域自适应——Bidirectional Learning for Domain Adaptation of Semantic Segmentation
**
论文题目:Bidirectional Learning for Domain Adaptation of Semantic Segmentation
**
本文的域位移是针对虚拟数据和真实数据之间的。
本文的贡献是:(1)提出了一种语义分割的双向学习系统,它是一个学习分割适应模型和图像翻译模型的闭环学习系统。(2)对于语义分割,提出了一种基于图像翻译结果的自监督学习算法,该算法在特征层次上逐步调整目标域和源域。(3)在图像到图像的翻译中引入了感知损失,通过更新分割自适应模型来监督图像翻译的过程。
方法
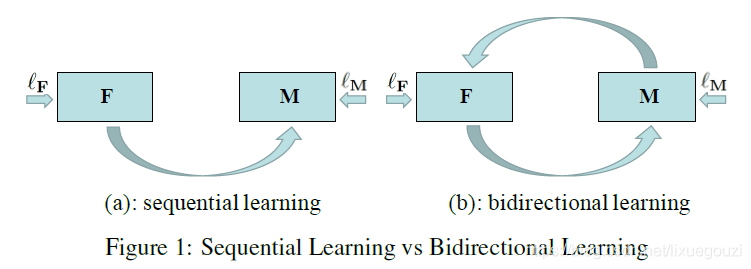
一 模型
1.双向学习
我们的学习过程如图1(b)。F是在没有成对的例子的情况下,学习将图像从S域转换成T域。T是在F(S)上训练的分割网络。S有标签,T没有标签。
(1)前向过程是用F翻译的结果图像分F(S)和T来训练M,F(S)的标签还是S的标签。M的LOSS函数为:
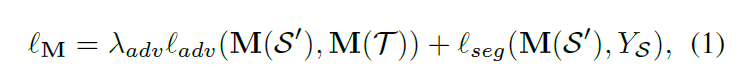
前一项是对抗损失,后一项是分割损失。
(2)后向过程是本文新添加的。为了提高翻译结果的质量,在图像翻译网络中使用了一种感知损失,它测量从一个预先训练好的目标识别网络中获得的特征的距离。这里,我们用M计算特征来测量感知损失。通过加入另外两个损失:GAN损失和图像重建损失,定义学习F的损失函数为:
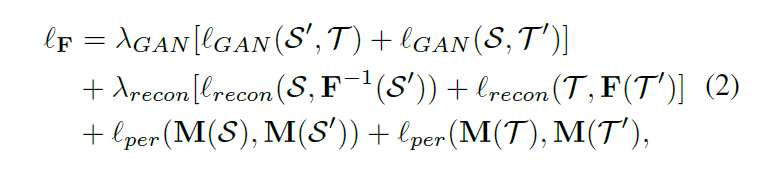 LGAN作用是强制将S’和T,S和T’的分布相似。第二项,将S’在转换为S,同理T。第三项,是感知损失,为了维持S和S’,T和T’之间的语义一致性。也就是说,一旦我们得到了一个理想的分割适应模型M, S和S ',或者T和T '应该有相同的标签,即使S和S '之间有视觉上的差距,或者T和T '之间有视觉上的差距。
LGAN作用是强制将S’和T,S和T’的分布相似。第二项,将S’在转换为S,同理T。第三项,是感知损失,为了维持S和S’,T和T’之间的语义一致性。也就是说,一旦我们得到了一个理想的分割适应模型M, S和S ',或者T和T '应该有相同的标签,即使S和S '之间有视觉上的差距,或者T和T '之间有视觉上的差距。
2 提高M的自监督学习(SSL)
我们可以预测T虚假的标签,一旦获得了,M的损失函数由(1)变为了:
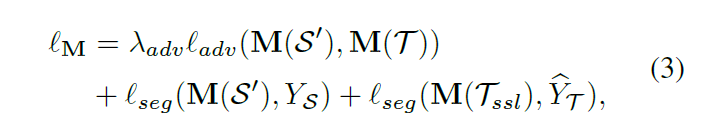
Tssl是T的子集,一开始可以是空的。当一个更好的分割适应模型M被实现时,我们可以使用M来预测更多的T的高置信度标签,导致Tssl的大小增长。最近的工作[39]也使用SSL来适应分段。相比之下,我们工作中使用的SSL与对抗性学习相结合,对抗性学习可以更好地适应分段自适应模型。
 自监督的(SSL)的过程,第一次分割域适应,Tssl先是空集,先训练F,在训练M得到Tssl的伪标签,选择T中与S对齐良好的点构成Tssl,在第二步中,我们可以很容易地将Tssl转换为S,并通过伪标签提供的分割损失来保持它们的对齐。这个过程如图2 (b)的中间所示,因此需要与S对齐的T中的数据量减少了。我们能继续剩余的数据转移到步骤1一样,见图2 (b)的右边。SSL比Ladv更容易关注T与S不对齐的每一步。
自监督的(SSL)的过程,第一次分割域适应,Tssl先是空集,先训练F,在训练M得到Tssl的伪标签,选择T中与S对齐良好的点构成Tssl,在第二步中,我们可以很容易地将Tssl转换为S,并通过伪标签提供的分割损失来保持它们的对齐。这个过程如图2 (b)的中间所示,因此需要与S对齐的T中的数据量减少了。我们能继续剩余的数据转移到步骤1一样,见图2 (b)的右边。SSL比Ladv更容易关注T与S不对齐的每一步。
3 网络和损失函数
前两个损失函数:
 感知损失连接了图像翻译模型和语义分割自适应模型。
感知损失连接了图像翻译模型和语义分割自适应模型。
 上图描述了整体的网络结构和损失函数。双向的感知损失变为:
上图描述了整体的网络结构和损失函数。双向的感知损失变为:
 第二个权重是为了保持Is与F-1(Is’)的语义一致性。
第二个权重是为了保持Is与F-1(Is’)的语义一致性。
当语义自适应模型训练的时候,我们需要对抗学习来使源域和目标域对齐,故在M中添加一个鉴别器Md,对抗损失为:

