问题生成(question-generation)论文汇总
1、综述:Recent Advances in Neural Question Generation-2019地址
2、其他论文:
论文1
题目:Paragraph-level Neural Question Generation with Maxout Pointer and Gated Self-attention Networks-2018
论文地址
GIT代码实现
任务为输入段落和答案,输出生成问题

主要处理了在问题生成(Question Generation,QG)中,长文本(多为段落)在seq2seq模型中表现不佳的问题。长文本在生成高质量问题方面不可或缺。
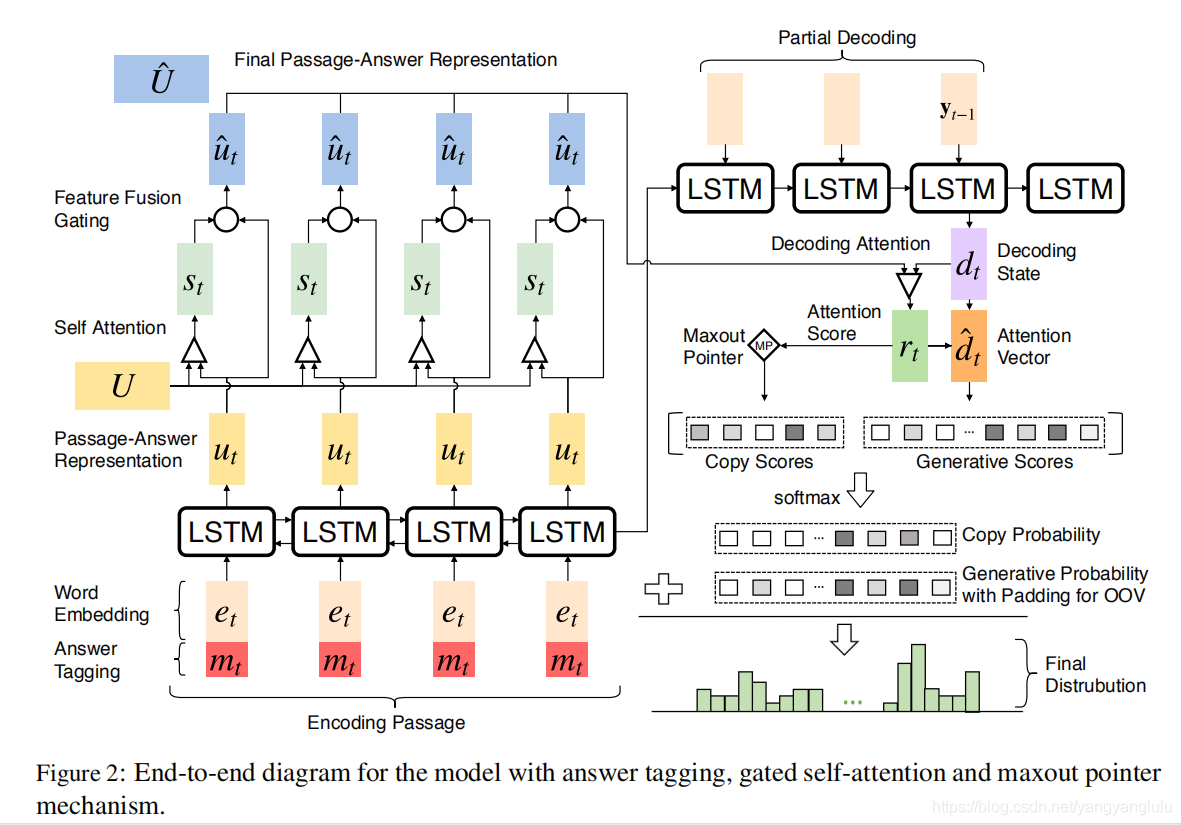
问题:在问题生成(Question Generation,QG)中,长文本(多为段落)在seq2seq模型中表现不佳。段落和答案编码 双向RNN来进行encode,
针对文章级的问题生成效果一直不佳,本文基于Seq2Seq设计了gated self-attention和Maxout Pointer两个机制来提升文章级的问题生成效果,并首次超越了句子级的问题生成。
方法:本文主要提出了一个改进的seq2seq模型,加入了maxout pointer机制和gated self-attention encoder。在之后的研究中可以通过加入更多feature或者policy gradient等强化学习的方式提升模型性能。
编码阶段:
将词向量和这个词是否在answer中两个向量拼接起来作为答案标记。
门控自注意力机制主要解决以下问题:聚合段落信息嵌入(embed)段落内部的依赖关系,在每一时间步中优化P和A的嵌入表示。
段落和答案编码双向RNN来进行encode。用300维glove词向量+answer tag。输入双向LSTM 编码
2、解码阶段
用Attention得到一个新的decoder state;
Copy/pointer+ maxout指针机制在所有指标上都优于基本复制机制。
 效果:
效果:
段落及首次高于句子集;
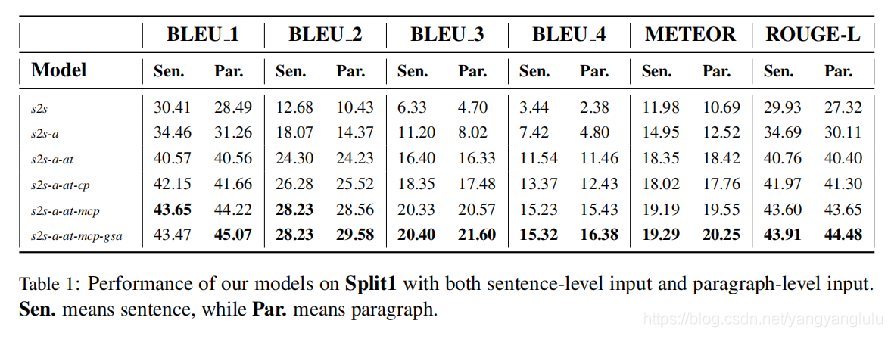
生成问题中重复单词输明显减少
