自己实现文本相似度算法(余弦定理)
2015-06-08 23:22
423 查看
最近由于工作项目,需要判断两个txt文本是否相似,于是开始在网上找资料研究,因为在程序中会把文本转换成String再做比较,所以最开始找到了这篇关于 距离编辑算法 Blog写的非常好,受益匪浅。
于是我决定把它用到项目中,来判断两个文本的相似度。但后来实际操作发现有一些问题:直接说就是查询一本书中的相似章节花了我7、8分钟;这是我不能接受……
于是停下来仔细分析发现,这种算法在此项目中不是特别适用,由于要判断一本书中是否有相同章节,所以每两个章节之间都要比较,若一本书书有x章的话,这里需对比x(x-1)/2次;而此算法采用矩阵的方式,计算两个字符串之间的变化步骤,会遍历两个文本中的每一个字符两两比较,可以推断出时间复杂度至少为 document1.length × document2.length,我所比较的章节字数平均在几千~一万字;这样计算实在要了老命。
想到Lucene中的评分机制,也是算一个相似度的问题,不过它采用的是计算向量间的夹角(余弦公式),在google黑板报中的:数学之美(余弦定理和新闻分类) 也有说明,可以通过余弦定理来判断相似度;于是决定自己动手试试。
首相选择向量的模型:在以字为向量还是以词为向量的问题上,纠结了一会;后来还是觉得用字,虽然词更为准确,但分词却需要增加额外的复杂度,并且此项目要求速度,准确率可以放低,于是还是选择字为向量。
然后每个字在章节中出现的次数,便是以此字向量的值。现在我们假设:
章节1中出现的字为:Z1c1,Z1c2,Z1c3,Z1c4……Z1cn;它们在章节中的个数为:Z1n1,Z1n2,Z1n3……Z1nm;
章节2中出现的字为:Z2c1,Z2c2,Z2c3,Z2c4……Z2cn;它们在章节中的个数为:Z2n1,Z2n2,Z2n3……Z2nm;
其中,Z1c1和Z2c1表示两个文本中同一个字,Z1n1和Z2n1是它们分别对应的个数,
最后我们的相似度可以这么计算:
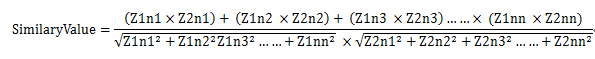
程序实现如下:(若有可优化或更好的实现请不吝赐教)
?
程序中做了两小的改进,以加快效率:
1. 只将汉字作为向量,其他的如标点,数字等符号不处理;2. 在HashMap中存放汉字和其在文本中对于的个数时,先将单个汉字通过GB2312编码转换成数字,再存放。
最后写了个测试,根据两种不同的算法对比下时间,下面是测试结果:
余弦定理算法:doc1 与 doc2 相似度为:0.9954971, 耗时:22mm
距离编辑算法:doc1 与 doc2 相似度为:0.99425095, 耗时:322mm
可见效率有明显提高,算法复杂度大致为:document1.length + document2.length。
原创blog,转载请注明/article/3478141.html
于是我决定把它用到项目中,来判断两个文本的相似度。但后来实际操作发现有一些问题:直接说就是查询一本书中的相似章节花了我7、8分钟;这是我不能接受……
于是停下来仔细分析发现,这种算法在此项目中不是特别适用,由于要判断一本书中是否有相同章节,所以每两个章节之间都要比较,若一本书书有x章的话,这里需对比x(x-1)/2次;而此算法采用矩阵的方式,计算两个字符串之间的变化步骤,会遍历两个文本中的每一个字符两两比较,可以推断出时间复杂度至少为 document1.length × document2.length,我所比较的章节字数平均在几千~一万字;这样计算实在要了老命。
想到Lucene中的评分机制,也是算一个相似度的问题,不过它采用的是计算向量间的夹角(余弦公式),在google黑板报中的:数学之美(余弦定理和新闻分类) 也有说明,可以通过余弦定理来判断相似度;于是决定自己动手试试。
首相选择向量的模型:在以字为向量还是以词为向量的问题上,纠结了一会;后来还是觉得用字,虽然词更为准确,但分词却需要增加额外的复杂度,并且此项目要求速度,准确率可以放低,于是还是选择字为向量。
然后每个字在章节中出现的次数,便是以此字向量的值。现在我们假设:
章节1中出现的字为:Z1c1,Z1c2,Z1c3,Z1c4……Z1cn;它们在章节中的个数为:Z1n1,Z1n2,Z1n3……Z1nm;
章节2中出现的字为:Z2c1,Z2c2,Z2c3,Z2c4……Z2cn;它们在章节中的个数为:Z2n1,Z2n2,Z2n3……Z2nm;
其中,Z1c1和Z2c1表示两个文本中同一个字,Z1n1和Z2n1是它们分别对应的个数,
最后我们的相似度可以这么计算:
程序实现如下:(若有可优化或更好的实现请不吝赐教)
?
1. 只将汉字作为向量,其他的如标点,数字等符号不处理;2. 在HashMap中存放汉字和其在文本中对于的个数时,先将单个汉字通过GB2312编码转换成数字,再存放。
最后写了个测试,根据两种不同的算法对比下时间,下面是测试结果:
余弦定理算法:doc1 与 doc2 相似度为:0.9954971, 耗时:22mm
距离编辑算法:doc1 与 doc2 相似度为:0.99425095, 耗时:322mm
可见效率有明显提高,算法复杂度大致为:document1.length + document2.length。
原创blog,转载请注明/article/3478141.html

相关文章推荐
- 提高Python运行效率的六个窍门
- HDU 4179 二维的Dijkstra
- 单链表的基本操作
- 代码: 日期和时间 datepicker
- Reverse Linked List
- 关于进程与线程的讲解 最最最生动的理解
- 算法导论习题-1.2-2
- Bit、 Byte_KB_MB_GB 间的关系
- 文本相似度计算基本方法小结
- 阅读JDK源码有感
- 看见 读书笔记
- MeTA is a modern C++ data sciences toolkit featuring
- startActivityForResult用法详解
- ubuntu14.04设置静态IP
- 2015年6月8日修习
- Oracle视图
- 前端开发大众手册(包括工具、网址、经验等)
- 安卓版微信自带浏览器和IE6浏览器ajax请求abort错误处理
- 下拉列表框Spinner-采用自定义布局文件作为Spinner样式
- 再回首,Java温故知新(九):Java基础之流程控制语句