【机器学习】sklearn数据特征预处理:归一化和标准化
2020-07-07 15:52
197 查看
归一化处理
特点:通过对原始数据进行变换把数据映射到(默认为[0,1])之间
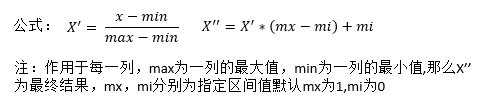
from sklearn.preprocessing import MinMaxScaler def mm(): """ 归一化处理 :return: NOne """ mm = MinMaxScaler(feature_range=(2,3)) data = mm.fit_transform([[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]]) print(data) return None if __name__ == "__main__": mm()
运行结果:
D:\softwares\anaconda3\python.exe D:/PycharmProjects/MyTest/Day_0707/__init__.py [[3. 2. 2. 2. ] [2. 3. 3. 2.83333333] [2.5 2.5 2.6 3. ]] Process finished with exit code 0
归一化目的:使得一个特征对结果不会造成更大的影响。
归一化缺点:注意在特定场景下最大最小值是变化的,最大最小值容易受异常点影响,鲁棒性差,只适合传统精确小数据场景。
标准化
1、特点:通过对原始数据进行变换把数据变换到均值为0,方差为1范围内

对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然
会发生改变
对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对
于平均值的影响并不大,从而方差改变较小。
from sklearn.preprocessing import StandardScaler def stand(): """ 标准化缩放 :return: """ std = StandardScaler() data = std.fit_transform([[ 1., -1., 3.],[ 2., 4., 2.],[ 4., 6., -1.]]) print(data) return None if __name__ == "__main__": stand()
运行结果
D:\softwares\anaconda3\python.exe D:/PycharmProjects/MyTest/Day_0707/__init__.py [[-1.06904497 -1.35873244 0.98058068] [-0.26726124 0.33968311 0.39223227] [ 1.33630621 1.01904933 -1.37281295]] Process finished with exit code 0

相关文章推荐
- 机器学习:数据特征预处理(归一化以及标准化对比)
- 【机器学习】特征数据预处理-标准化和归一化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 【原】关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- spark 数据预处理 特征标准化 归一化模块
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- sklearn中的数据预处理——标准化\最小-最大规范化\特征标签二值化\异常值\标签编码等
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- sklearn进行数据预处理-归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- sklearn数据预处理之标准化和归一化 学习笔记
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化