【短文本】短文本相似度算法研究

机器学习算法与自然语言处理出品
@公众号原创专栏作者 刘聪NLP
学校 | NLP算法工程师
知乎专栏 | 自然语言处理相关论文
短文本相似度,即求解两个短文本之间的相似程度;它是文本匹配任务或文本蕴含任务的一种特殊形式,返回文本之间相似程度的具体数值。然而在工业界中,短文本相似度计算占有举足轻重的地位。
例如:在问答系统任务(问答机器人)中,我们往往会人为地配置一些常用并且描述清晰的问题及其对应的回答,我们将这些配置好的问题称之为“标准问”。当用户进行提问时,常常将用户的问题与所有配置好的标准问进行相似度计算,找出与用户问题最相似的标准问,并返回其答案给用户,这样就完成了一次问答操作。
目前,短文本相似度算法可以分为三大类:(1)无监督相似度计算;(2)有监督相似度计算;(3)有监督+无监督相似度计算。
一、无监督相似度计算
首先使用大规模语料库通过word2vec训练出词向量,然后将短文本进行分词操作,并找出每个词对应的词向量,最后对短文本的所有词的词向量进行求和(也可以根据词性或规则进行加权求和)操作,获得该短文本的句子向量。对两个短文本句子向量进行距离度量,最终获得其相似度值。
距离度量的方法有:(1)欧式距离;(2)余弦距离;(3)曼哈顿距离;(4)切比雪夫距离;(5)闵可夫斯基距离;(6)马氏距离;(7)标准化欧式距离;(8)汉明距离;(9)杰卡德距离;(10)相关距离。
举例介绍欧式距离和余弦距离公式:
(1)欧式距离,也称欧几里得距离,是最常见的距离度量,衡量的是多维空间中两个点之间的绝对距离。
二维平面上点
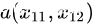 与
与
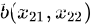 间的欧氏距离为 :
间的欧氏距离为 :
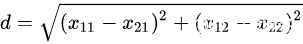
N维向量空间中点
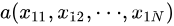 与
与
 间的欧氏距离为 :
间的欧氏距离为 :
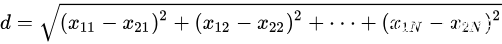
欧式距离值越小表示两个向量离的越近,即两个向量越相似。
(2)余弦距离,即使用两个向量的夹角余弦来衡量两个向量方向的差异。
二维空间中向量
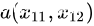 与
与
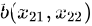 的夹角余弦公式:
的夹角余弦公式:

