码农男友用 Python 写了个机器人,租到了让女友满意的房子
码农男友用 Python 写了个机器人,租到了让女友满意的房子

编程派微信号:codingpy
今天分享的这篇译文,讲述的是硅谷的一位工程师利用编程技能帮助自己又快又好地租房的故事。与编程派坚信的理念一致,而且讲述了从头利用代码解决实际需求的全过程。或许文中的代码对你来说没什么实际意义,但是其中的思路值得新手学习。
本文是 PythonTG 翻译组的最新译文,译者为 赵喧典,校对为编程派的作者 EarlGrey。
译者简介:赵喧典,浙江工业大学学生,专业是: 计算机科学与技术 + 自动化。爱玩,应用控,技术控,致力于成为高玩/技术宅,终极目标是 hacker/geek。
数月前,我从波士顿搬到了湾区。我和 Priya(我女朋友)都听说了各种关于租房市场的恐怖故事。事实是,找房子是一个痛苦的过程。在 Google 上搜索“怎样在旧金山租公寓”,得到的许多建议的页面就是很好的证明。

波士顿很冷,但在旧金山找房子很可怕
我们了解到一些房东会举行开放日(open house)活动,届时你需要带上所有的文件材料,并且只有当你交了押金才会被考虑。我们对流程进行了详尽的研究,发现找房子的时机很重要。一些房东举行开放日活动,任何人都可以参加,而对于另一些房东,第一个去看房往往更能租到房子。因此你需要找到房屋出租的消息,快速审核房子是否符合你的标准,然后打电话给房东安排看房,才有机会。
译注:在国外的房产交易行业中,开放日是一种新颖的房产销售方式。它允许对房子感兴趣的人们直接去参观房子。
我们浏览了网络上推荐的一些房子租赁网站,比如 Padmapper 和LiveLovely,但是没有一个网站能为我们提供一个可供查看与评估的实时信息,也没有一个网站能让我们指定额外的标准,比如特定的社区,或者交通便利性。绝大多数湾区房子的租赁信息原本都在 Craigslist 上,之后才被其他站点采集,这就造成了一点担忧:(其他站点)采集的租赁信息可能不全,或者它们采集得不够迅速,实时性不强。
我们想要这样:
当 Craigslist 上有新的公告时,实时地获得通知。
过滤掉不是我们期望的社区的房子。
过滤掉不满足额外标准的的房子,比如公共交通便利性。
整合房子的租赁信息,以便对它们进行评估。
对于我们感兴趣的房子,要能方便地联系房东。
对问题进行过思考后,我意识到我们可以分四步解决问题:
从 Craigslist 采集租赁信息。
过滤掉不匹配我们的标准的房子。
将租赁信息发送到 Slack,这是一个团队聊天工具,这样我们就能讨论并评估房子。
将整个过程封装进一个持续的循环中,并部署到服务器上(这样它就能一直运行了)。
在下文中,我们将介绍每一步是如何完成的,以及如何使用最终的 Slack 机器人帮助我们找房子。借助这个机器人,我和 Priya 在约一周之后就找到了一个我们都喜爱的,价格又合理(就旧金山而言)的卧室,这比我们预期要花费的时间少多了。
如果你想要在阅读本文的过程中看一看代码,项目链接在这里,README.md 的链接在这里。
第一步 - 从 Craigslist 采集租赁信息
创建机器人的第一步是从 Craigslist 获取租赁信息。不幸的是,Craigslist 并不提供 API,但是我们可以使用 python-craigslist 包来获得房子的公告。用
python-craigslist采集页面内容,再用 BeautifulSoup 从页面中提取出相关的部分,并转换成结构化的数据。这个包的代码相当简短,值得通读一遍。
Craigslist 网上,旧金山房子信息的网址是
https://sfbay.craigslist.org/search/sfc/apa。在下面的代码中,我们将:
导入
craigslistHousing
,这是python-craigslist
中的一个类。用以下参数初始化类:
site
- 要采集的 Craigslist 网站。site
是 URL 的第一部分,比如https://sfbay.craigslist.org
。area
- 要采集的网站下的分区。area
是 URL 的最后部分,比如https://sfbay.craigslist.org/sfc/
,仅代表旧金山。category
- 要查找的房子的类型。category
是搜索 URL 的最后部分,比如https://sfbay.craigslist.org/search/sfc/apa
,将列所有的房子。filters
- 应用于结果的任何过滤器。max_price
- 能承受的最高价min_price
