MongoDB之中级命令语句
MongoDB之中级命令语句
一.MongoDB文档显示限制
如果你需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,limit()方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数。
语法db.COLLECTION_NAME.find().limit(NUMBER)实例
首先查看文档全部信息
db.library.find()

这里实操只显示5行
db.library.find().limit(5)

二.MongoDB文档显示跳过
我们除了可以使用limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。
语法db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)实例
首先查看文档全部信息
db.library.find()
实操1:跳过前面6行
db.library.find().skip(6)

实操2:只显示6行,跳过前3行
db.library.find().limit(6).skip(3)

三.MongoDB排序
在 MongoDB 中使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
语法db.COLLECTION_NAME.find().sort({KEY:1})
实例
以likes为条件进行降序排列
db.library.find().sort({"likes":-1})

四.MongoDB索引
- 索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
- 这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
- 索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
语法中 Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。
db.collection.createIndex(keys, options)实例
让name成为key并升序索引
db.library.createIndex({"name":1})
查看集合中的所有索引
db.library.getIndexes()
因为在插入文档的时候id是自动插入的,同时他自动创建了以id为key的索引,所以此处第一个索引是id,第二个才是刚才创建的name,如果未指定索引的名称,MongoDB会通过连接索引的字段名和排序顺序生成一个索引名称。如下_id_ 和 name_1

删除集合所有索引
db.col.dropIndexes()
删除集合指定索引
db.col.dropIndex("INDEX_NAME")
五.MongoDB聚合
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
语法db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)实例
实现各个作者著作数量统计
首先查看集合中的文档信息
db.library.find()

统计作者著作数量
db.library.aggregate([{$group : {_id : "$name", total_books : {$sum : 1}}}])

以上实例类似sql语句:
select name, count(*) from library group by name
在上面的例子中,我们通过字段 name 字段对数据进行分组,并计算 name 字段相同值的总和。
1.下表展示了一些聚合的表达式:

输出结果分别是:
$sum
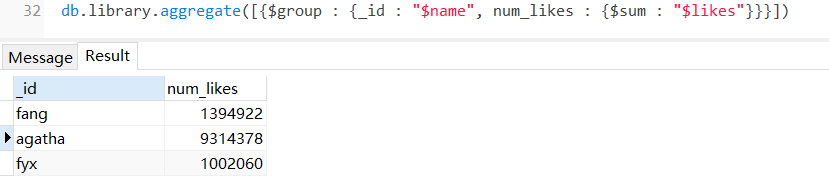
$avg

$min
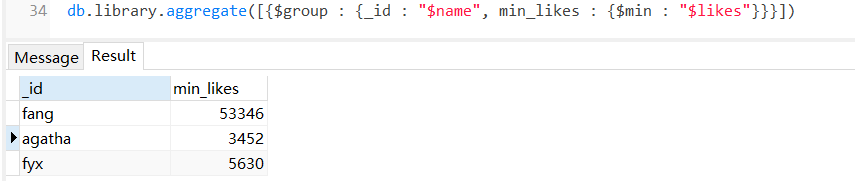
$max

$push

$addToSet

$first

$last

2.管道的概念
- 管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
- MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
- 表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:

1)暂时重命名
db.library.aggregate({$project:{_id:0,BOOK_ID:"$BID",writer:"$name",book:1,likes:1}})
可对比暂时重命名并且不看默认id的表格与原表格


2)将某一列数据小写化 &toLower
首先看原集合数据:可以看到是s16 与 s17 是有大写数据存在的
db.score1.find()

下面进行小写化,这里将小写后的name列改名为lower_name,将小写后的subject列改名为lower_subject,并同时显示原name列和原subject列
db.score1.aggregate({
$project:{
"lower_name":{$toLower:"$name"},
"lower_subject":{$toLower:"$subject"},
sid:1,_id:0,name:1,subject:1,score:1}
})

3)将某一列数据大写化 &toUpper
db.score1.aggregate({
$project:{
"upper_name":{$toUpper:"$name"},
"upper_subject":{$toUpper:"$subject"},
sid:1,_id:0,name:1,subject:1,score:1}
})

4)集合中多列的字符串合并输出 $concat
由于是字符串无法用+号相加,如果想要将字符串合在一起则需要concat
下面将subject列与name列相合用 - 链接,并给定列名为subject-name,
db.score1.aggregate({
$project:{
"subject-name":{$concat:["$subject","-","$name"]},
sid:1,_id:0,score:1}
})

5)数据与指定数据比较 $cmp
原理:将数据与指定数据相比,若大于指定数据返回的是1,若小于指定数据则返回-1,若相等则返回0
这里将score列的数据与70做比较,将结果列命名为compare-result
db.score1.aggregate({
$project:{
"compare_result":{$cmp:["$score",70]},
sid:1,_id:0,subject:1,score:1,name:1}
})

6)子字符串 $substr
子字符串的内容来源于被拆分的字符串,所有的子字符串和拆分符号(也可以是字符串)可以共同组成被拆分的字符串,子字符串以index编号,首字母index为0,依次类推,如python,p–0,y–1,t–2,h–3,o–4,n–5.假设python只需要tho输出,则伪语法为(2,3),代表从2号index开始,只取3位
下面实现将subject列只显示从第2个字符(index为1)开始只取3位命名为subject_substring,为了做对比,在此显示原subject列
db.score1.aggregate({
$project:{
"subject_substring":{$substr:["$subject",1,3]},
sid:1,_id:0,subject:1,score:1,name:1}
})

原集合内容

要求:查找大于2000小于等于40000的赞的文章并统计其数量
db.library.aggregate( [
{ $match : { likes : { $gt : 2000, $lte : 40000 } } },
{ $group: { _id: null, count: { $sum: 1 } } }
] );
$ match用于获取赞大于2000小于或等于40000的记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理


- MongoDB之初级命令语句
- mongodb篇二:mongodb克隆远程数据库,去重查询的命令及对应java语句
- MongoDB常用命令汇总之语句块操作。
- MongoDB增删改查命令操作
- Mongodb启动命令mongod参数说明
- shell printf命令:格式化输出语句
- php的pecl命令安装 mongodb模块的报错解决办法
- MongoDB常用的操作命令详解
- mongodb 查询语句
- mongodb常用语句(一)
- mongodb基本命令
- MongoDB常用命令
- MongoDB经典入门(2)--shell命令
- Sql语句命令大全
- MongoDB 常用命令
- 【Mongodb】---基本命令
- 【转】MongoDB常用语句
- mongodb关键指标查看及常规统计命令
- 给大家说明。常用sqlserver 语句命令
- mongodb主从设置,capped collections等常用命令集合