面试一点都不难:Redis Cluster 模式分析,哈希槽,Cluster 模式高可用, 一致性,客户端 JedisPool,集群扩容
文章目录
- 1 Cluster 模式与主从模式的区别
- 2 Cluster 模式下节点数据的划分
- 3 Cluster 模式至少需要三个主节点
- 4 Cluster 模式集群高可用
- 5 Cluster 模式下单 key 的操作
- 5.1 简单客户端 redis-cli 下操作
- 5.1.1 为什么是 client执行redirect,而不是server帮忙将操作转发到正确的节点?
1 Cluster 模式与主从模式的区别
- 主从模式里,主/从节点包含全量缓存数据(数据量大时会遇到扩展瓶颈)
- 集群 cluster模式中,全量缓存数据分散在多个节点上,也既每个节点只包含全量缓存数据的一部分。
2 Cluster 模式下节点数据的划分
依据哈希槽进行数据划分。
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定key 对应哪个槽。
例如当前集群有3个节点,那么:
- 节点 A 包含 0 到 5500号哈希槽
- 节点 B 包含5501 到 11000 号哈希槽
- 节点 C 包含11001 到16384号哈希槽
3 Cluster 模式至少需要三个主节点
- 因为 Cluster 模式是基于Gossip 协议来同步集群状态的,完全的去中心化模式。
- 因此为了达成集群状态的一致性,需要遵从“大多数”原则(例如某个节点突然连不上了,只有大多数节点都认为连不上了才是真的连不上了)
- 因此至少需要 3 节点 在分布式投票场景下,3 节点集群可容忍一个节点挂点
- redis有个配置cluster-require-full-coverage=no 时,即使一个主节点挂掉,其他主节点还是能提供服务(=yes则只要一个主节点挂掉则集群不可用)
4 Cluster 模式集群高可用
为了保证节点的高可用,通常采用主从模式,也既每个主节点都有从节点。
因此 Cluster 模式下集群高可用,需要 3 主 3 从。
5 Cluster 模式下单 key 的操作
5.1 简单客户端 redis-cli 下操作
redis 127.0.0.1:7000> set foo bar -> Redirected to slot [12182] located at 127.0.0.1:7002 OK
- 若当前操作的 key 对应的 slot 不在当前client 连接到的节点上,集群会返回MOVED错误,并指明正确的目标节点
- 然后client 继续向正确的目标节点发送请求
5.1.1 为什么是 client执行redirect,而不是server帮忙将操作转发到正确的节点?
猜测:
若是 server 帮忙将操作转发到正确的节点:
- server 将阻塞住(因单线程处理 client 请求),后台向其他 server 转发操作并等待结果
- 整个过程涉及 4 次网络传输(与client redirect 方式的网络传输次数相同)
若是 client redirect:
- server 不阻塞,返回 redirect 指令后,继续处理其他 client 的请求
- client redirect,整个过程涉及 4次网络传输(与 server 转发操作次数一样)
相比之下,还是 client redirect 更实惠。
5.2 Java JedisPool 下的操作
简单客户端 redis-cli 模式下有个问题,无法提前知道当前 key 对应的 slot 具体是在哪个节点,因此会产生很多 redirect。
JedisPool 是个 Java redis 连接池,它会缓存<slot, 节点>的对应关系,因此执行操作时,先计算 key 对应的 slot,再找到 slot 对应的节点。
6 Cluster 模式下multi keys 的操作
因多个 key 可能对应多个 slot,进而多个 slot 分布在不同的节点上,因此 Cluster 模式通常不支持 multi keys 相关操作。
// 以 Java Redis 客户端 Jedis 为例:
// 对于 multi keys,要求所有的 key 都对应同一个 slot 才能执行(这个限制更严格,更宽松一点的限制是:可以对应多个 slot,但这些slot 都在一个节点上)
if (keys.length > 1) {
int slot = JedisClusterCRC16.getSlot(keys[0]);
for (int i = 1; i < keyCount; i++) {
int nextSlot = JedisClusterCRC16.getSlot(keys[i]); // 计算key对应的 slot
if (slot != nextSlot) { // slot 不一致则抛异常
throw new JedisClusterException("No way to dispatch this command to Redis Cluster "
+ "because keys have different slots.");
}
}
}
6.2 使用 hash tag 控制key 对应的 slot
在有些场景下,我们希望多个 key 都在一个节点上,如何控制呢?