- 要查找的最低价
使用
get_results方法从 Craigslits 获取结果,其实是一个生成器。
传入
geotagged参数以尝试为每条结果添加坐标。
传入
limit参数以只获取
20条结果。
传入
newest参数以只获取最新的租赁信息
从
results生成器中获取每条
result,并打印。
from craigslist import CraigslistHousing cl = CraigslistHousing(site='sfbay', area='sfc', category='apa', filters={'max_price': 2000, 'min_price': 1000}) results = cl.get_results(sort_by='newest', geotagged=True, limit=20)
for result in results:
print result我们已经快速地完成了机器人的第一步!现在,我们就可以对 Craigslist 进行采集并获取租赁信息了。每一条
Result都是带几个字段的字典:
{
'datetime': '2016-07-20 16:39',
'geotag': (37.783166, -122.418671),
'has_image': True,
'has_map': True,
'id': '5692904929',
'name': 'Be the first in line at Brendas restaurant!SQuiet studio available',
'price': '$1995',
'url': 'http://sfbay.craigslist.org/sfc/apa/5692904929.html',
'where': 'tenderloin'}下面是对字段的描述:
datetime
- 租赁信息公布的时间。geotag
- 租赁信息上标注的坐标位置。has_image
- Craigslist 公告上是否带图片。has_mag
- 租赁信息是否带有相应的地图。id
- 租赁信息在 Craigslist 上的 id。name
- Craigslist 上显示的名称。price
- 月租价。url
- 查看完整的租赁信息的 URL。where
- 租赁信息创建者标注的房子位置。
第二步 - 过虑结果
既然我们已经能够从 Craigslist 上获取租赁信息了,我们只需对它们进行过滤,就可以看到我们感兴趣的那些。
地区过滤
我和 Priya 在找房子时,我们只考虑了一部分区域,包括:
旧金山
日落区
太平洋高地
下太平洋高地
伯纳尔高地
列治文区
伯克利
奥克兰
亚当斯点
梅里特湖
岩石岭
阿拉米达
为了对社区进行过滤,我们首先需要定义包围盒(boundbing box),用于划出一个边界区域:
 在下太平洋区域画一个包围盒
在下太平洋区域画一个包围盒
上图中的包围盒是用 BoundingBox 创建的。在左下角选择
csv选项,以获得包围盒的顶点坐标。
你也可以使用像谷歌地图这样的工具,通过找出左下角和右上角的坐标来自定义包围盒。找出包围盒之后,我们创建一个社区与坐标的字典:
BOXES = { "adams_point": [ [37.80789, -122.25000], [37.81589, -122.26081], ], "piedmont": [ [37.82240, -122.24768], [37.83237, -122.25386], ], ... }用社区名做字典的键,每个键对应一个列表的列表。第一个内部列表表示包围盒左下角的坐标,第二个则表示右上角的坐标。然后,我们就可以通过检查坐标是否在某个包围盒内进行过滤。
下面的代码将:
遍历
BOXES
的键。检查结果是否在包围盒内。
若结果在包围盒内,设置合适的变量。
def in_box(coords, box): if box[0][0] < coords[0] < box[1][0] and box[1][1] < coords[1] < box[0][1]:
return True return False
geotag = result["geotag"] area_found = False
area = ""
for a, coords in BOXES.items():
if in_box(geotag, coords): area = a area_found = True
