数据集研究1——Dureader全文翻译
1、特点简介
 从用户搜索日志中分析得到。每中问题判定分为属于两类 中的哪一类:事实类,观点类。
从用户搜索日志中分析得到。每中问题判定分为属于两类 中的哪一类:事实类,观点类。
关于实体问题,答案应为单个实体或实体列表。
描述问题的答案通常是多句总结。
说明问题包含如何/为什么问题,比较两个或多个对象的比较问题以及询问商品优缺点的问题,等等。
对于是否问题,答案应为肯定的或否定的支持证据。
在对样本问题进行深入分析之后,我们发现,无论期望的答案类型是什么,一个问题都可以进一步分类为事实还是观点,这取决于它是询问事实还是观点。
表2 给出了六种问题的示例。
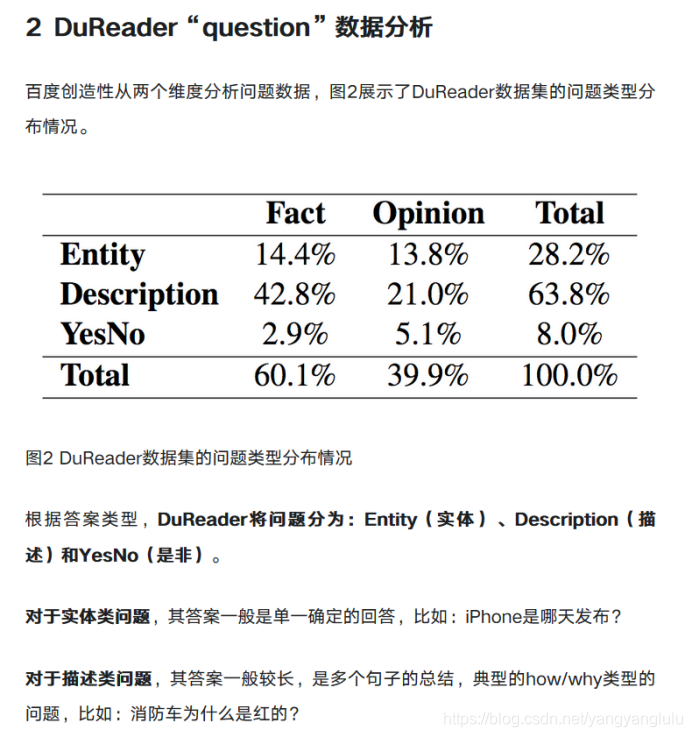
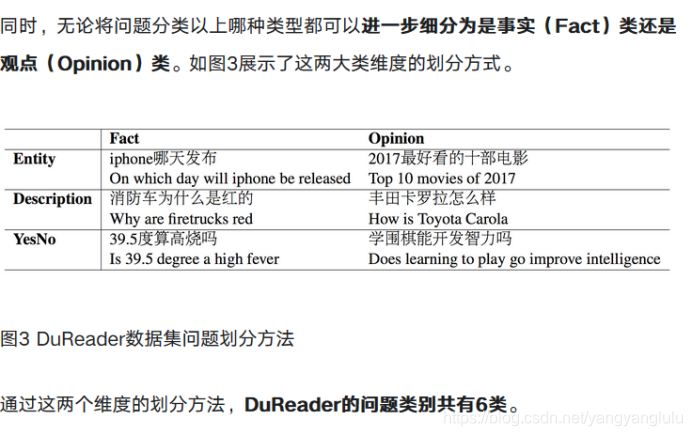
以前的MRC数据集强调了跨选择方法。这种方法适用于事实实体和事实描述,但当回答涉及多个文档中的多个句子的摘要时,就有问题了,特别是对于Yes-no和opinion问题。这需要一些方法超越当前流行的方法,比如span选择,并为社区留下大量的机会。

3、数据集构建:
数据收集:
成功完成试点研究后,我们开始着手将相对 较小的1k个问题样本扩大到更雄心勃勃的20 万个问题集合 。
DuReader是一个由4个元组组成的序列:{q, t,D,A},其中q是一个问题,t是一个问题类型,D是一组相关文档,而A是答案由人工标注。选取Q。通过搜索标注答案:从搜索日志中选择一组问题q。根据我们的估计,搜索日志中大约有21%的问题查询。如果人工注释者在搜索日志中手动标记每个查询,则将花费太多时间。因此,我们首先从搜索日志中随机抽取最频繁的查询,然后使用经过预先训练的分类器(召回率高于90%)从搜索日志中自动选择问题查询。然后,工作人员将注释分类器选择的问题查询。由于此注释任务相对容易,因此每个查询都由一 个工作人员注释。专家将进一步检查工作人 员的所有注释,如果注释错误,则对其进行更正。工人批注的准确性(由专家判断)高于98%。
最初,我们从搜索日志中采样了100万个频繁查询。分类器自动选择280K问题查询。在人工注释之后,还剩下210K问题查询。最后,我们从210K问题查询中统一抽样了200K个问题。
然后,我们通过向两个来源(百度搜索和 百度知道)提交问题来收集相关文档D。请注意,这两个来源彼此非常不同;Zhidao包含用户生成的内容,并且倾向于拥有更多与意见相关的文档。由于两个来源之间的差异如此之大,我们决定将200k个独特问题随机分为两个子集。第一个子集用于从一个来源生成排名前5的文档,第二个子集用于从另一个来源生成排名前5的文档。
我们还认为,与以前的工作只保留一个段落(Rajpurkar等。, 2016)或几个段落(Nguyen等。, 2016).在这种情况下,段落选择(即选择可能包含答案的段落)对于MRC系统至关重要,这将在第4节中显示。文档被解析为几个字段,包括标题和主要内容。使用标准API将文本标记为单词。
3.1.2 问题类型注释
如上所述,注释者分两遍标记每个问题。第一遍将问题分为以下三种类型之一:实体、描述和是否问题。第二遍将问题分类为事实或观点。表4中报告了有关这些分类的统计数据。请 注意,这些统计数据与先导研究报告的统计 数据相似(表3),但由于从表4中删除了重 复项(但未从表3中删除)而有所不同。我们不想给注释者增加很多最常见问题的副本, 因此我们在DuReader中保留了独特的问题。 就是说,两个表格在许多重要方面都达成了 共识。如上所述,以前的工作往往集中在事实性和事实描述上,而在“是”和“意见”问题上留下了很大的机会。