 相比于其他模型有明显提升。
相比于其他模型有明显提升。
实验部分:
torch和相关包下载:https://download.pytorch.org/whl/torch_stable.html
用开源的训练方法训练,测试squad数据生成效果不错。
用中文数据集CMRC和中文词向量进行模型训练,测试生成问题,效果不好。具体原因分析为,CMRC没有squad数据量大和全面,中文词向量文件没有英文词更全面;中英文在语法和结构处理上存在差异。如何提升效果,后续更新。

- STM32CubeMX生成Keil代码时遇到的问题。project generation have a problem.**
- Mapreduce生成Hfile文件,加载到hbase问题汇总
- C#开发之问题汇总-降低NetFramework版本后,没有报错,生成失败
- MinGW gcc 生成动态链接库 dll 的一些问题汇总 (补充)
- 写论文遇到endnote重复生成列表的问题
- 生成对抗网络(GAN)的前沿进展(论文、报告、框架和Github资源)汇总
- 通过Hibernate code generation configration反向生成实体类出现的问题
- 水晶报表问题汇总(水晶报表的使用与查询条件生成报表、注册码、打印问题、模式使用示例、C#.Net的WinForm中的使用、程序发布与部署)
- 问题生成论文(question generation)-2020
- linux问题汇总---如何生成密钥对
- JMeter+ant生成自动化测试报告-遇到问题汇总
- MinGW gcc 生成动态链接库 dll 的一些问题汇总 (补充)
- MinGW gcc 生成动态链接库 dll 的一些问题汇总 (补充)
- 关于STM32CubeMX生成Keil代码时遇到的问题。project generation have a problem.
- 发论文时遇到的问题汇总
- 随机数生成问题分类以及题目汇总
- 【BMC_patrol常见问题汇总】Console License生成
- MinGW gcc 生成动态链接库 dll 的一些问题汇总(由浅入深,很详细)
- 发论文时遇到的问题汇总
- MinGW gcc 生成动态链接库 dll 的一些问题汇总