然而不幸的是, 并不是所有从 Craigslist 获取的结果都带有坐标信息。是否带坐标信息,取决于发布公告的人是否指定了位置,而坐标可以从位置中计算出。他对于在 Craigslist 发布公告越熟悉,那么他越有可能附上位置信息。
通常由代理中介发布的公告会带有位置信息,但他们往往会收取高额租金。房东自己发布的公告一般不带坐标信息,但也会更划算。因此,弄清楚那些不带坐标信息的房子是否在我们期望的社区很重要。我们将创建一个社区的列表,再进行字符串匹配,以检查那些房子是否落在其中。因为许多房子的社区信息是错误的,使得这样做的精确度不如使用坐标高,但聊胜于无。
NEIGHBORHOODS = ["berkeley north", "berkeley", "rockridge", "adams point", ... ]
要进行基于名字的匹配,我们可以对
NEIGHBORHOODS进行遍历:
location = result["where"] for hood in NEIGHBORHOODS: if hood in location.lower(): area = hood
采集结果经以上代码处理之后,我们就过滤掉了所有不在我们想要入住的社区中的房子。可能会有一些误报,我们会遗漏掉那些既没有社区信息也没有指定位置的房子,但这个系统已经记录了大量的住房信息。
根据交通便利性进行过滤
我和 Priya 都清楚我们会很频繁地去旧金山,因此如果我们不住在旧金山的话,我们就要住的离公交进一点。在湾区,公交的主要形式是 BART。BART 是一个半地下的交通系统,连接了奥克兰、伯克利、旧金山以及周围的区域。
为了在我们的机器人上实现这个基础功能,我们首先需要定义一个换乘站的列表。我们可以从谷歌地图获取换乘站的坐标,然后建一个字典:
TRANSIT_STATIONS = {
"oakland_19th_bart": [37.8118051,-122.2720873],
"macarthur_bart": [37.8265657,-122.2686705],
"rockridge_bart": [37.841286,-122.2566329], ... }每个键都是一个换乘站的名称,对应一个列表。该列表包括了换乘站的经度与纬度。一旦我们构建好了这个字典,我们就可以找出距离每条采集结果最近的换乘站。
下面的代码将:
对
TRANSIT_STATIONS
的键与值进行遍历。使用
coord_distance
函数来计算两个坐标间的距离(公里)。你可以在这里找到该函数的解释。检查站点是否距离房子最近。
忽略太远的站点(超过
2
公里,或约1.2
里)。若当前站点相比先前最近的站点还近,将其作为最近的站点。
min_dist = None
near_bart = False
bart_dist = "N/A"
bart = ""
MAX_TRANSIT_DIST = 2 # kilometers
for station, coords in TRANSIT_STATIONS.items(): dist = coord_distance(coords[0], coords[1], geotag[0], geotag[1])
if (min_dist is None or dist < min_dist) and dist < MAX_TRANSIT_DIST: bart = station near_bart = True if (min_dist is None or dist < min_dist): bart_dist = dist
这之后,我们就清楚距离每个房子最近的站点了。
第三步 - 创建Slack机器人
在对采集结果进行过滤后,我们就可以将现有的信息发送到 Slack 了。如果你对 Slack 不熟悉,它其实就是一个团队聊天应用。你在 Slack 上创建一个团队,之后就可以邀请成员了。每个 Slack 团队可以有多个频道,所谓频道,就是成员交换消息的地方。频道里的其他人可以对消息进行注释,比如点赞或添加其他表情。有关 Slack 更多的信息,请看这里。如果你想亲身体验一下 Slack,我们在 Slack 上有一个数据科学社区,如果你感兴趣的话,可以加入。
通过将结果发送到 Slack,我们就能够与其他人合作,并找出哪些房子是最好的。要实现这一点,我们需要:
创建一个 Slack 团队,我们可以在这里完成创建工作。
创建一个用于租赁信息发送的频道。帮助信息请看这里。建议使用
#housing
来命名频道。获取 Slack API Token,可以在这里获得。关于该过程的更多信息,请看这里。
