Elasticsearch:ES 的近实时到底是因为什么?一文带你读懂 ES 的 translog refresh flush 原理
文章目录
这篇文章主要介绍Elasticsearch的索引工作机制,探究它近实时查询的原因。探究它是如何利用translog来保证数据的安全,以及我们在生产环境中如何优化translog的参数来最大化性能。
主要会介绍到elastic中常见的2个操作:refresh和flush,以及这2个接口是如何保证数据能够被检索到的。
1 WAL translog 数据持久化
1.1 数据 fsync 落盘
我们把数据写到磁盘时,通常是先将数据写到操作系统的虚拟文件系统里,也既内存中,然后需要调用fsync才能把虚拟文件系统里的数据刷到磁盘中,如果不这样做在系统掉电的时候就会导致数据丢失,这个原理相信大家都清楚。
1.2 ES Write Ahead Log 日志先写
elasticsearch为了高可靠性必须把所有的修改持久化到磁盘中。
elastic底层采用的是lucene这个库来实现倒排索引的功能,在lucene的概念里每一条记录称为document(文档),lucene使用segment(分段)来存储数据,用commit point来记录所有segment的元数据。
一条记录要被搜索到,必须写入到segment中,这一点非常重要,后面会介绍为什么elastic搜索是near-realtime(接近实时的)而不是实时的。
elastic使用translog来记录所有的操作,我们称之为write-ahead-log,我们新增了一条记录时,es会把数据写到translog和in-memory buffer(内存缓存区)中,如下图所示:
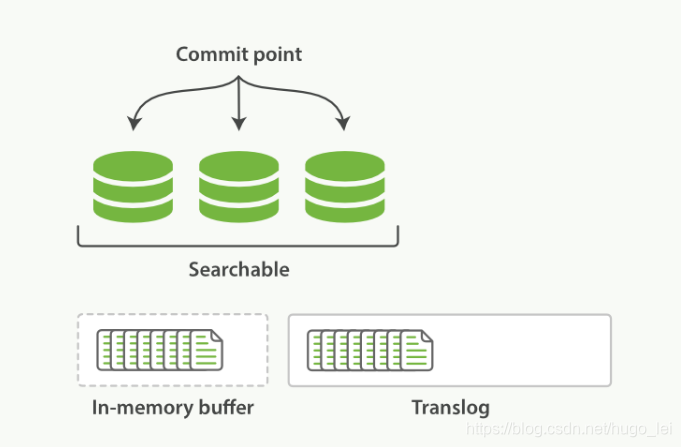
1.3 Translog顺序写
translog 是实时 fsync 的,也既写入 es 的数据,其对应的 translog 内容是实时写入磁盘的,并且是以顺序 append 文件的方式,所以写磁盘的性能很高。
只要数据写入 translog 了,就能保证其原始信息已经落盘,进一步就保证了数据的可靠性。
内存缓存区和translog就是near-realtime的关键所在,前面我们讲过新增的索引必须写入到segment后才能被搜索到,因此我们把数据写入到内存缓冲区之后并不能被搜索到,如果希望该文档能立刻被搜索,需要手动调用refresh操作。
2 refresh操作形成新segment,并写入OS虚拟文件系统,同时打开新段可被查询
默认情况下,es每隔一秒钟执行一次refresh,可以通过参数index.refresh_interval来修改这个刷新间隔,执行refresh操作具体做了哪些事情呢?
所有在内存缓冲区中的文档被写入到一个新的segment中,但是没有调用fsync,因此内存中的数据可能丢失
segment被打开使得里面的文档能够被搜索到
清空内存缓冲区
执行refresh后的状态如下图所示:
(注意:translog 在磁盘上)
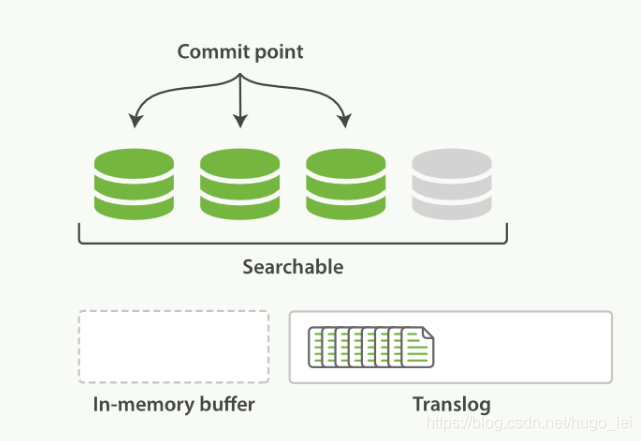
2.1 近实时的原因
因为内存缓冲区的数据,被写入 segment 文件,且 segment 文件被写入虚拟文件系统后,才能打开这个新 segment 文件,以被检索到。
因此在新 segment 文件形成之前,内存缓冲区里的数据是无法被检索到的。
而 refresh 操作,默认 1s 执行一次,也既新 insert 的 doc,默认在 1s 后才能被检索到。这就是近实时的原因。
2.2 refresh 实战
refresh的开销比较大,我在自己环境上测试10W条记录的场景下refresh一次大概要14ms,因此在批量构建索引时可以把refresh间隔设置成-1来临时关闭refresh,等到索引都提交完成之后再打开refresh,可以通过如下接口修改这个参数:
curl -XPUT 'localhost:9200/test/_settings' -d '{ "index" : { "refresh_interval" : "-1" }}'
另外当你在做批量索引时,可以考虑把副本数设置成0,因为document从主分片(primary shard)复制到从分片(replica shard)时,从分片也要执行相同的分析、索引和合并过程,这样的开销比较大,你可以在构建索引之后再开启副本,这样只需要把数据从主分片拷贝到从分片:
curl -XPUT 'localhost:9200/my_index/_settings' -d ' { "index" : { "number_of_replicas" : 0 }}'
执行完批量索引之后,把刷新间隔改回来:
