【系统架构】大型网站架构演化历程(下)
在大型网站架构演化历程(上)(请戳我)中已经介绍了利用服务器分离、使用缓存、应用服务器集群来提高网站的性能。本文继续介绍优化服务器架构的其它几种方案。
数据库读写分离
网站在使用缓存后,使对大部分数据读操作访问都可以不通过数据库就能完成,但是仍有一部分读操作(缓存访问不命中、缓存过期)和全部的写操作都需要访问数据库,在网站的用户达到一定规模后,数据库因为负载压力过高而成为网站的瓶颈。 目前大部分的主流数据库都提供主从热备功能,通过配置两台数据库主从关系,可以将一台数据库服务器的数据更新同步到另一台服务器上。网站利用数据库的这一功能,实现数据库读写分离,从而改善数据库负载压力。如下图所示:
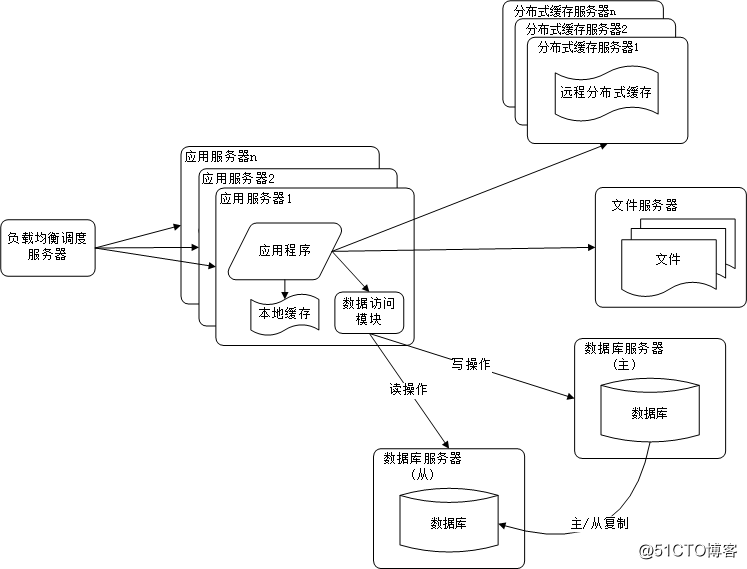
应用服务器在写数据的时候,访问主数据库,主数据库通过主从复制机制将数据更新同步到从数据库,这样当应用服务器读数据的时候,就可以通过从数据库获得数据。为了便于应用程序访问读写分离后的数据库,通常在应用服务器端使用专门的数据访问模块,使数据库读写分离对应用透明。
使用反向代理和CDN加速网站响应
随着网站业务不断发展,用户规模越来越大,由于中国复杂的网络环境,不同地区的用户访问网站时,速度差别也极大。有研究表明,网站访问延迟和用户流失率正相关,网站访问越慢,用户越容易失去耐心而离开。为了提供更好的用户体验,留住用户,网站需要加速网站访问速度。主要手段有使用 CDN 和反向代理。如下图所示:
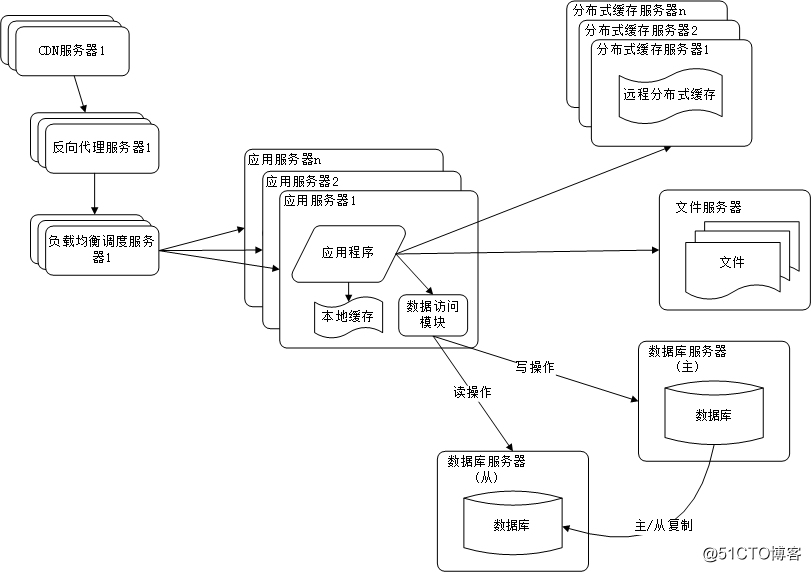