- redis 提供 key 的hash tag
- {hash tag}key value
- 若有key 有 hash tag,则在计算CRC16 时使用的是 hash tag,而不是具体的 key
- 因此若想多个 key 在同一个节点上(同一个 slot),可以让多个key 使用相同的 hash tag
7 非强一致性
原因:
- 主从同步。 是异步执行,可能出现写还未同步,但主挂了,这时候写丢失。
-
Cluster模式下出现网络分区,若主从节点正好处在不同分区,且在其中一个分区从节点被选为主,此时可能原主节点的部分写操作因网络分区还未同步到从。
假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点。 其中 A 、B 、C 为主节点, A1 、B1 、C1 为A,B,C的从节点。 还有一个客户端 Z1 。 假设集群中发生网络分区,那么集群可能会分为两方, 大部分的一方包含节点 A 、C 、A1 、B1 和 C1 , 小部分的一方则包含节点 B 和客户端 Z1 。 Z1仍然能够向主节点B中写入, 如果网络分区发生时间较短,那么集群将会继续正常运作, 如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了。
8 Cluster 集群扩缩容/重新分片
添加节点,删除节点,重新分片,本质上都是一类操作:slot 迁移。
例如新加入节点,则将其他节点上的部分 slot 分配给新节点。
Cluster 模式下,数据迁移的基本单位是 slot。
8.1 slot 迁移
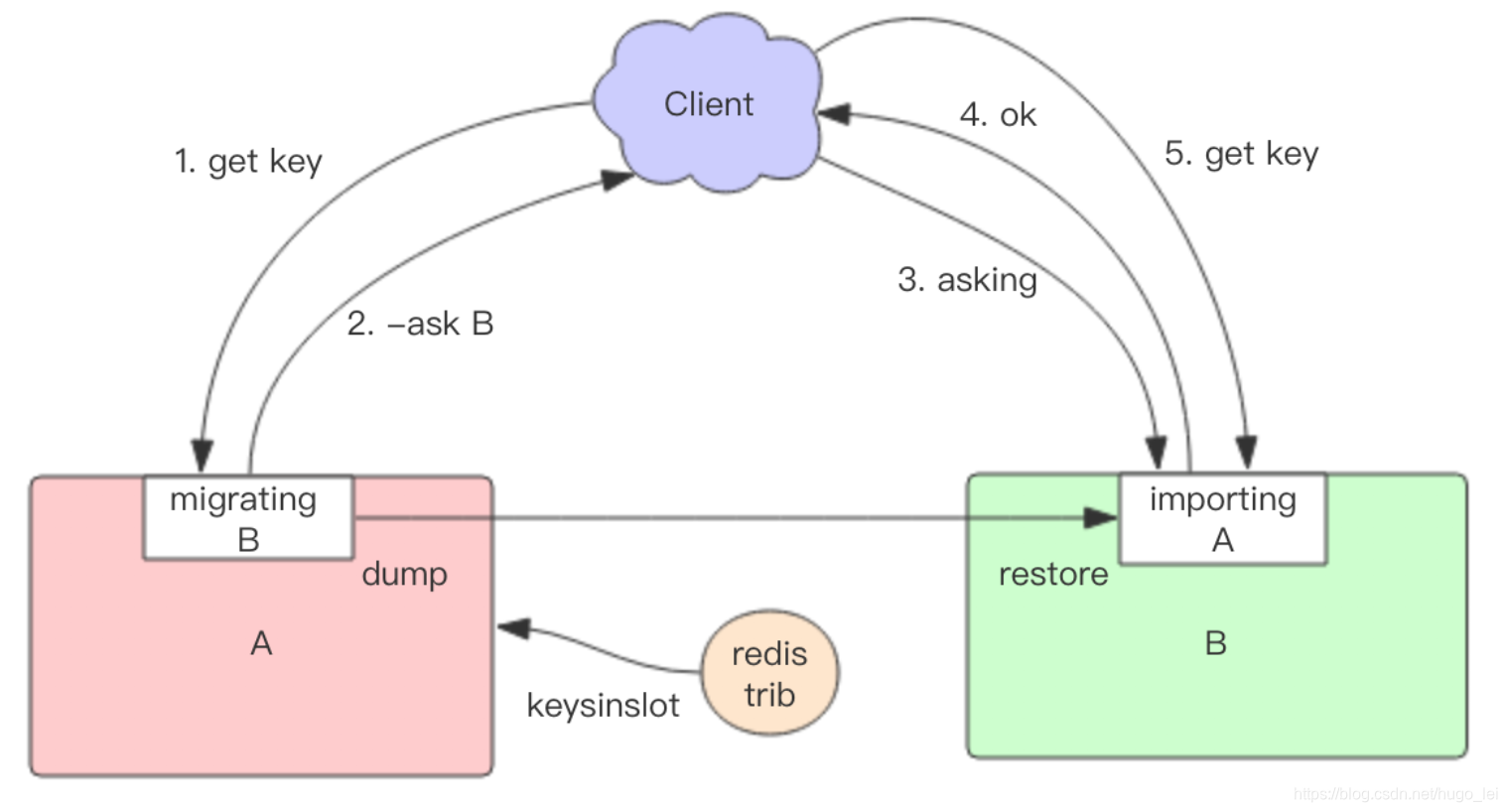
slot 迁移步骤:
- 标识 slot 为中间过渡状态(如上图,从节点 A 迁出,则 A 上标slot 为 migrating 状态,迁入到节点 B,则 B上标记 slot 为 importing 状态)
- 按照 slot 里的 key 逐个迁移,同步阻塞迁移 A 将 slot 里某个 key发送给 B
- B 收到数据后存入本地,回复 OK
- A 收到回复 OK 后,删除本地 key
8.2 slot 迁移过程中 client 的请求处理
因 slot 迁移过程中,该 slot 里的 key 部分在 A 节点,部分在 B 节点,因此 client 的请求处理会发生很大变化。
- client 先访问 slot 对应的旧节点
- 若数据还在旧节点,则旧节点正常处理
- 若数据已经不在旧节点了,旧节点向 client 返回ask B 重定向令