完成这些步骤之后,我们就可以开始编写将房屋信息发送到 Slack 的代码了。
编起来
获得了频道名和 Token 之后,我们就可以将结果发送到 Slack 了。我们将使用 python-slackclient来实现,这是一个使 Slack API 更易于使用的 Python 包。使用 Slack token 来初始化
python-slackclient,然后我们通过它可以访问多个 API 端口,来管理团队与消息。
下面的代码将:
使用
SLACK_TOKEN
来初始化SlackClient
。利用
result
创建消息字符串,result
包含了我们需要的一切信息,比如价格,房子所在的社区,以及 URL。使用用户名
pybot
发送消息到 Slack,用机器人做头像。
from slackclient import SlackClient SLACK_TOKEN = "ENTER_TOKEN_HERE"
SLACK_CHANNEL = "#housing"
sc = SlackClient(SLACK_TOKEN) desc = "{0} | {1} | {2} | {3} | <{4}>".format(result["area"], result["price"], result["bart_dist"], result["name"], result["url"]) sc.api_call(
"chat.postMessage",
channel=SLACK_CHANNEL,
text=desc, username='pybot',
icon_emoji=':robot_face:')
一切都准备之后,Slack 机器人就可以发送房子信息到 Slack,看起来是这样的:
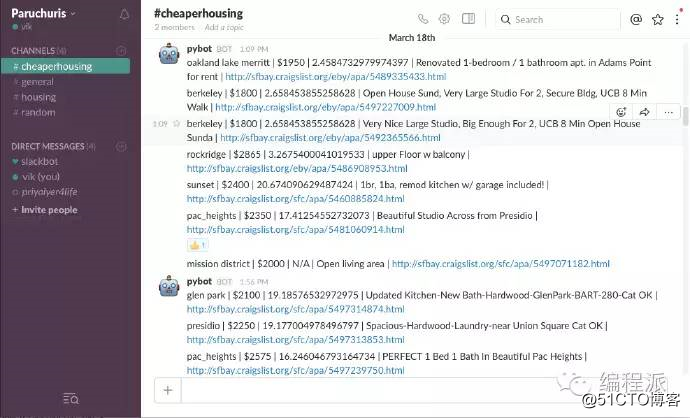 机器人运行时,房子的信息看起来是这样的。注意,你可以用表情来进行评论,比如点个赞。
机器人运行时,房子的信息看起来是这样的。注意,你可以用表情来进行评论,比如点个赞。
第四步 - 部署运行
既然我们已经把基础工作都做好了,现在就需要让代码持续地跑。毕竟,我们想要结果实时地被发送到 Slack 上。为了部署运行,我们需要完成以下步骤:
将租赁信息存储到数据库,这样,我们就不会重复地发送了。
从余下的代码中分离出设置的部分,以便更容易进行调整,比如
SLACK_TOKEN
。创建能持久运行的循环,这样,就能每周七天,每天二十四小时不间断地进行采集。
存储租赁信息
第一步是使用 Python 包 SQLAlchemy存储我们的租赁信息。 SQLAlchemy 是一个对象关系映射,或者说 ORM,它可以使 Python 与数据库的交互更简单。使用 SQLAlchemy,我们需要创建一张存储租赁信息的数据库表,以及一个数据库连接。使用数据库连接使向数据表添加数据更容易。
在使用 SQLAlchemy 的过程中,我们将配合使用 SQLite 数据库引擎。该数据库引擎会将我们所有的数据存储到一个单一的文件
listings.db。
下面的代码将:
导入 SQLAlchemy。
创建到 SQLite 数据库
listings.db
的连接,该文件将会被创建于当前目录。定义一张数据库表
Listing
,它包含了 Craigslist 租赁中所有相关字段。unique
属性的字段cl_id
和link
可以防止重复发送租赁信息到 Slack。
利用数据库连接创建会话,会话允许我们存储租赁信息。
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime, Float, Boolean
from sqlalchemy.orm import sessionmaker engine = create_engine('sqlite:///listings.db', echo=False) Base = declarative_base()
class Listing(Base): """ A table to store data on craigslist listings. """ __tablename__ = 'listings' id = Column(Integer, primary_key=True) link = Column(String, unique=True) created = Column(DateTime) geotag = Column(String) lat = Column(Float) lon = Column(Float) name = Column(String) price = Column(Float) location = Column(String) cl_id = Column(Integer, unique=True) area = Column(String) bart_stop = Column(String) Base.metadata.create_all(engine) Session = sessionmaker(bind=engine) session = Session()