CDN 和反向代理的基本原理都是缓存。使用 CDN 和反向代理的目的都是尽早返回数据给用户,一方面加快用户访问速度,另一方面也减轻后端服务器的负载压力。
(1) CDN 部署在网络提供商的机房,使用户在请求网站服务时,可以从距离自己最近的网络提供商机房获取数据
(2) 反向代理则部署在网站的中心机房,当用户请求到达中心机房后,首先访问的服务器是反向代理服务器,如果反向代理服务器中缓存着用户请求的资源,就将其直接返回给用户
使用分布式文件系统和分布式数据库
任何强大的单一服务器都满足不了大型网站持续增长的业务需求。数据库经过读写分离后,从一台服务器拆分成两台服务器,但是随着网站业务的发展依然不能满足需求,这时需要使用分布式数据库。文件系统也一样,需要使用分布式文件系统。如下图所示:
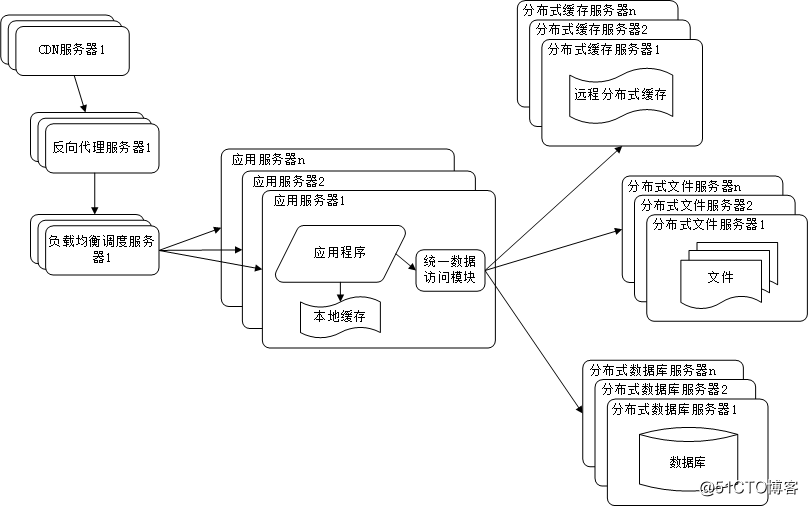
分布式数据库是网站数据库拆分的最后手段,只有在单表数据规模非常庞大的时候才使用。不到不得已时,网站更常用的数据库拆分手段是业务分库,将不同业务的数据部署在不同的物理服务器上。
使用Nosql和搜索引擎
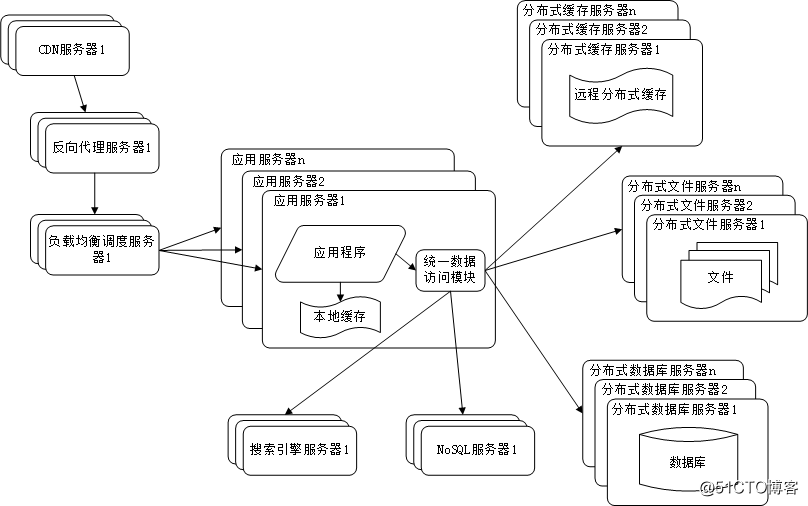
随着网站业务越来越复杂,对数据存储和检索的需求也越来越复杂,网站需要采用一些非关系数据库技术如 NoSQL 和非数据库查询技术如搜索引擎。如下图所示:
业务拆分
大型网站为了应对日益复杂的业务场景,通过使用分而治之的手段将整个网站业务分成不同的产品线。如大型购物交易网站都会将首页、商铺、订单、买家、卖家等拆分成不同的产品线,分归不同的业务团队负责。
