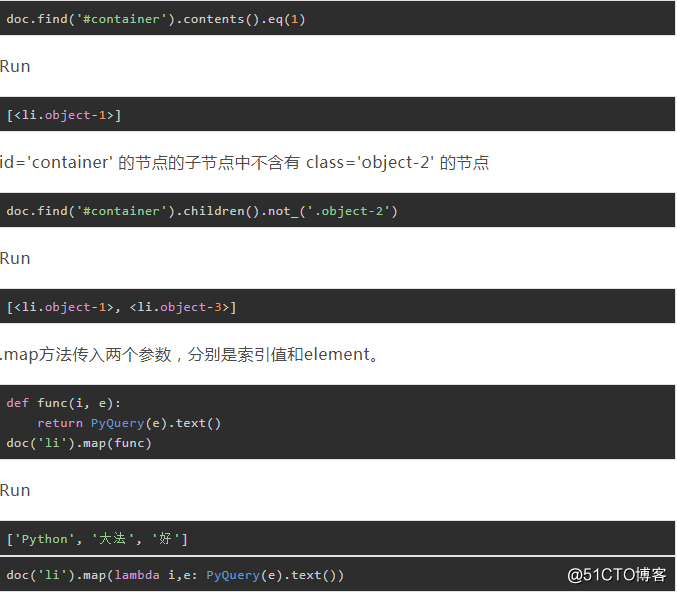
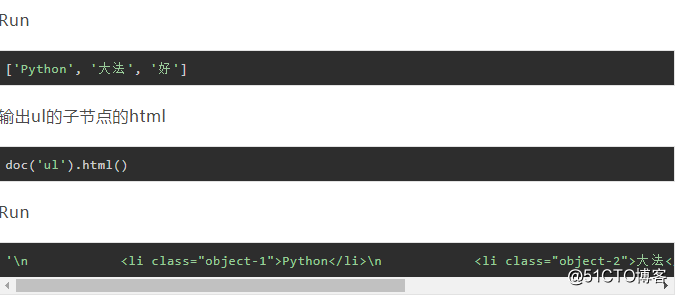
四、查找标签
PyQuery对象拥有很多实用的定位方法
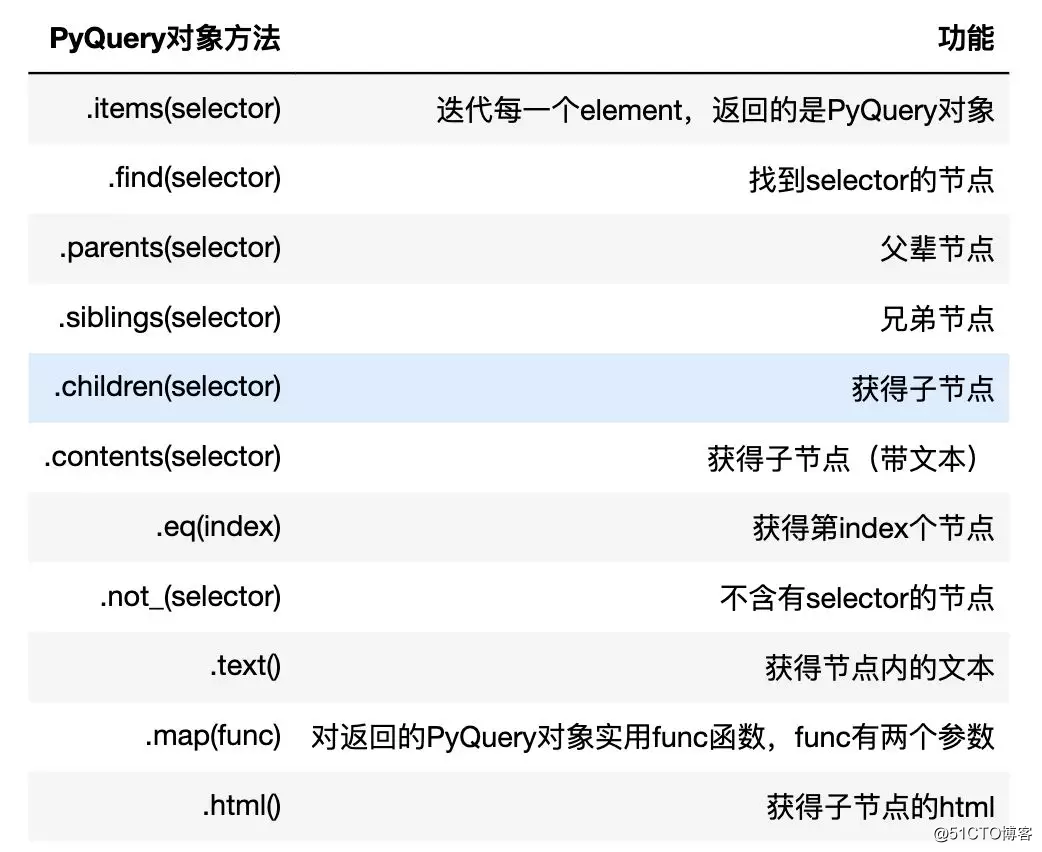
print ( doc )
Run
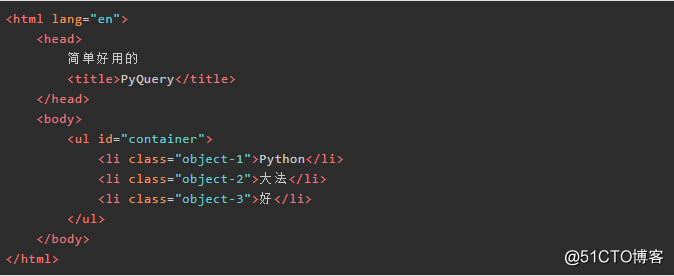
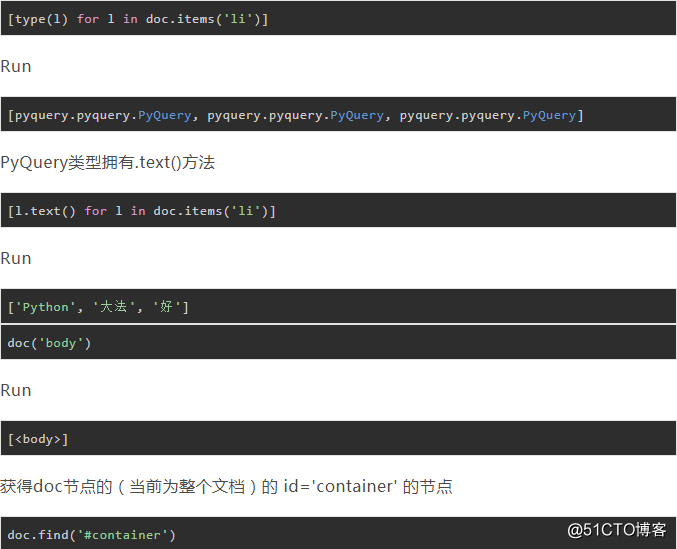
获得所有的li标签
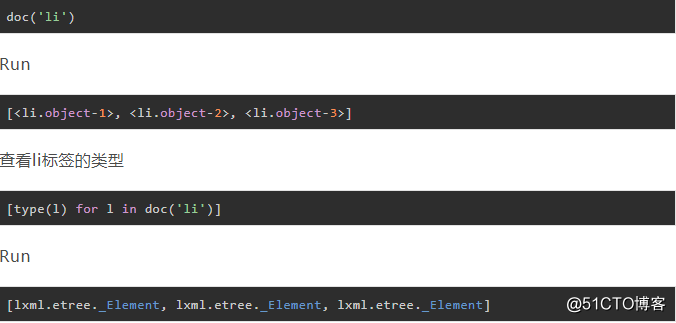
doc('li')返回的不是PyQuery类型,而是lxml.etree.Element类型。Element.text获取节点的文本内容
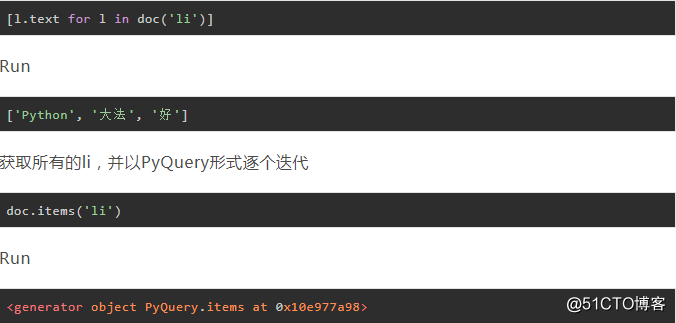
查看doc.items迭代出的对象的数据类型
五、pyquery高级用法
PyQuery与BeautifulSoup对比,我们会发现PyQuery可以对网址发起请求。比如

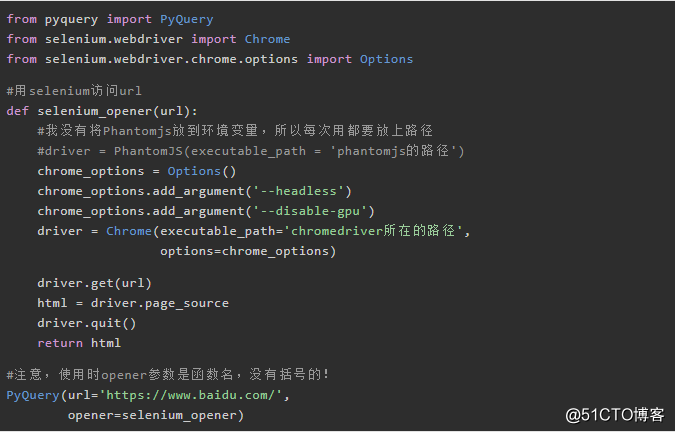
5.1 opener参数
PyQuery对百度网址进行请求,并将请求返回的响应数据处理为PyQuery对象。一般pyquery库会默认调用urllib库,如果想使用selenium或者requests库,可以自定义PyQuery的opener参数。
opener参数作用是告诉pyquery用什么请求库对网址发起请求。常见的请求库如urllib、requests、selenium。这里我们自定义一个selenium的opener。
Run
[< html >]