3.1.3 答案注释
众包被用来产生答案。特克斯给了他们一个问题和一系列相关文件。然后要求他/她通过阅读和总结文档以自己的语言写下答案。如果在相关文档中找不到答案,则要求注释者提供空白答案。如果在相关文档中可以找到多个答案,则要求注释者将其全部写下来。在某些情况下,当确定多个答案彼此非常相似时,会将多个答案合并为一个答案。请注意,关于“实体”问题和“是”问题的答案更加多样化。实体问题的答案包括实体和包含它们的句子。请参阅表中的第一个示例5.粗体字(即绿色,灰色,黄色,粉红色)是问题的实体答案,而实体后面的句子是包含这些问题的句子。YesNo问题的答案包括意见类型(Yes,No或Depend)以及支持语句。请参阅表中的最后一个示例5.粗体字(即“是”和“从属”)是遵循支持语句的意见类型。第二个示例表明,一个简单的是非问题并不是那么简单。答案几乎可以是任何东西,不仅包括“是”和“否”,还包括“取决于”,取决于上下文(支持语句)。
3.1.4 质量控制
由于该项目的规模,质量控制很重要:51个工时,分配了408个工时,约800名工人和52名专家。我们有一个内部众包平台和注释准则来注释数据。在为答案添加注释时,将雇用工人来创建答案,并雇用专家来验证答案的质量。如果工人通过了一个小型数据集的考试,他们将被雇用。工人标注的准确性应高于95%(由专家判断)。答案注释基本上分为三轮:(1)工人在阅读相关文档后将给出问题的答案。(2)专家将审核工人创建的所有答案,如果认为答案有误,将对其进行更正。工人回答的准确性(由专家判断)约为90%。(3) 根据对数据进行注释的工作人员和专家,该数据集分为20组。每个组将抽取5%的数据。 每个组中的采样数据将由其他专家再次检查。如果准确性低于95%,则相应的工人和专家需要再次修改答案。循环将结束,直到整体精度达到95%。
3.1.5 培训,开发和测试集
为了最大化数据集的可重用性,我们将数据集预先定义为培训,开发和测试集。培训,开发和测试集分别包含181K,10K和10K问题,855K,45K和46K文档,376K,20K和21K答案。。有人可能会认为大多数问题都会有一个(也只有一个)答案,但是1 表明事实并非如此,特别是对于百度知道(百度知道中70.8%的问题有多个答案,而百度搜索中的问题率为62.2%),其意见和主观性的余地更大,因此答案集的多样性也就更大。同时,我们可 以看到在百度搜索中有1.5%的问题的答案为零,但在百度知道中,该问题的答案增加到了9.7%。在后一种情况下,没有答案检测是一个新的挑战。

编辑距离
基于先前的工作,可能还曾尝试过一种跨度选择方法,这是基于这种方法
在以前的数据集上的成功,其中许多数据集是 为 跨 度 选 择 而 设 计 的 , 例 如 : SQuAD (Rajpurkar等。, 2016), NewsQA (Trischler等2017)和TriviaQA(Joshi等。, 2017).但是,这在DuReader上可能效果不佳,因为人工生成的答案与源文档之间的差异很大。为了测量差异,我们使用人类和源文档生成的答案之间的最小编辑距离(MED)作为近似度量较大的MED意味着注释者需要在汇总