N维向量空间中向量
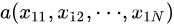 与
与
 间的夹角余弦公式为 :
间的夹角余弦公式为 :
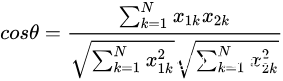
规定夹角余弦取值范围为[0,1]。余弦值越大表示两个向量的夹角越小,即两个向量越相似。
非监督学习方法,虽然可以较快得计算出相似度值,并且不需要标注预料。但是其句子向量的质量往往依赖于人为设置的词权值,易受到主管因素的影响,并且效果往往不尽如人意。
二、有监督相似度计算
有监督相似度计算,是在具有标注预料的条件下进行的,即根据标注数据进行深度学习建模,通过模型的端到端学习,直接求解出短文本的相似度值。目前,分为三种框架结构:(1)暹罗”架构;(2)“交互聚合”架构;(3)“预训练”架构。
1、“暹罗”架构:在该框架结构中,将两个短文本分别输入到相同的深度学习编码器中(如CNN或RNN),使得两个句子映射到相同的空间中,然后将得到得两个句子向量进行距离得度量,最终获取短文本的相似度值。代表模型是孪生网络【1】,如图1所示。
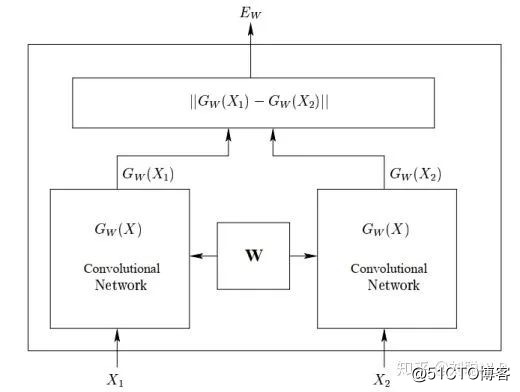
如图1 孪生网络模型结构图
其优点是共享参数使模型更小,更容易训练。虽然其短文本的句向量通过模型得出,具有一定的语义信息;但缺点也不容忽视,在映射过程中两个文本之间没有明确的交互作用,会丢失很多相互影响的信息。
2、“交互聚合”架构:该框架结构是针对于第一种框架结构的缺点而提出的,它的框架前部分与第一种框架相同,也是将两个文本分别输入到相同的深度学习编码器中得到两个句子向量,但之后不是直接将两个句子向量进行距离的度量,而是通过一种或多种注意力机制将两个句子向量进行信息的交互,最终将其聚合成一个向量,并通过值映射(全连接到一个节点)获取短文本的相似度值。代表模型有:ESIM【2】、BiMPM【3】、DIIN【4】和Cafe【5】等。如图2所示,
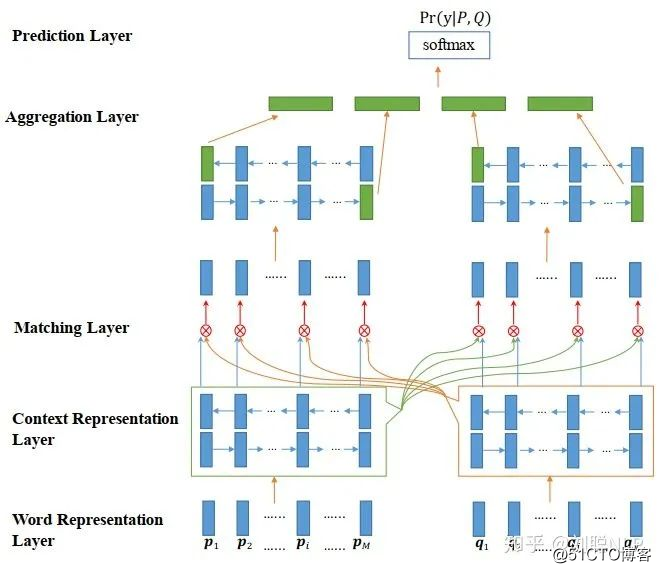
图2 BiMPM模型结构图
这种框架捕获了两句话之间更多的交互特性,因此它相较于第一种框架获得了显著的改进。
3、“预训练”架构:该框架结构来自近期较火的pre-trained模型(代表模型有:ELmo【6】,GPT【7】和BERT【8】等)。它主要采用两阶段模式,第一阶段使用很大的通用语料库训练一个语言模型,第二阶段使用预训练的语言模型做相似度计算任务,即将两个文本到预训练模型中,得到信息交互后的向量,并通过值映射(全连接到一个节点)获取短文本的相似度值。如图3所示,