这时候我们就能上面学到的知识对PyQuery对象进行操作,提取有用的信息。
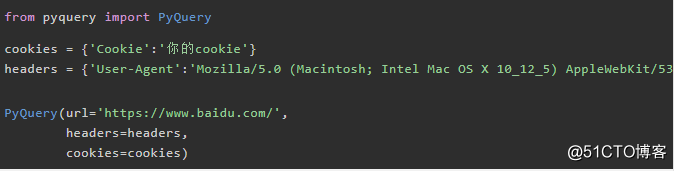
5.2 cookies、headers
在requests用法中,一般为了访问网址更加真实,模仿成浏览器。一般我们需要传入headers,必要的时候还需要传入cookies参数。而pyquery库就有这功能,也能伪装浏览器。
Run注意,我这里返回的内容你可能觉得很少,是因为这是PyQuery对象。PyQuery.html()
[< html >]
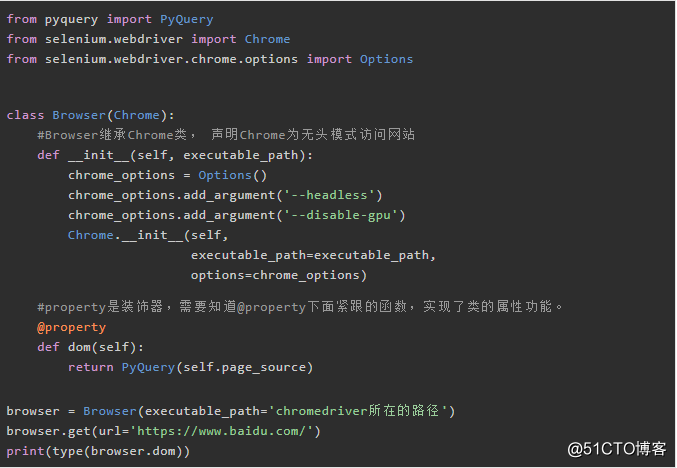
5.3 让你的selenium带上pyquery功能
如何让driver访问的网址得到的网页直接变为PyQuery对象,更方便提取数据?
本来我想用Phantomjs自定义一个类,让selenium拥有pyquery的功能。后来测试发现phantomjs去年不再支持selenium,因为曾经的无头浏览器phantomjs具有不可替代的作用,但如今chrome和firefox都能提供无头浏览器的功能。
Run
<class 'pyquery.pyquery.PyQuery' >
这几个对pyquery功能的扩展,我觉得实现方式很不错,很美观简洁,以后我会多模仿,比如用函数或类的方式,对已有的库及函数进行功能加持。
至于实战,大家可以看很久之前大邓分享的文章 pyquery爬取豆瓣读书

- 干货丨时序数据库DolphinDB与Druid的对比测试
- 专访|腾讯UI工程师@张鑫旭
- Azure Service Bus(二)在NET Core 控制台中如何操作 Service Bus Queue
- mybatis-plus的insert方法出现-id' doesn't have a default value问题
- 鸿蒙系统应用开发UI框架 | JS UI框架,跨设备的高性能UI开发框架
- OpenKruise v0.7.0 版本发布:新增周期任务分发控制器
- 脱离Editor、VS等IDE如何编译UE4工程
- 发现了新大陆给大家推荐一个编程猿(51xuebccom)
- Mac mysql 5.7启动报错,解决之道 The server quit without updating PID file
- ConcurrentLinkedQueue学习记
- Element-ui 中表单(Form)验证数字值范围(大小)
- Fielddata is disabled on text fields by default. Set fielddata=true on [XXX] in order to load fielddata in memory by uninverting the inverted index.
- 吃透 | Elasticsearch filter和query的不同
- ForkJoin、BlockingDeque、ReentrantLock的使用(BAT-JUC笔试题)
- rocketmq性能调优:broker快速失败判断maxWaitTimeMillsInQueue
- Abp(net core)+easyui+efcore实现仓储管理系统——出库管理之七(五十六)
- element-ui中Steps步骤条和Tabs标签页关联
- GitHub开源推荐 | 一个轻量级Qt UI库
- element-ui查看大图
- Elasticsearch Search API之(Request Body Search 查询主体