既然有了数据库模型,我们只需要将每条租赁信息存储到数据库就可以了,就可以避免重复。
从代码中分离出配置部分
下一步就是从代码中分离出配置的部分。我们将创建一个称为
settings.py的文件,用于存储配置信息。配置信息包括
SLACK_TOKEN,这个需要保密,因此不需要也别提交到 git 再推送到 Github,其他的设置如
BOXES,不算私密,但我们希望能够进行简单地编辑。
我们将以下设置放在
settings.py中:
MIN_PRICE
- 要搜索的最低房价。MAX_PRICE
- 要搜索的最高房价。CRAIGSLIST_SITE
- 要搜索的 Craigslist 区域站点。AREAS
- 要搜索的 Craigslist 区域站点的地区列表。BOXES
- 要查看的社区的坐标包围盒。NEIGHBORHOODS
- 若房子信息中不带坐标信息,用社区列表去匹配。MAX_TRANSIT_DIST
- 期望的与公交换乘站的最大距离。TRANSIT_STATION
- 公交换乘站的坐标。CRAIGSLIST_HOUSING_SECTION
- 要查看的 Craigslist 住房分部。SLACK_CHANNEL
- 机器人发送消息的 Slack 频道。
我们还将创建一个
private.py文件,它包含以下字段,并设为被 git 忽略:
SLACK_TOKEN
- 发送到 Slack 团队的 token。
可点此查看最终的
settings.py文件。
创建循环
最后,我们需要创建一个循环,以持续运行采集代码。下面的代码将:
当通过命令行调用时:
打印包含当前时间的状态消息。
通过调用
do_scrape
函数运行 Craigslist 采集代码。当用户输入
Ctrl + C
时,退出。通过打印回溯信息来处理其他异常,继续执行不退出。
若无异常,打印一条成功的消息(对应于下述的
else
子句)。周期性地采集/休眠。默认的周期为
20
分钟。
from scraper import do_scrape
import settings
import time
import sys
import traceback
if __name__ == "__main__":
while True: print("{}: Starting scrape cycle".format(time.ctime()))
try: do_scrape()
except KeyboardInterrupt: print("Exiting....") sys.exit(1)
except Exception as exc: print("Error with the scraping:", sys.exc_info()[0]) traceback.print_exc()
else: print("{}: Successfully finished scraping".format(time.ctime())) time.sleep(settings.SLEEP_INTERVAL)
我们还需要将
SLEEP_INTERVAL添加到
settings.py中,以控制采集的频率。默认的周期是
20分钟。
运行
既然编程工作已经结束,让我们来看看怎么运行这个 Slack 机器人吧。
本地运行
你可以在
Github上找到该项目。在
README.md中,你可以看到更详细的安装说明。除非你对安装程序很有经验,并且正在使用 Linux,否则建议你按照 Docker部分的说明进行安装。Docker 是一个能使创建和部署应用更简单的工具。以这种方式,你可以很快地在本地计算机上运行 Slack 机器人。
下面是通过 Docker 安装运行 Slack 机器人的基本说明:
创建一个名为
config
的文件夹,将private.py
放到其中。在
private.py
中定义的任何设置,都会覆盖settings.py
中的同名默认设置。通过在
private.py
中添加设置,你可以自定义机器人的行为。