- client 先执行 ask B
- client 再执行 get 操作
为何重定向时不能直接用 get,而是先发一个 ask指令?
因为此时该slot还不属于节点 B(还是属于节点 A),直接发 get 命令,B 会把 client 重定向到 A,造成循环重定向

- redis知识盘点【伍】_一致性哈希和cluster集群
- 分布式缓存技术redis学习系列(五)——spring-data-redis与JedisPool的区别、使用ShardedJedisPool与spring集成的实现及一致性哈希分析
- redis集群客户端JedisCluster优化 - 管道(pipeline)模式支持
- redis集群客户端JedisCluster优化 - 管道(pipeline)模式支持
- 分布式缓存技术redis学习系列(五)——spring-data-redis与JedisPool的区别、使用ShardedJedisPool与spring集成的实现及一致性哈希分析
- redis高可用高并发集群解决方案之cluster集群_一点课堂(多岸学院)
- spring-data-redis与JedisPool的区别、使用ShardedJedisPool与spring集成的实现及一致性哈希分析
- redis集群客户端JedisCluster优化 - 管道(pipeline)模式支持
- 分布式缓存技术redis学习系列(五)——spring-data-redis与JedisPool的区别、使用ShardedJedisPool与spring集成的实现及一致性哈希分析
- Redis 学习笔记(十五)Redis Cluster 集群扩容与收缩
- Redis高可用集群-哨兵模式(Redis-Sentinel)搭建配置教程【Windows环境】
- Redis集群环境搭建-cluster模式
- Redis集群的高可用测试(含Jedis客户端的使用)
- 基于ubuntu搭建Redis(4.0) Cluster 高可用(HA)集群环境
- Redis Cluster搭建高可用Redis服务器集群
- 搭建高可用的redis集群,避免standalone模式带给你的苦难
- Redis 学习笔记(十五)Redis Cluster 集群扩容与收缩
- libmemcached一致性hash算法详解(1)----php-memcached客户端一致性哈希与crc算法共用产生的bug分析
- Redis集群(哨兵模式高可用)
- Redis进阶实践之十二 Redis的Cluster集群动态扩容