具体到技术上,也会根据产品线划分,将一个网站拆分成许多不同的应用,每个应用独立部署。应用之间可以通过一个超链接建立关系(在首页上的导航链接每个都指向不同的应用地址),也可以通过消息队列进行数据分发,当然最多的还是通过访问同一个数据存储系统来构成一个关联的完整系统,如下图所示:
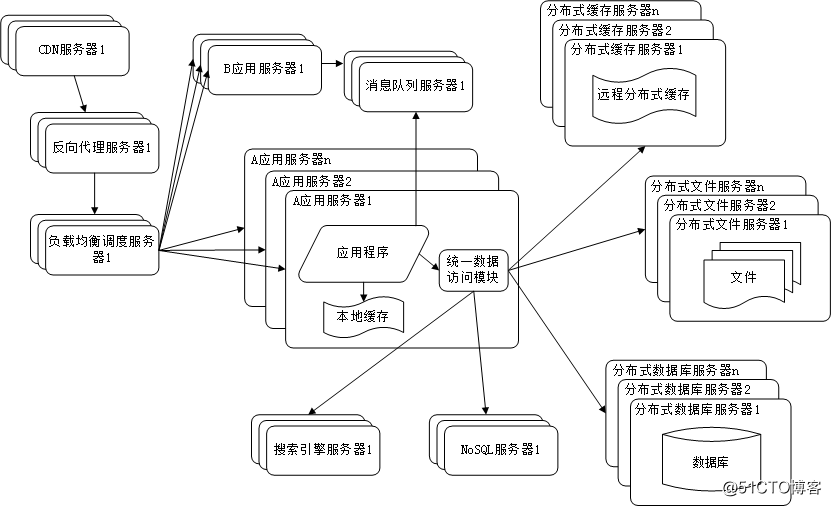
分布式服务
随着业务拆分越来越小,存储系统越来越庞大,应用系统的整体复杂度呈指数级增加,部署维护越来越困难。由于所有应用要和所有数据库系统连接,在数万台服务器规模的网站中,这些连接的数目是服务器规模的平方,导致数据库连接资源不足,拒绝服务。
既然每一个应用系统都需要执行许多相同的业务操作,比如用户管理、商品管理等,那么可以将这些共用的业务提取出来,独立部署。由这些可复用的业务连接数据库,提供共用业务服务,而应用系统只需要管理用户界面,通过分布式服务调用共用业务服务完成具体业务操作。如下图所示:
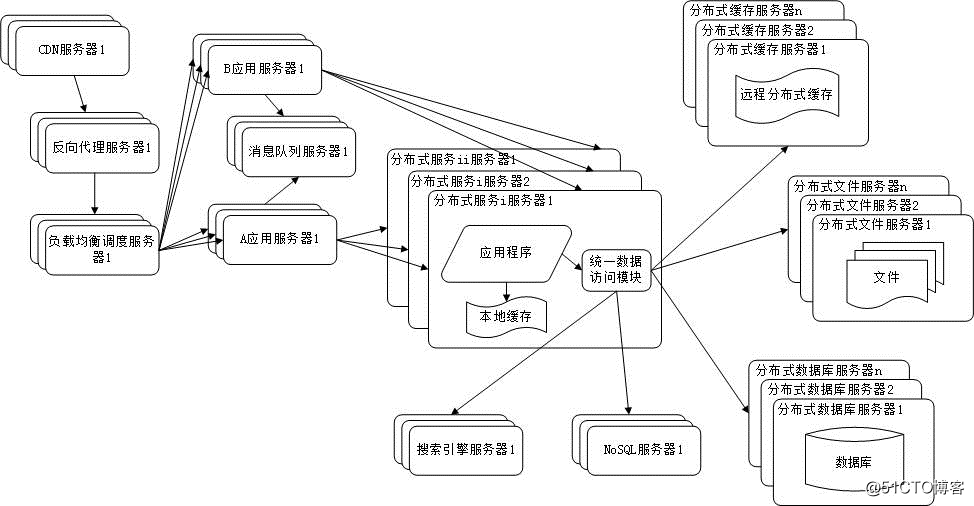
参考资料:<<大型网站技术架构>>
推荐阅读:
精心整理 | 历史干货文章目录
【福利】自己搜集的网上精品课程视频分享(上)
【数据结构与算法】 通俗易懂讲解 二叉树遍历
【数据结构与算法】 通俗易懂讲解 二叉搜索树
专注服务器后台技术栈知识总结分享
欢迎关注交流共同进步

码农有道 coding
码农有道,为您提供通俗易懂的技术文章,让技术变的更简单!