curl -XPUT 'localhost:9200/my_index/_settings' -d '{ "index" : { "refresh_interval" : "1s" } }'
你还可以强制执行一次refresh以及索引分段的合并:
curl -XPOST 'localhost:9200/my_index/_refresh'curl -XPOST 'localhost:9200/my_index/_forcemerge?max_num_segments=5'
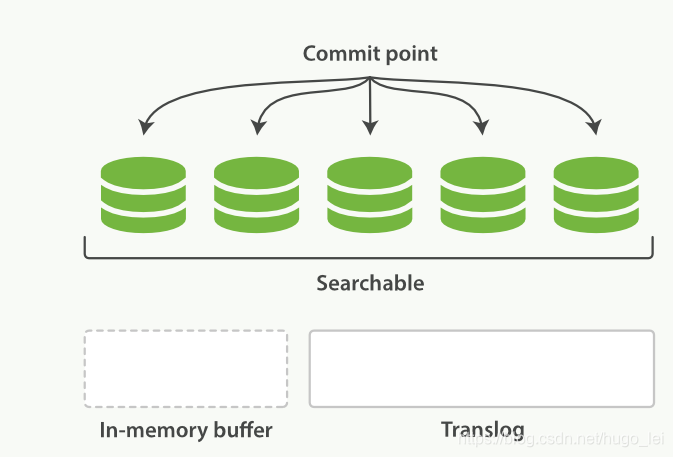
3 flush操作,清空translog,虚拟文件系统中的段文件 fsync 刷盘
随着translog文件越来越大时要考虑把内存中的数据刷新到磁盘中,这个过程称为flush,flush过程主要做了如下操作:
- 把所有在内存缓冲区中的文档写入到一个新的segment中
- 清空内存缓冲区
- 往磁盘里写入commit point信息
- 虚拟文件系统的page cache(segments) fsync到磁盘
- 删除旧的translog文件,因此此时内存中的segments已经写入到磁盘中,就不需要translog来保障数据安全了
flush之后的状态如下所示:
es有几个条件来决定是否flush到磁盘,不同版本的es参数有所不同,大家可以参考es对应版本的文档来查看这几个参数:es translog,这里介绍下1.7版本的flush参数:
index.translog.flush_threshold_ops,执行多少次操作后执行一次flush,默认无限制 index.translog.flush_threshold_size,translog的大小超过这个参数后flush,默认512mb index.translog.flush_threshold_period,多长时间强制flush一次,默认30m index.translog.interval,es多久去检测一次translog是否满足flush条件
上面的参数是es多久执行一次flush操作,在系统恢复过程中es会比较translog和segments中的数据来保证数据的完整性,为了数据安全es默认每隔5秒钟会把translog刷新(fsync)到磁盘中,也就是说系统掉电的情况下es最多会丢失5秒钟的数据,如果你对数据安全比较敏感,可以把这个间隔减小或者改为每次请求之后都把translog fsync到磁盘,但是会占用更多资源;这个间隔是通过下面2个参数来控制的:
index.translog.sync_interval 控制translog多久fsync到磁盘,最小为100ms index.translog.durability translog是每5秒钟刷新一次还是每次请求都fsync,这个参数有2个取值:request(每次请求都执行fsync,es要等translog fsync到磁盘后才会返回成功)和async(默认值,translog每隔5秒钟fsync一次)
读者需要弄清楚flush和fsync的区别,flush是把内存中的数据(包括translog和segments)都刷到磁盘,而fsync只是把translog刷新的磁盘(确保数据不丢失)。

- 还不知道什么是卷积神经网络CNN?一文读懂CNN原理附实例
- 一文读懂AlphaGo背后的强化学习:它的背景知识与贝尔曼方程的原理
- 夯实Java基础系列23:一文读懂继承、封装、多态的底层实现原理
- 超级干货 :一文读懂人工神经网络学习原理
- 10分钟读懂人工智能、机器学习到底有什么关系
- 《Single Image Haze Removal Using Dark Channel Prior》一文中图像去雾算法的原理、实现、效果(速度可实时)
- ES 18 - (底层原理) Elasticsearch写入索引数据的过程 以及优化写入过程
- Python tensorflow实战3.神经网络 - 理解到底什么是神经网络,编程原理
- 量子通信,到底是什么工作原理?
- 《Single Image Haze Removal Using Dark Channel Prior》一文中图像去雾算法的原理、实现、效果(速度可实时)
- 【Java基本功】一文读懂String及其包装类的实现原理
- elasticsearch(10) es内核:写入原理
- 独家 | 一文读懂LinkedIn个性化推荐模型及建模原理
- Elasticsearch概述、ES概念、什么是搜索、全文检索、Elasticsearch功能(来自网络+学习资料)
- 一文读懂Socket通信原理
- 一文读懂什么是进程、线程、协程
- 一文读懂无线充电技术(附方案选型及原理分析)
- JavaScript:到底什么是 ES6、ES8、ES 2017、ECMAScript?