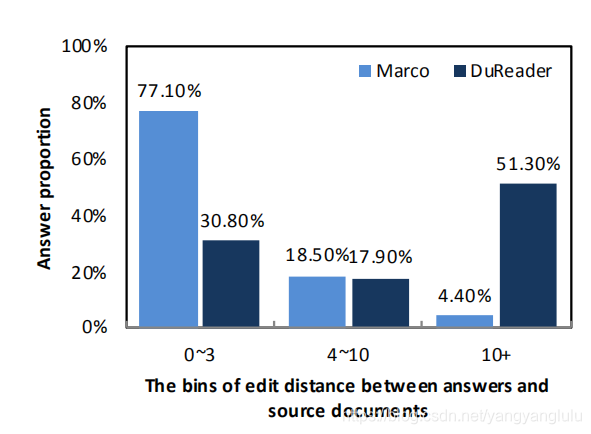 调整和释义源文档以生成答案,而不仅仅是复制源文档中的单词。图 2 在 MED 方面对DuReader和MS-MARCO进行了比较,并表明跨 度选择不太可能适用于DuReader,因为与MSMARCO相比,许多答案都离源文档相对较远。请注意,SQuAD,NewsQA和TriviaQA的MED应 该为零。 文件长度。在DuReader中,与答案(69.6 个单词)相比,问题往往较短(平均4.8个单 词),与文档(平均396个单词)相比,答案 往往较短。DuReader中的文档比MS-MARCO中 的文档长5倍(阮 等。, 2016).差异是由于设计决定提供未删节的文档(与段落相对)。 我们认为未删节的文档可能会有所帮助,因 为整个文档中可能会有有用的线索,远远超出了单个段落或几段。
调整和释义源文档以生成答案,而不仅仅是复制源文档中的单词。图 2 在 MED 方面对DuReader和MS-MARCO进行了比较,并表明跨 度选择不太可能适用于DuReader,因为与MSMARCO相比,许多答案都离源文档相对较远。请注意,SQuAD,NewsQA和TriviaQA的MED应 该为零。 文件长度。在DuReader中,与答案(69.6 个单词)相比,问题往往较短(平均4.8个单 词),与文档(平均396个单词)相比,答案 往往较短。DuReader中的文档比MS-MARCO中 的文档长5倍(阮 等。, 2016).差异是由于设计决定提供未删节的文档(与段落相对)。 我们认为未删节的文档可能会有所帮助,因 为整个文档中可能会有有用的线索,远远超出了单个段落或几段。
**
4 实验
**
在本节中,我们使用两个最新模型来实施和评估基线系统。此外,借助我们数据集中的丰富注释,我们从不同角度进行了综合评估。
4.1 基线系统
正如我们在上一节中讨论的那样,DuReader为每个问题提供了完整的文档
包含多段或多段,而以前的工作仅提供了一 个段( Rajpurkar 等 。 , 2016 ) 或 几 段(Nguyen等。, 2016)以提取或生成答案。每个文档的平均长度比以前的文档长得多(Nguyen等。, 2016).如果我们直接应用为回答跨度选择而设计的最新MRC模型,则会出现效率问题。为了提高培训和测试的效率,我们设计的系统分两个步骤:(1)从每个文档中选择一个最相关的段落,(2)将最新的MRC模型应用。
4.1.1 段落选择
在本文中,我们采用简单的策略从每个文档中选择最相关的段落。在训练阶段,如果该段落与人工生成的答案重叠最大,则从文档中选择一个段落作为最相关的段落。我们为每个文档选择一个最相关的段落。然后,将针对这些选定的段落训练为答案跨度选择而设计的MRC模型。 在测试阶段,由于没有人工生成的答案,因此我们选择与相应问题重叠度最高的最相关的段落。然后,将为这些选择的段落应用为答案跨度选择而设计的训练有素的MRC模型。
4.1.2 回答跨度选择
我们实现了两个典型的最新模型,这些模型设计用于选择答案范围作为基线。Match-LSTM Match-LSTM是一种广泛使用的MRC模型,在最近的研究中得到了很好的探索(王江, 2017).要在段落中找到答案,它会依次遍历该段落,并动态汇总关注加权问题表示与该段落的每个标记的匹配。最后,答案指针层用于在段落中找到答案范围。 BiDAF BiDAF是一种很有前途的MRC模型,其改进版本在SQuAD数据集上获得了最佳的单模型性能(徐等。, 2016).它同时使用上下文到问题的注意和问题到上下文的注意,以便突出问题和上下文中的重要部分。之后,所谓的注意流程层用于融合所有有用的信息,以便获取每个位置的矢量表示。实现细节我们随机地将单词嵌入的维数初始化为300,并将所有层的隐藏矢量大小设置为150。我们使用亚当算法(Kingma and Ba, 2014)训练两种MRC模型,初始学习率为0.001,批量为32。