图3 BERT模型结构图
这种框架通常具有很大的参数量,并且由于使用了很大通用语料库,使其普适性更好,可以获取两个短文本之间更隐蔽的交互特征,因此它相较于第二种框架也获取了一些改进。
虽然,监督学习方法比非监督学习方法求得的短文本相似度更加准确;但是,监督学习模型网络对计算要求较高。例如,如果我们想要从标准问库中找到一个与用户问题最相似的标准问,每一次一个新的用户问题来到时,我们都要与所有标准问题进行新的编码计算。如果标准问库很庞大时,需要大量的时间;而在事实问答场景中,用户很难去等待这么久。这也就是为什么监督学习模型效果虽好,但是现实问答机器人中依然采用无监督的方法的原因吧?
三、有监督+无监督相似度计算
鉴于无监督学习和有监督学习的优缺点,我们可以将其结合到一起,提高无监督学习的准确率并且降低有监督学习的时间成本。
那么如何去实现呢?
(1)无监督学习的弊端在于文本的句向量生成,通过词向量人为地加权求和并不能得到很好的句向量,并且得到的句向量也不包含上下文的语义信息。
我们可以使用监督学习的方法,去获取一个短文本的句向量。如上文所所,我们可以通过孪生网络获取到短文本的句向量,虽然没有两个文本句向量直接的相互信息,但是包含了各自文本的上下文语义信息。
(2)有监督学习的时间复杂度太高,为了避免每一次来一个新的文本,都将所有文本都计算一遍。我们舍弃文本之间的交互作用,直接使用生成好的句向量。
我们可以在问答系统或问答机器人启动阶段,先将标准问库中所有的标注问的句向量计算完成并存储;当一个用户问题过来时,我们只需要求解用户问题的句向量,然后与存储在库中的标准问句向量进行距离度量,最终就可以获得最相似的标准问了。节约了很大一部分时间成本。
(3)有监督学习可以获取优于无监督学习的句向量,那么如何可以提高句向量的质量呢?在2018年前,人们都是使用CNN或LSTM对其短文本进行编码,为获取更好的句子向量,但是效果一般,相较于无监督学习提高的程度也有限。同时又需要标注预料,其实在工业界使用价值并不明显。在2018年,BERT横空出世后,句向量的获取又被提高到了一个新的高度。借助于庞大的预训练语料库和模型参数,BERT模型称霸各大榜单的榜首,我们可以将BERT模型代替原来孪生网络中的CNN或LSTM结构,获取具有更多语义信息的句向量,将监督模型在工业界使用变成了可能。代表模型:Sentence-bert【9】。
由于BERT模型太过于庞大,我们还可以使用蒸馏模型的方法(有机会可以再次分享),将其进行蒸馏,来降低时间成本。
总结
本文介绍的短文本相似度计算方法,都是基于词向量的方法。还有一些传统的方法,例如TF-IDF、主题模型等,有兴趣的同学可以自行学习。
Reference:
[1]Learning a similarity metric discriminatively, with application to face verification
[2]Enhanced LSTM for Natural Language Inference
[3]Bilateral Multi-Perspective Matching for Natural Language Sentences
[4]Natural Language Inference over Interaction Space
[5]Compare, Compress and Propagate: Enhancing Neural Architectures with Alignment Factorization for Natural Language Inference
[6]Deep contextualized word representations
[7]Improving Language Understanding by Generative Pre-Training
[8]BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[9]Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
重磅!忆臻自然语言处理-学术微信交流群已成立
可以扫描下方二维码,小助手将会邀请您入群交流,
注意:请大家添加时修改备注为 [学校/公司 + 姓名 + 方向]
例如 —— 哈工大+张三+对话系统。
号主,微商请自觉绕道。谢谢!

推荐阅读:
全连接的图卷积网络(GCN)和self-attention这些机制的区别与联系
图卷积网络(GCN)新手村完全指南
论文赏析[ACL18]基于Self-Attentive的成分句法分析


- 基于同义词词林的文本相似度算法研究语料库
- 自己实现文本相似度算法(余弦定理)
- 实现文本相似度算法(余弦定理)
- 基于字的文本相似度算法——余弦定理
- .NET下文本相似度算法余弦定理和SimHash浅析及应用实例分析
- 基于大数据的推荐算法研究(2)——改进相似度
- 文本相似度算法(余弦定理)
- 自己实现文本相似度算法(余弦定理)
- 实现文本相似度算法(余弦定理
- java文本相似度计算(Levenshtein Distance算法(中文翻译:编辑距离算法))----代码和详解
- 基于字的文本相似度算法——Jacard算法
- 自己实现文本相似度算法(余弦定理) - 呼吸的Java - 开源中国社区
- 文本相似度算法(余弦定理)
- 自己实现文本相似度算法(余弦定理)
- 文本相似度算法——空间向量模型的余弦算法和TF-IDF
- 自己实现文本相似度算法(余弦定理)
- java文本相似度计算(Levenshtein Distance算法(中文翻译:编辑距离算法))----代码和详解
- 文本相似度的那些算法
- 文本相似度算法
- 自己实现文本相似度算法(余弦定理)