分割损失使用交叉熵损失。源域图像Is的分割损失为:
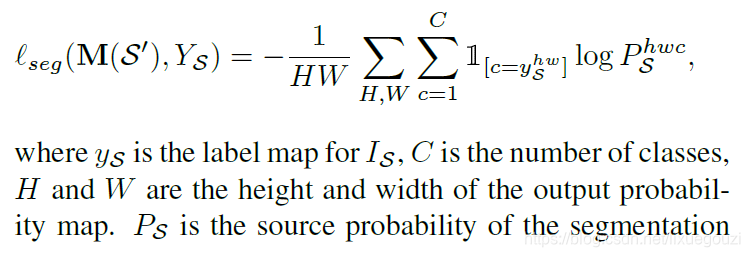 对于没有标签的目标域来说,我们使用最大可能性阈值(MPT),选取预测值中最大置信度的,成为伪标签,分割的损失函数定义为:
对于没有标签的目标域来说,我们使用最大可能性阈值(MPT),选取预测值中最大置信度的,成为伪标签,分割的损失函数定义为:
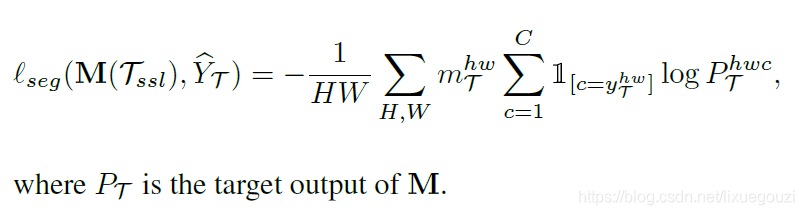 我们在算法1中给出了训练处理。训练过程由两个循环组成。外环主要是通过前向和后向学习翻译模型和分割适应模型。内部循环主要用于实现SSL流程。
我们在算法1中给出了训练处理。训练过程由两个循环组成。外环主要是通过前向和后向学习翻译模型和分割适应模型。内部循环主要用于实现SSL流程。
二 具体算法与参数选择
论文使用GTA5作为源数据集,Cityscapes作为目标数据集。翻译模型为CycleGAN,分段适应模型为DeepLab V2,主干为ResNet101。
伪标签的阈值为0.9
SSL的迭代次数为2

- Bidirectional Learning for Domain Adaptation of Semantic Segmentation详读
- 【论文阅读】Learning Semantic Representations for Unsupervised Domain Adaptation
- Unsupervised Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training
- Weakly- and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation
- MAML:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
- 深度对抗网络用于分割(语义分割)——Adversarial Learning for Semi-Supervised Semantic Segmentation
- 论文笔记:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
- Learning Deconvolution Network for Semantic Segmentation
- 语义分割--Learning Object Interactions and Descriptions for Semantic Image Segmentation
- 语义分割--DeconvNet--Learning Deconvolution Network for Semantic Segmentation
- Learning Deconvolution Network for Semantic Segmentation
- 【DeconvNet】Learning Deconvolution Network for Semantic Segmentation
- Adversarial Learning for Semi-Supervised Semantic Segmentation
- 《Fully Convolutional Adaptation Networks for Semantic Segmentation》笔记
- 语义分割--Deep Dual Learning for Semantic Image Segmentation
- Adversarial learning for semi-supervised semantic segmentation
- 笔记:Semi-supervised domain adaptation with subspace learning for visual recognition (cvpr15)
- Learning and Incorporating Shape Models for Semantic Segmentation文章理解
- Learning Deconvolution Network for Semantic Segmentation
- [IDW-CNN]Learning Object Interactions and Descriptions for Semantic Image Segmentation