4.2 结果与分析
我们通过字符级BLEU-4(Papineni等。, 2002)和Rouge-L(林, 2004),广泛用于评估语言 生成的质量。表中显示了测试集上的实验结果6.为了进行比较,我们还将评估与所有文档中的问题重叠度最大的所选段落。我们还通过聘用新的注释者对测试数据进行注释并将其第一个答案作为预测来评估人类的表现。结果表明,与所选段落基线相比,当前的阅读理解模型可以实现令人印象深刻的改进,这证明了这些模型的有效性。但是,这些模型与人之间仍然存在较大的性能差距。一个有趣的发现来自百度搜索结果和百度知道数据之间的比较。我们发现,阅读理解模型在直道数据上得分更高。这表明,与从问题回答的段落中找到答案相比,模型理解开放域网络文章要困难得多社区。相比之下,人类在这两个数据集上的表现几乎没有差异,这表明人类的阅读能力在不同类型的文档上更为稳定。
如本节所述4.1,则根据文档在测试阶段与相应问题的重叠程度来选择每个文档中最相关的段落。为了分析段落选择的效果并获得基线MRC模型的上限,我们对黄金段落重新评估了我们的系统,如果每个段落与文档中人工生成的答案重叠最大,则选择每个段落。实验结果列于表7.比较表7 与表6,我们可以看到,使用金色段落可以显着提高整体效果。 而且,直接使用黄金段落可以获得很高的Rouge-L分数。它符合例外,因为每个黄金段落都是根据与Rouge-L相关的召回进行选择的。但是,我们发现基准模型相对于BLEU可以获得更好的性能,这意味着模型已经学会了选择答案。这些结果表明,段落选择是在实应用中要解决的关键问题,而大多数当前的MRC数据集都想在较小的段落或段落中找到答案。相反,DuReader提供了每个文档的全文,以激发现实世界中的研究。为了更深入地了解数据集的特征,我们在表格中报告了不同问题类型的表现8.我们可以看到,模型和人类在描述问题上都取得了相对较好的表现,而YesNo问题似乎是最难建模的模型。我们认为描述性问题通常在同一主题上用长文本回答。BLEU或Rouge首选此方法。但是,“是”问题的答案相对较短,在某些情况下可能是简单的“是”或“否”。
4.3 意见意识评估
考虑到YesNo问题的特征,我们发现不适合直接使用BLEU或Rouge评估这些问题的表现,因为这些指标无法反映答案之间的一致性。例如,两个相互矛盾的答案,例如“您可以做到”和“您不能做到”,在这些指标上获得了较高的一致性得分。一个自然的想法是将此子任务表述为分类问题。但是,如本节所述3,可以基于从不同文档中收集的证据做出多种不同的判断,尤其是当问题属于观点类型时。在实际环境中,我们不希望智能模型对诸如“是”或“否”之类的问题给出任意答案。为了解决这个问题,我们提出了一种新颖的意见感知评估方法,该方法要求被评估系统不仅以自然语言输出答案,而且还给它一个意见标签。我们还让注释者为其生成的每个答案提供意见标签。在这种情况下,每个答案都与一个意见标签配对(是,否或从属),以便我们可以按答案标签对答案进行分类。最后,仅针对具有相同意见标签的参考答案,通过Blue或Rouge评估预测的答案。通过使用这种能够感知意见的评估方法,可以预测自然语言中的良好答案并正确为其提供意见标签的模型将获得更高的分数。为了将答案分为不同的意见极性,我们添加了一个分类器。我们稍微更改了MatchLSTM模型,其最终指针网络层被完全连接的层代替。该分类器接受了黄金答案及其相应的意见标签的培训。我们将配备有这种观点分类器的阅读理解系统与没有阅读器的纯阅读理解系统进行了比较,结果在表中进行了说明。9.我们可以看到,在我们的评估方法下,对意见进行分类确实有帮助。同样,对于观点类型的问题,要比对事实类型的问题正确地对答案进行分类要困难得多。