在
private.py中为上述设置项指定新的值。
比如,你可以在
private.py中添加
AREAS = ['sfc'],仅仅查看旧金山。
如果你想发送消息的 Slack 频道不叫
housing,设置
SLACK_CHANNEL的值。
如果你不想查看湾区的住房信息,你至少需要更新以下设置项:
CRAIGSLIST_SITE
AREAS
BOXES
NEIGHBORHOODS
TRANSIT_STATIONS
CRAIGSLIST_HOUSING_SECTION
MIN_PRICE
MAX_PRICE
根据这里的指示,安装 Docker。
使用默认配置运行机器人:
docker run -d -e SLACK_TOKEN={YOUR_SLACK_TOKEN} dataquestio/apartment-finder使用自定义配置运行机器人:
docker run -d -e SLACK_TOKEN={YOUR_SLACK_TOKEN} -v {ABSOLUTE_PATH_TO_YOUR_CONFIG_FOLDER}:/opt/wwc/apartment-finder/config dataquestio/apartment-finder部署机器人
除非你想要你的计算机 24/7 不间断地运行,否则有必要将机器人部署到服务器上,这样,它就能持续运行了。我们可以在主机提供商 DigitalOcean处创建服务器。DigitalOcean 可以自动创建一个带 Docker 的服务器。
这里是 DigitalOcean 上的 Docker 使用指南。如果你不清楚作者所谓的 “shell”,这里是一份使用 SSH 连接到 DigitalOcean 的教程。如果你不想看指南,可以从这里开始。
在 DigitalOcean 上完成服务器的创建之后,你可以用 ssh 连接的方式连接到服务器,然后按照上述 Docker 的安装与使用说明进行部署与使用。
接下来
完成上述的步骤之后,你就拥有了一个能自动帮你找房子的 Slack 机器人。使用这个机器人,我和 Priya 在旧金山找到了远超我们预期的好房子,并且价格比我们想象的旧金山一间卧室的价格还低。它还大大节省了我们的时间。尽管它已经为我们找到了房子,但仍有相当多可以扩展的地方:
利用 Slack 上的赞与踩,训练一个机器学习模型。
利用 API 自动拉取公交换乘站的位置。
添加其他的兴趣项,如公园。
添加健行指数或其他社区质量评分标准,比如犯罪。
自动解析房东的电话号码与邮箱。
自动打电话给房东,预约看房时间(如果你能做到这一点,你厉害)。
欢迎在 Github 上提交 pull requests 到本项目,并且如果该工具对你有帮助,请在此留下评论。期待看到你如何使用它!
Python 翻译组是EarlGrey@编程派发起成立的一个专注于 Python 技术内容翻译的小组,目前已有近 30 名 Python 技术爱好者加入。
翻译组出品的内容(包括教程、文档、书籍、视频)将在编程派微信公众号首发,欢迎各位 Python 爱好者推荐相关线索。
推荐线索,可直接在编程派微信公众号推文下留言即可。
欢迎转发至朋友圈。如无特殊注明,本公号所发文章均为原创或编译,如需转载,请联系「编程派」获得授权。
加群交流 Python 技术问题,请先阅读群规(点击蓝色字体),然后加编程派主页君为好友并说明愿意遵守群规。

- 如何用 Python 制作 GIF 动图?
- 基于Python的接口自动化-Requests模块
- 【转载】python实现dubbo接口的调用
- Python发送多人邮件报错
- Python实现自动刷抖音
- 使用 Pandas 在 Python 中绘制数据
- python实现UI界面化图书管理系统
- Python详细知识体系总结(2021版)
- 有限状态机(FSM)的简单理解和Python实现
- 基于 Python 的简单自然语言处理实践
- Python插入mysql的变量问题
- Python SyntaxError: invalid syntax错误分类
- Python分析世界幸福指数
- [Python] iupdatable包:Status 模块使用介绍
- Python最会变魔术的魔术方法,我觉得是它!
- Python爬虫之BeautifulSoup库
- Python爬虫之re正则
- 【爬虫】获取Github仓库提交纪录历史的脚本 python
- day013|python之模块02&目录01
- python脚本-批量修改文件名中相同的字符串