4.4 讨论区
如实验所示,在我们的数据集上,当前的最新模型仍远远落后于人类。在几个方向上还有很大的改进空间。首先,我们的数据集中有一些以前尚未广泛研究的问题,例如是-否问题和需要多文档MRC的意见问题。需要新的方法来进行观点识别,跨句推理和多文档摘要。希望DuReader的丰富注释对研究这些潜在方向很有帮助。其次,我们的基准系统采用简单的段落选择策略,与黄金段落的性能相比,这会导致系统性能的大幅下降。有必要为现实的MRC问题设计一个更复杂的段落排序模型。第三,最新的模型将阅读理解作为跨度选择任务。但是,如前一部分所示,人类是实际上,他们在DuReader中以自己的理解总结答案。如何总结或产生答案值得更多的研究。第四,作为数据集的第一个版本,它还远不够完善,还有很多改进的余地。例如,我们仅对“是/否”问题注释注释,也将为述和实体问题注释注释。我们希望收集社区的反馈意见,以不断改进DuReader。总体而言,有必要提出新的算法和模型来解决现实世界中的阅读理解问题。我们希duReader将成为促进MRC研究的良好开端。
5 共同的任务
为了鼓励研究界探索更多模型,我们组织了在线竞赛6.每个参与者都可以在在线网站上提交结果并评估系统性能。自从任务发布以来,与基线相比有了重大改进,例如,一个团队在我们的数据集上(提交论文时)获得了51.2 ROUGE-L。我们的BiDAF基线模型(使用39.0 ROUGE-L)与人类绩效(使用57.4ROUGE-L)之间的差距已大大缩小。预计系统性能和人员性能之间的剩余差距将很难消除,但是这种努力将导致机器阅读理解的进步。
6 结论
本文宣布了DuReader的发布,DuReader是一个新的数据集,面向对机器阅读理解(MRC)感兴趣的研究人员。与以前的MRC数据集相比,DuReader具有三个优点:(1)数据源(基于搜索日志和问题解答社区),(2)问题类型(事实/观点和实体/描述/是/否)和(3)规模(迄今为止最大的中国MRC数据集)。我们免费提供了数据集,并组织了一场共享竞赛,以鼓励探索更多模型。自任务发布以来,我们已经看到了更复杂模型的重大改进。

- 全球主要气象气候研究部门及其共享数据集介绍
- 基于Google API的全文翻译Web Service实现
- Netty研究(一、官网文档概要介绍翻译)
- 在 Delphi 中使用微软全文翻译的小例子
- mod_python官方手册翻译-全文
- 不平衡数据集下的SVM算法研究
- 《论语》原文及其全文翻译 学而篇12
- [AS3]TweenLite用法详细说明全文中文翻译
- 腾讯AI Lab:深度解读AI辅助翻译的研究及应用
- 昆明话RAP全文翻译
- 深度解析】Google第二代深度学习引擎TensorFlow开源(CMU邢波独家点评、白皮书全文、视频翻译)
- GPL协议全文翻译
- the evolution of Lua 全文翻译
- 研究一下全文索引
- 用JSON 和 Google 实现全文翻译
- Artoolkit初级研究(文档翻译.2008.12.12)
- 【深度学习经典论文翻译2】GoogLeNet-Going Deeper with Convolutions全文翻译
- JSon SuperObject 研究2:数据集与JSON对象互转
- 全文翻译 可选7个翻译引擎
- MySQL5.7官方文档翻译: 全文索引,自然语言搜索模式